开源项目丨一文详解一站式大数据平台运维管家ChengYing如何部署Hadoop集群
课件获取:关注公众号“数栈研习社”,后台私信 “ChengYing” 获得直播课件
视频回放:点击这里
ChengYing开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下海洋同学的直播分享《ChengYing部署Hadoop集群实战》
一、Hadoop集群部署准备
在部署集群前,我们需要做一些部署准备,首先我们需要按照下载Hadoop产品包:
● Mysql
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Mysql_5.7.38_centos7_x86_64.tar
● Zookeeper
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Zookeeper_3.7.0_centos7_x86_64.tar
● Hadoop
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hadoop_2.8.5_centos7_x86_64.tar
● Hive
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hive_2.3.8_centos7_x86_64.tar
● Spark
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Spark_2.1.3-6_centos7_x86_64.tar
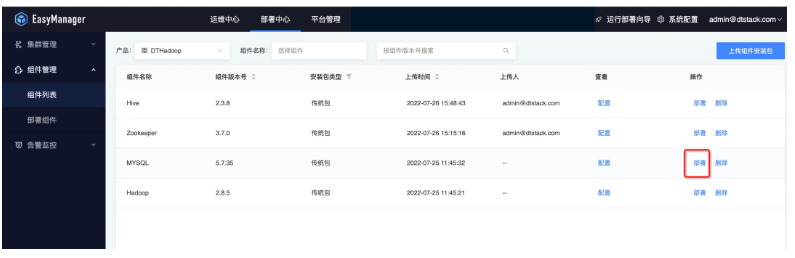
接着我们可以将下载好的产品包直接通过ChengYing界面上传,具体路径是:部署中心—组件管理—组件列表—上传组件安装包:
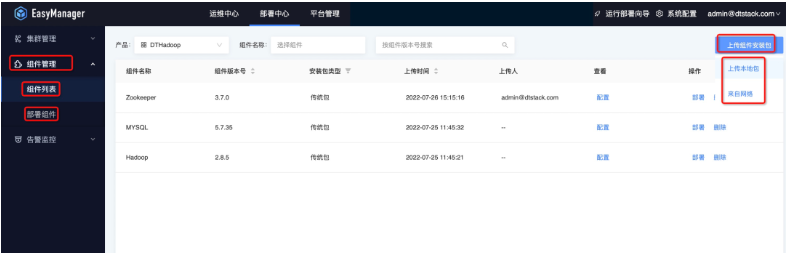
可以通过两种模式上传产品包:
本地上传方式
产品包在先下载到本机电脑存储中,点击本地上传,选在产品包上传。
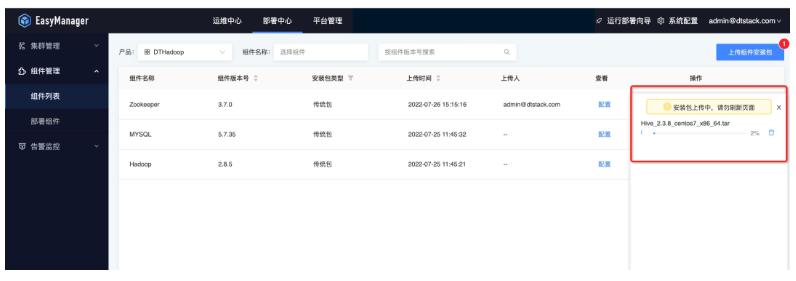
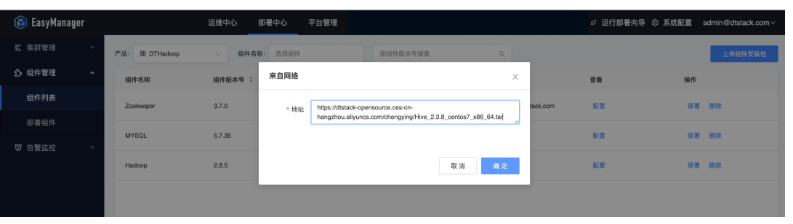
网络上传模式
直接填写产品包网络地址上传(ChengYing的网络需要和产品包网络互通)。
Hadoop集群部署流程
做完准备后,我们可以开始进入集群部署,Hadoop集群部署流程包括以下步骤:

集群部署顺序说明
首先需要部署Mysql和zookeeper,因为Hadoop需要依赖zookeeper,Hive元数据存储使用的是Mysql;
其次需要部署Hadoop,Hive
最后部署Spark,因Spark依赖hivemetastore
PS:部署顺序是不可逆的
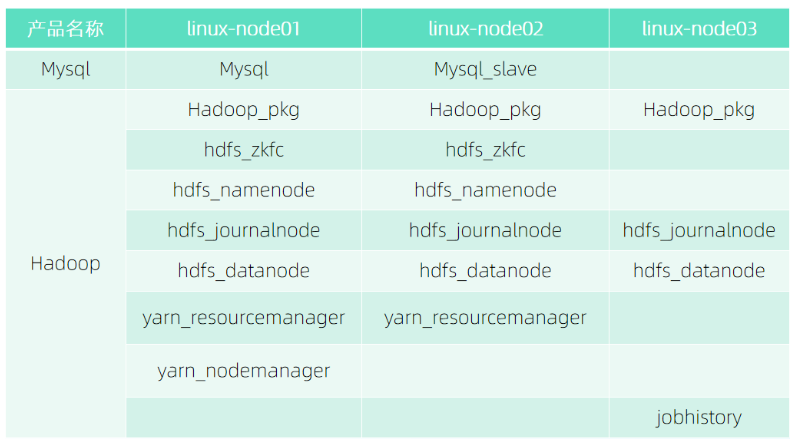
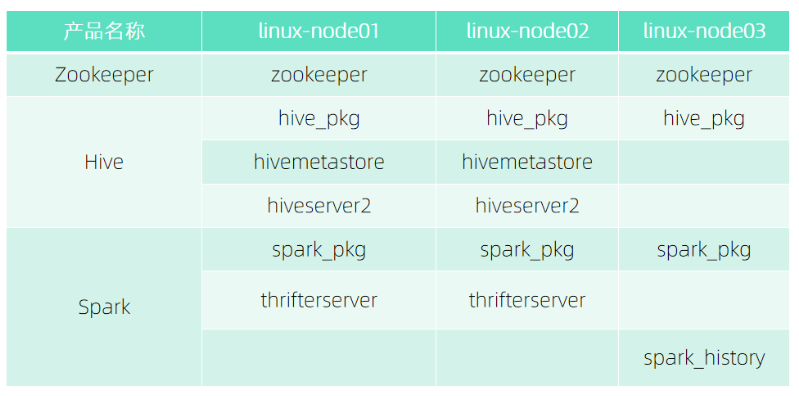
Hadoop集群部署角色分布
产品包标准部署流程

选择需要部署的产品包,点击部署按钮,然后选择对应需要部署的集群,默认集群为dtstack,集群名称可配置;
下一步选择需要部署的服务,默认产品包下的服务都会部署,可以根据实际需求部署,在此阶段可以对服务的配置文件进行修改,例如:修改Mysql连接超时时间等;
最后点击部署,等待部署完成。
Mysql服务部署流程演示
接下来我们以Mysql服务部署流程来为大家实际演示下整体流程:
● 第一步:选择集群
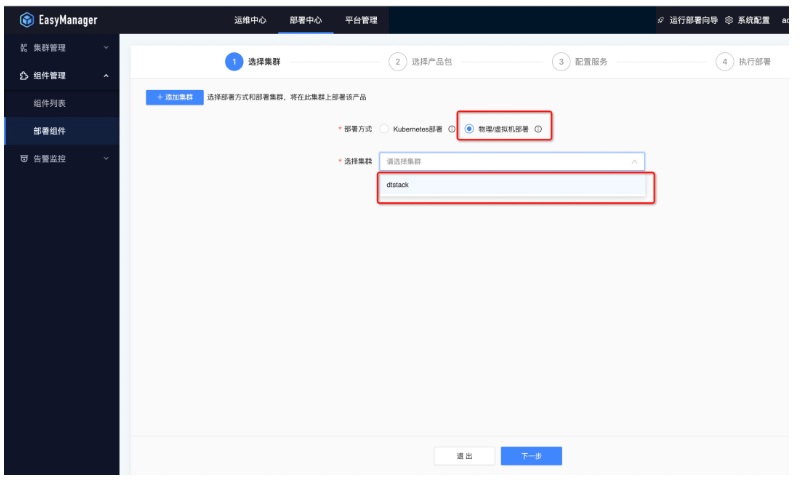
● 第二步:选择产品包
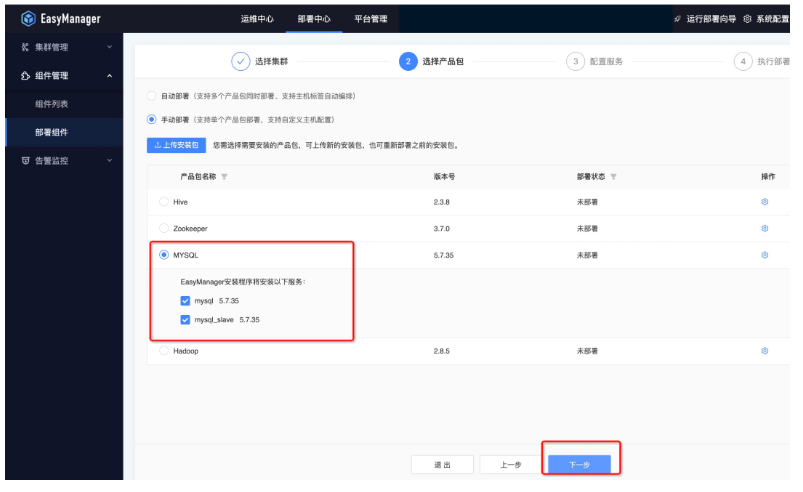
● 第三步:选择部署节点

● 第四步:部署进度查看
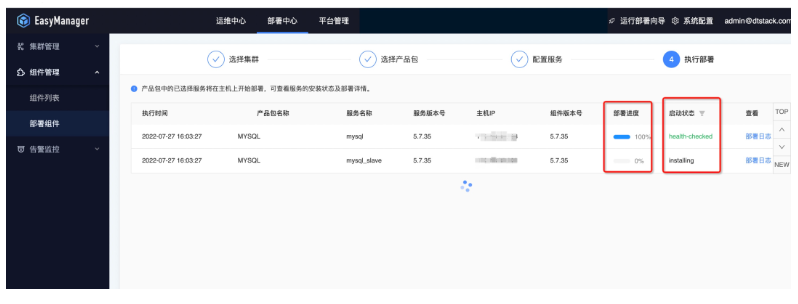
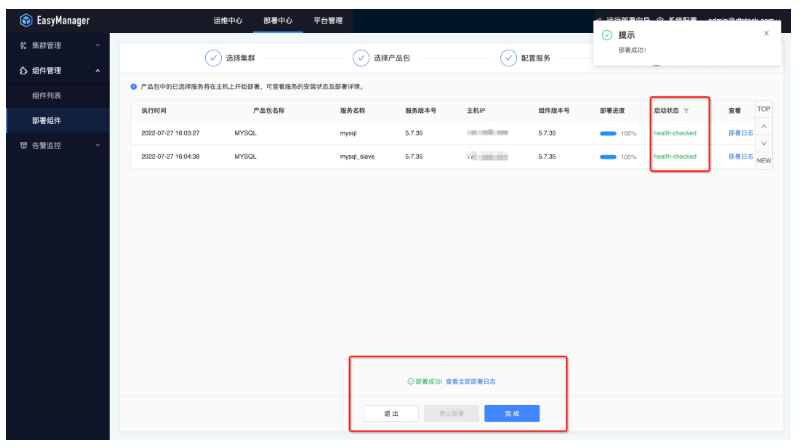
● 第五步:部署后状态查看
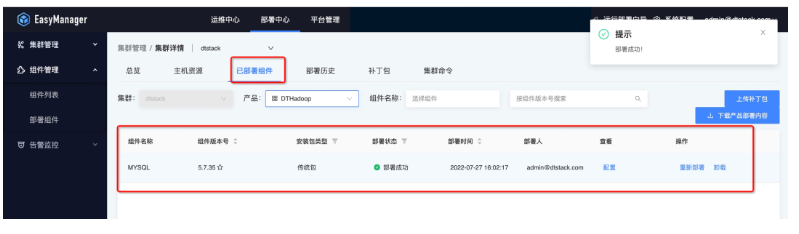
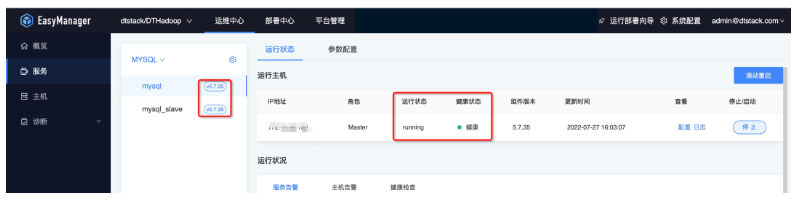
Hadoop集群使用与运维
集群部署完毕后,若有需求可以进行配置变更操作。
● 配置修改
例如:如果需要操作修改yarn的配置文件,可以先选择yarn-site.xml文件,可以在搜索框搜索需要修改的配置文件key,如cpu_vcores。
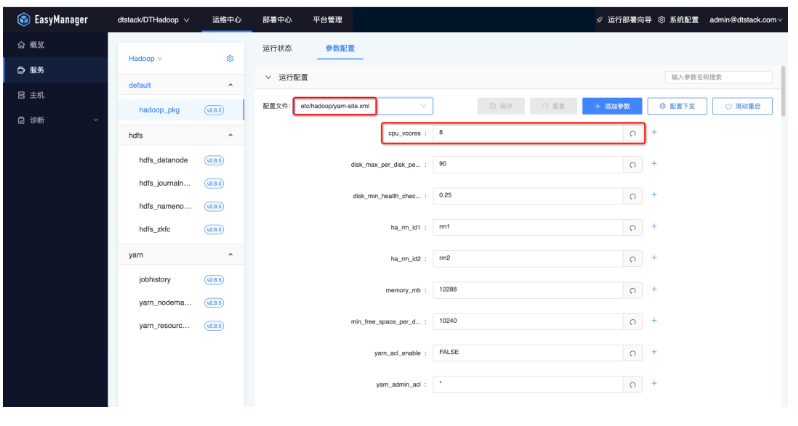
● 配置保存
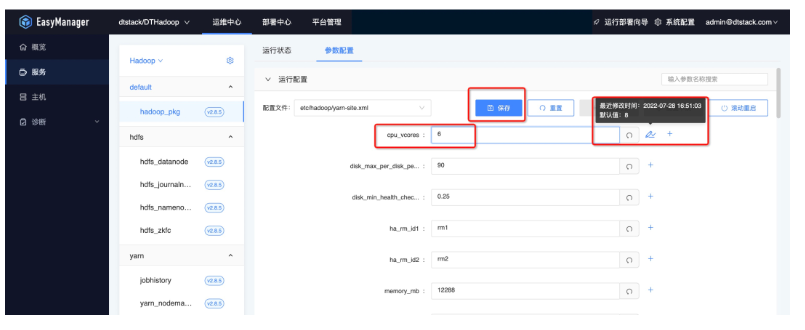
● 配置下发

Taier对接Hadoop操作流程
ChengYing除了可自动部署运维外,还可以对接Taier部署Hadoop集群,Taier 是一个大数据分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
利用ChengYing部署管理Taier服务,可以做到实时监控Taier的服务状态,随时界面修改Taier配置等。Taier对接Hadoop集群的操作流程如下:

首先需要在Taier控制台选择多集群配置,新增一个集群;
然后配置sftp、资源调度组件、存储组件和计算组件;
配置完成后需要保存并且测试连通性。
注意事项:
在对接过程中,sftp主机需要和Taier网络相通,并且sftp配置主机的路径需要存在,如果不存在,需要手动创建。
Taier的部署网络需要与Hadoop网络相通,如果运行任务,需要在Taier所在节点加入Hadoop集群的Host配置;编译/etc/hosts文件,增加IP Hostname。
● 第一步:配置公共组件
首先进入Taier登陆界面,点击控制台,新增集群,然后进入多集群管理界面,配置公共组件,选择SFTP,进入SFTP配置界面。
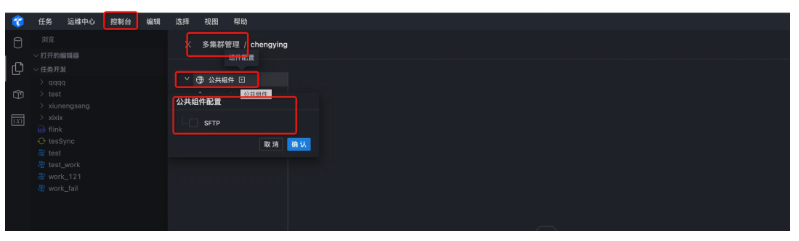
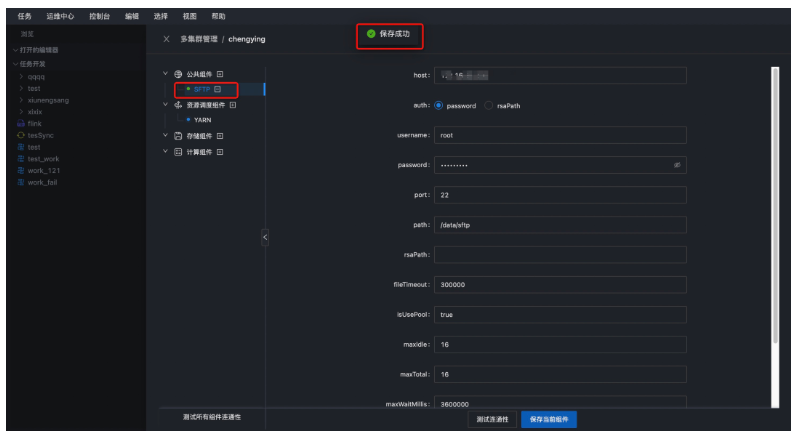
● 第二步:配置SFTP
然后配置SFTP的host,认证方式,默认采用用户名密码方式,输入用户名和密码,并且输入path路径,此路径需要在主机上存在,如果不存在,需要手动创建一个SFTP路径.
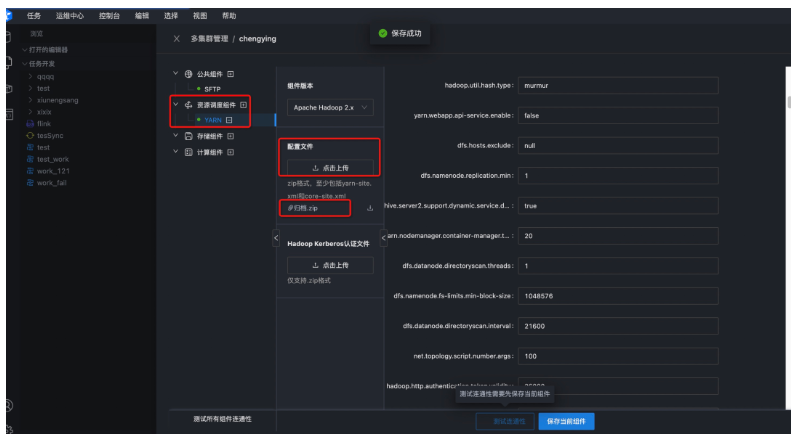
● 第三步:资源调度组件配置
需要到部署Hadoop服务器到/opt/dtstack/Hive/hive_pkg/conf目录下获取hive-site.xml文件,下载到本地;
到/opt/dtstack/Hadoop/Hadoop_pkg/etc/Hadoop目录下获取hdfs-site.xml、core-site.xml、yarn-site.xml文件,下载到本地;
这四个文件压缩成一个zip包,上传这个压缩包。
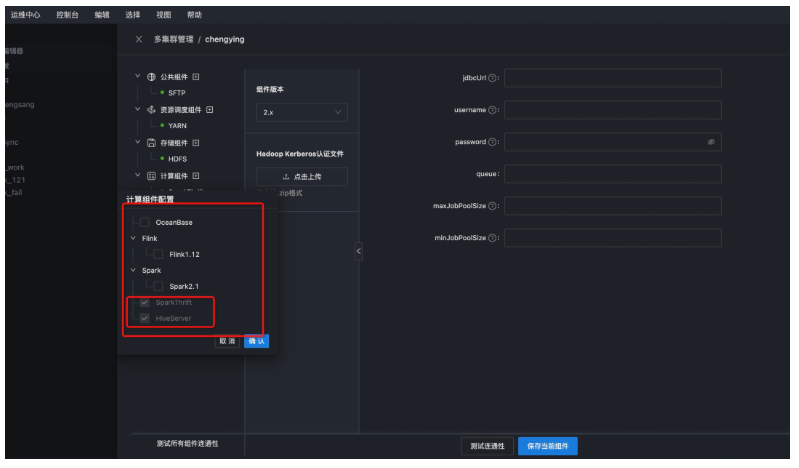
● 第四步:计算组件配置
选择计算组件模块,选择需要对接的计算引擎Hive和Spark,选择Hive和Spark的版本,填写对应的jdbc(jdbc:hive://ip:port/)连接串,然后点击保存,测试连通性。
注意:jdbcurl中ip分别为Hive组件的hiveserver2和Spark中的thrifterserver所在节点ip。
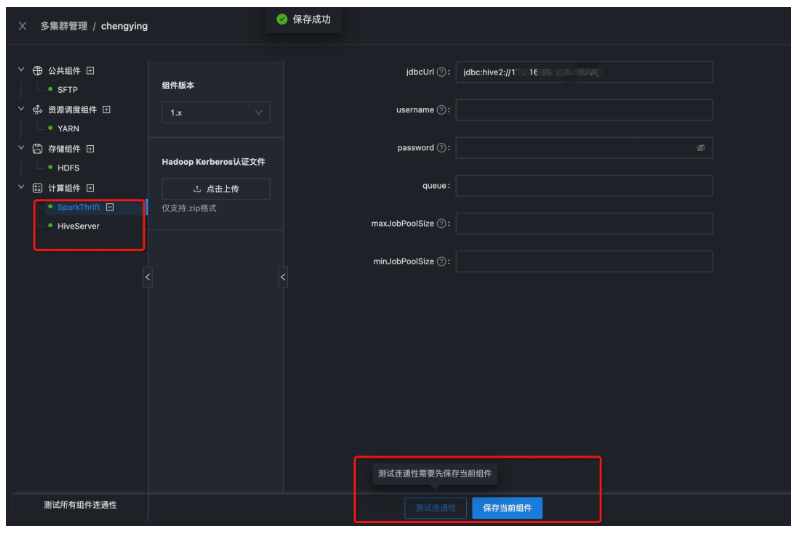
● 第五步:配置Hive和Spark
以下是配置完成Hive和Spark组件后,测试连通性的状态。
注意:本地演示环境Hadoop未开启安全,Hive和Spark只需要配置jdbcurl即可。
Hadoop集群近期规划
最后和大家聊聊Hadoop集群近期规划,近期主要有三大规划:
● 产品包制作
制作ChengYing部署产品包的流程及实践。
● ChunJun&Taier产品包
制作可以用ChengYing部署的Taier和chunjun的产品包
● Hadoop运维
通过ChengYing运维大数据集群;
通过ChengYing一键开启Hadoop集群安全。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
开源项目丨一文详解一站式大数据平台运维管家ChengYing如何部署Hadoop集群的更多相关文章
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
- Spark项目之电商用户行为分析大数据平台之(十一)JSON及FASTJSON
一.概述 JSON的全称是”JavaScript Object Notation”,意思是JavaScript对象表示法,它是一种基于文本,独立于语言的轻量级数据交换格式.XML也是一种数据交换格式, ...
- Spark项目之电商用户行为分析大数据平台之(七)数据调研--基本数据结构介绍
一.user_visit_action(Hive表) 1.1 表的结构 date:日期,代表这个用户点击行为是在哪一天发生的user_id:代表这个点击行为是哪一个用户执行的session_id :唯 ...
- Spark项目之电商用户行为分析大数据平台之(六)用户访问session分析模块介绍
一.对用户访问session进行分析 1.可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄.职业.城市): 2.对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出 ...
- Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建
一.CentOS7集群搭建 1.1 准备3台centos7的虚拟机 IP及主机名规划如下: 192.168.123.110 spark1192.168.123.111 spark2192.168.12 ...
- Spark项目之电商用户行为分析大数据平台之(一)项目介绍
一.项目概述 本项目主要用于互联网电商企业中,使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.购物行为.广告点击行为等)进行复杂的分析.用统计分析出来的数据,辅助公司中 ...
- Docker环境下的前后端分离项目部署与运维(六)搭建MySQL集群
单节点数据库的弊病 大型互联网程序用户群体庞大,所以架构必须要特殊设计 单节点的数据库无法满足性能上的要求 单节点的数据库没有冗余设计,无法满足高可用 单节点MySQL的性能瓶领颈 2016年春节微信 ...
- 开源项目 log4android 使用方式详解
话不多说, 直接上主题. log4android 是一个类似于log4j的开源android 日志记录项目. 项目基于 microlog 改编而来, 新加入了对文件输出的各种定义方式. 项目地址: 点 ...
- 【开源项目9】ImageLoaderConfiguration详解
ImageLoader类中包含了所有操作.他是一个单例,为了获取它的一个单一实例,你需要调用getInstance()方法.在使用 ImageLoader来显示图片之前,你需要初始化它的配置-Imag ...
- Spark项目之电商用户行为分析大数据平台之(十)IDEA项目搭建及工具类介绍
一.创建Maven项目 创建项目,名称为LogAnalysis 二.常用工具类 2.1 配置管理组建 ConfigurationManager.java import java.io.InputStr ...
随机推荐
- codelite常用快捷键积累
博客地址:https://www.cnblogs.com/zylyehuo/ 编译整个工作空间 workplace Ctrl+shift+B 编译当前文件 file Ctrl+F7 编译项目 proj ...
- 如何不购买域名在云服务器上搭建HTTPS服务
step 1: 事前准备 step 1.1: 云服务器 购买一台云服务器(带有弹性公网IP),阿里云,腾讯云,华为云什么的都可以. 选择ubuntu系统 开放安全组策略(把你需要的协议/端口暴露出来) ...
- 【技术分析】简单了解 AccessControl
当我们开发一个智能合约,但是里面有一些函数不能随便让别人调用,只能"拥有权限"的管理员能够调用,那么这时候我们会用到权限管理机制. 实现起来也很简单,设置一个 owner 变量,通 ...
- static修饰成员变量的特点及static修饰成员变量内存图解-java se进阶 day01
1.static介绍 static是静态的意思,它可以用于修饰成员变量和成员方法 2.static的特点 1.被static修饰了的成员变量,可以被类中的所有对象所共享 虽然stu02没有给schoo ...
- Debian 9 更换源
Debian 全球镜像站 # 先备份源列表文件 mv /etc/apt/sources.list /etc/apt/sources.list.bak # 生成新的源列表文件(用的国内源镜像) echo ...
- Visual Studio 自定义项目模版
以 Visual Studio 2017 为例. 在 Visual Studio 中用户项目模版就是我们俗称的自定义项目模版. 用户项目模版位置 在Visual Studio中打开[工具-选项-项目和 ...
- 自动驾驶 | 为CarLA添加一辆小米SU7 Part I
自动驾驶 | 为CarLA添加一辆小米SU7 Part I 导言 什么是CarLA? CarLA是一款基于虚幻引擎4(Unreal Engine 4)构建的开源自动驾驶仿真平台,为自动驾驶算法的研发. ...
- springboot将对象输出成文件流传到前端
springboot将对象输出成文件流传到前端 依赖 Controller service 运行 依赖 cn.hutool hutool-all 5.7.20 Controller /** * TIT ...
- 第五届新型功能材料国际会议(ICNFM 2025)
第五届新型功能材料国际会议(ICNFM 2025) 2025年5月16日-17日 曼谷,泰国 http://www.icnfm.net/ 会议简介 第五届新型功能材料国际会议(ICNFM 2025)将 ...
- Python科学计算系列1—方程和方程组
1.一元方程求解 例1:求下列一元二次方程的解 代码如下: # 定义数学符号 from sympy import symbols, solve x = symbols('x') f = x ** 2 ...