Flink初体验-批处理与流处理
一、环境准备
本机环境:jdk11、scala2.12、maven3.6
新建一个maven项目,pom如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>org.wzy</groupId>
<artifactId>flink-project</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.10.2</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.10.2</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.10.2</version>
</dependency> </dependencies>
<build>
<plugins> <plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
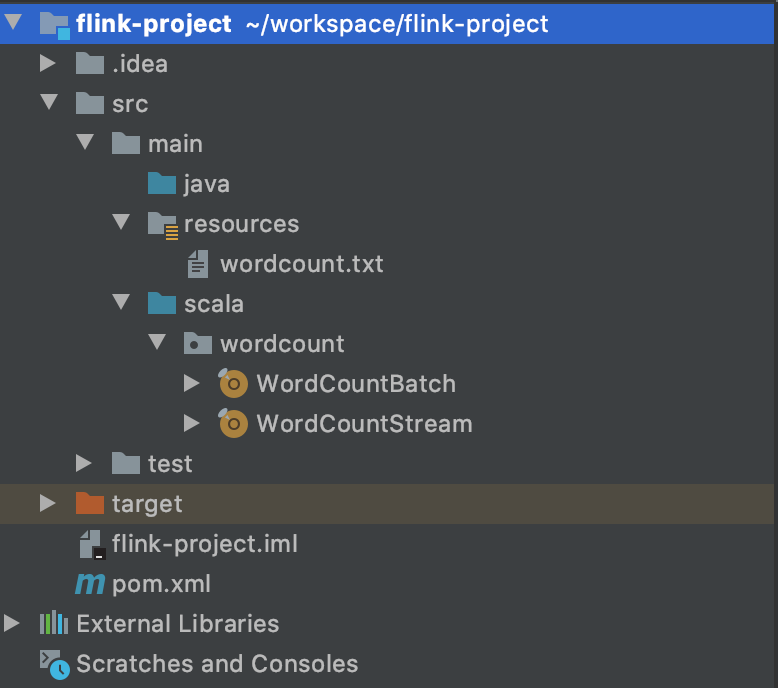
项目结构如下
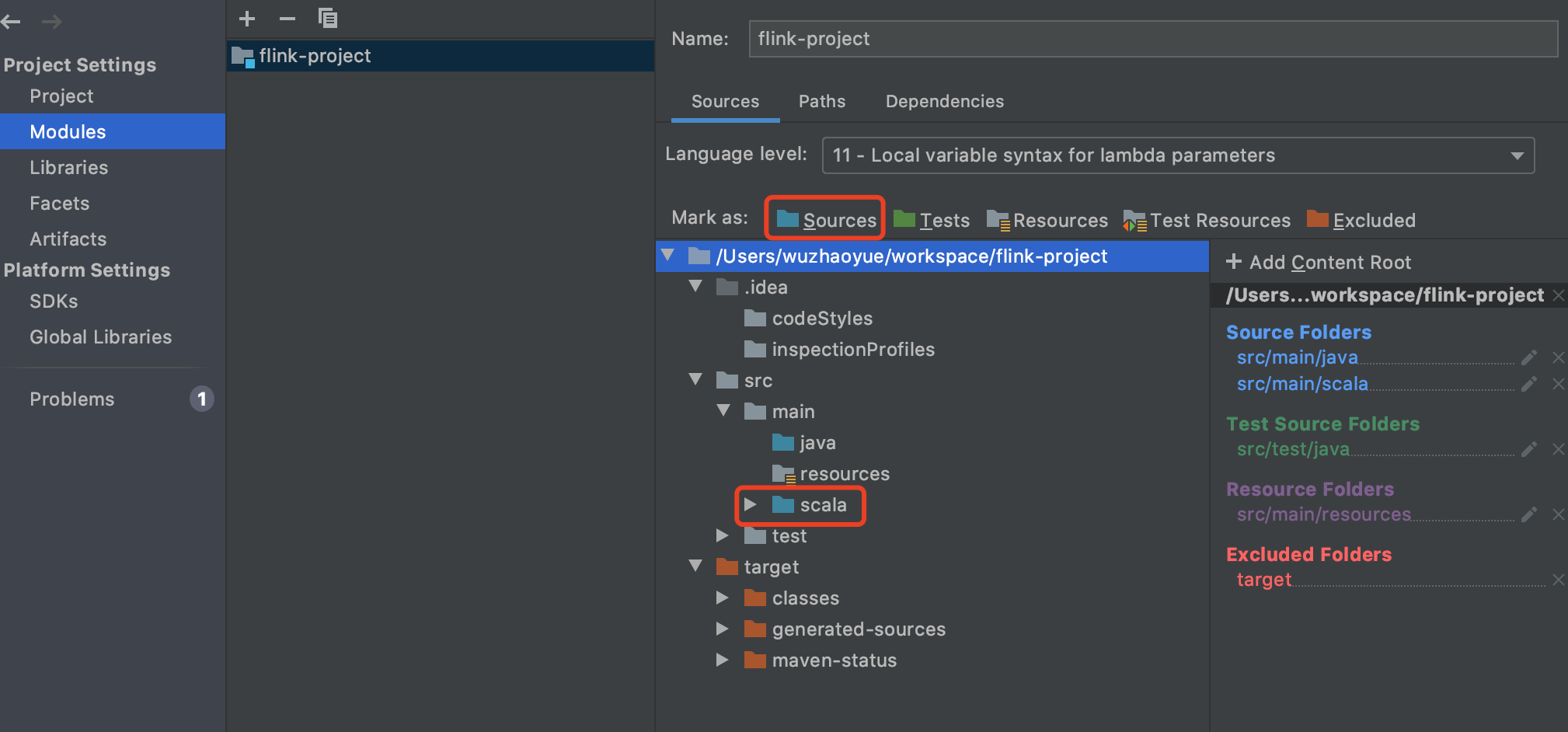
1、添加scala源文件,新建一个scala的文件夹,并把它设置成源文件。设置方法 File -> Project Structure -> Modules
2、添加scala框架支持,右键项目 -> Add Framework Support -> scala(需要提前配置上scala的sdk)
二、wordcount批处理
新建一个txt文件,让程序读取文件里内容进行单词的统计
package wordcount import org.apache.flink.api.scala._ /**
* @description 批处理
*/
object WordCountBatch { def main(args: Array[String]): Unit = {
// 创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment // 从文件中读取数据
val inputPath = "src/main/resources/wordcount.txt"
val inputDS: DataSet[String] = env.readTextFile(inputPath) // 分词之后, 对单词进行 groupby 分组, 然后用 sum 进行聚合
val wordCountDS: AggregateDataSet[(String, Int)] = inputDS
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1) // 打印输出
wordCountDS.print()
} }
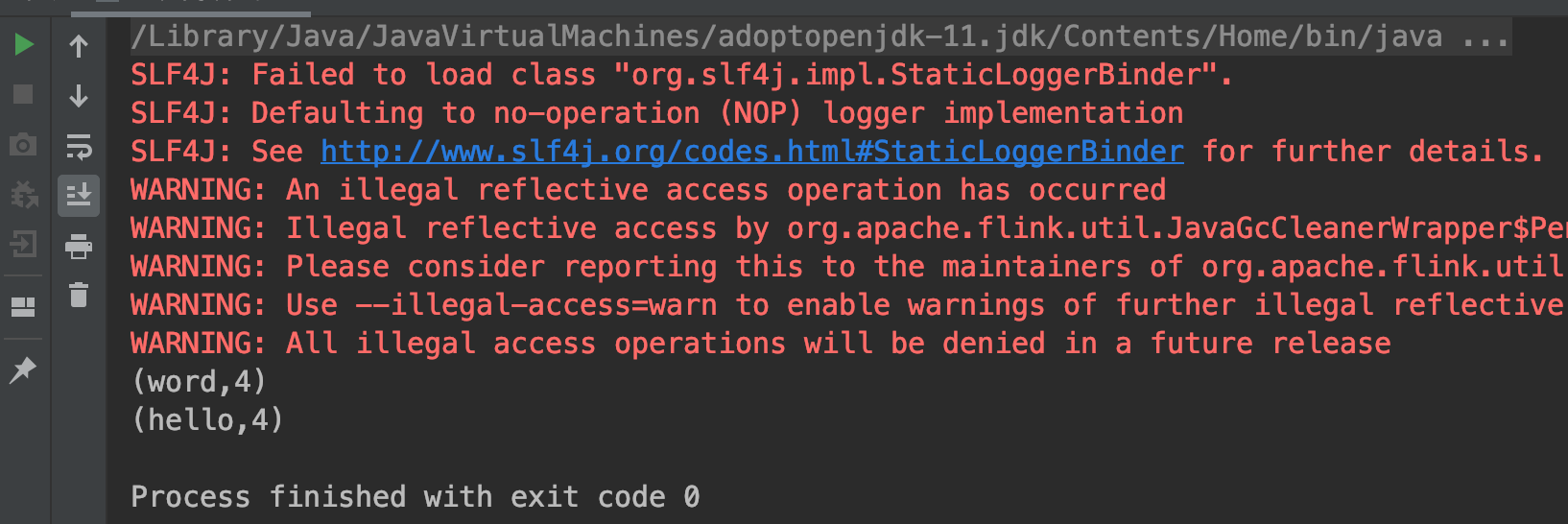
打印结果如下
三、wordcount流处理
新建一个服务端口,让程序监听端口,收到一条处理一条,结果累加
开启临时服务命令:nc -lk 8088
手动输入单词回车就会发送出去

然后程序进行端口的监听
package wordcount import org.apache.flink.streaming.api.scala._ /**
* @description 流处理
*/
object WordCountStream { def main(args: Array[String]): Unit = { val host: String = "localhost"
val port: Int = 8088 // 创建流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment // 接收 socket 文本流
val textDstream: DataStream[String] = env.socketTextStream(host, port) // flatMap 和 Map 需要引用的隐式转换
val dataStream: DataStream[(String, Int)] = textDstream
.flatMap(_.split(" "))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1) dataStream.print()
env.execute("wordcount job")
}
}
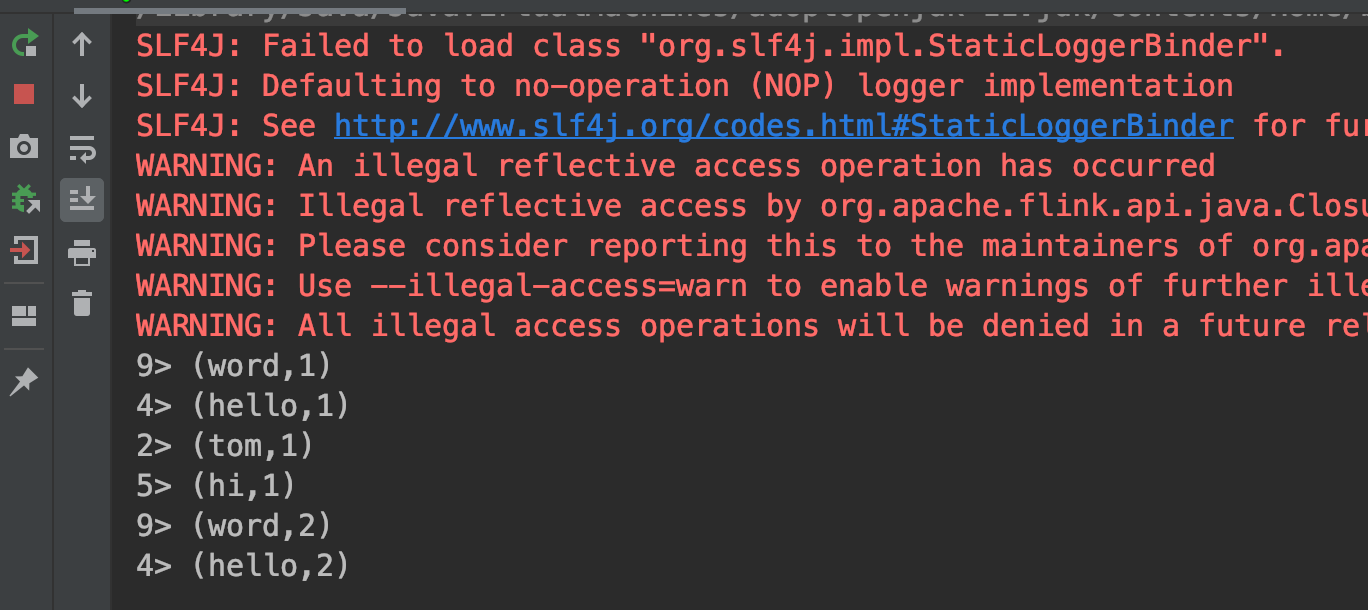
打印结果如下,可以看到结果是累加的
Flink初体验-批处理与流处理的更多相关文章
- Java高级特性1_流库_初体验
Java高级特性流库_初体验 面对结果编程 在编程里, 有两种编程方式, 一种是面对过程编程, 一种是面对结果编程. 两者区别如下 面向过程编程 面向过程编程需要编程程序让程序依次执行得到自己想要的结 ...
- Apache Beam入门及Java SDK开发初体验
1 什么是Apache Beam Apache Beam是一个开源的统一的大数据编程模型,它本身并不提供执行引擎,而是支持各种平台如GCP Dataflow.Spark.Flink等.通过Apache ...
- 【Spark深入学习 -15】Spark Streaming前奏-Kafka初体验
----本节内容------- 1.Kafka基础概念 1.1 出世背景 1.2 基本原理 1.2.1.前置知识 1.2.2.架构和原理 1.2.3.基本概念 1.2.4.kafka特点 2.Kafk ...
- 深入浅出时序数据库之预处理篇——批处理和流处理,用户可定制,但目前流行influxdb没有做
时序数据是一个写多读少的场景,对时序数据库以及数据存储方面做了论述,数据查询和聚合运算同样是时序数据库必不可少的功能之一.如何支持在秒级对上亿数据的查询分组聚合运算成为了时序数据库产品必须要面对的挑战 ...
- .NET平台开源项目速览(15)文档数据库RavenDB-介绍与初体验
不知不觉,“.NET平台开源项目速览“系列文章已经15篇了,每一篇都非常受欢迎,可能技术水平不高,但足够入门了.虽然工作很忙,但还是会抽空把自己知道的,已经平时遇到的好的开源项目分享出来.今天就给大家 ...
- Microsoft IoT Starter Kit 开发初体验
1. 引子 今年6月底,在上海举办的中国国际物联网大会上,微软中国面向中国物联网社区推出了Microsoft IoT Starter Kit ,并且免费开放1000套的申请.申请地址为:http:// ...
- win7升win10,初体验
跟宿舍哥们聊着聊着,聊到最近发布正式版的win10,听网上各种评论,吐槽,撒花的,想想,倒不如自己升级一下看看,反正不喜欢还可以还原.于是就开始了win10的初体验了,像之前装黑苹果双系统一样的兴奋, ...
- node.js 初体验
node.js 初体验 2011-10-31 22:56 by 聂微东, 174545 阅读, 118 评论, 收藏, 编辑 PS: ~ 此篇文章的进阶内容在为<Nodejs初阶之express ...
- 文档数据库RavenDB-介绍与初体验
文档数据库RavenDB-介绍与初体验 阅读目录 1.RavenDB概述与特性 2.RavenDB安装 3.C#开发初体验 4.RavenDB资源 不知不觉,“.NET平台开源项目速览“系列文章已经1 ...
- FileTable初体验
FileTable初体验 阅读导航 启用FILESTREAM设置 更改FILESTRAM设置 启用数据库非事务性访问级别 FileTable 在我接触FileTable之前,存储文件都是存储文件的链接 ...
随机推荐
- cnpack导致view快捷键失灵。
学习d10.3.出现怪问题: 卸载cnpack出现: 这下要用快捷键了.那可不烦透了. 如此就ok了. 鸡蛋好吃,还要知道母鸡如何生蛋的?
- VsCode写Markdown使用snippet
文件->首选项->用户片段 输入markdown 输入代码片段 Ctrl+P,输入settings.json 加入下面个这个选项 "[markdown]" ...
- 小了 60,500 倍,但更强;AI 的“深度诅咒”
作者:Ignacio de Gregorio 图片来自 Unsplash 的 Bahnijit Barman 几周前,我们看到 Anthropic 尝试训练 Claude 去通关宝可梦.模型是有点进展 ...
- OAuth2.0 学习
- 1678. 设计 Goal 解析器
1678. 设计 Goal 解析器 class Solution { public String interpret(String command) { char[] ch = command.toC ...
- Web前端入门第 41 问:神奇的 transform 改变元素形状,matrix3d 矩阵变换算法演示
CSS transform 属性中文翻译过来是 变换,始终觉得翻译差那么一点意思.它可以用来改变元素形状,比如旋转.缩放.移动.倾斜等,就是它可以把元素各种拿捏~ transform 特性是在不改变自 ...
- redis 中文乱码
查询数据时中文乱码 解决方法: 使用 ./redis-cli 登录的时候加上 --raw参数 ./redis-cli --raw
- 【代码】Android|获取存储权限并创建、存储文件
版本:Android 11及以上,gradle 7.0以上,Android SDK > 29 获取存储权限 获取存储权限参考:Android 11 外部存储权限适配指南及方案,这篇文章直接翻到最 ...
- 操作系统综合题之“银行家算法,计算各资源总数和Need还需要数量和解释什么是安全状态以及银行家进阶题(额外提出资源请求计算是否满足)”
一.问题:某系统在某时刻的进程和资源状态如下表所示: 进程 Allocation(已分配资源数) (A B C D) Max(最大需要资源数) (A B C D) Avaliable(可用资源数) ( ...
- Flutter适配HarmonyOS 5开发知识地图
还在为Flutter适配HarmonyOS 5头疼?这份知识地图,用实战解析+高频避坑指南,帮你快速打通跨平台开发任督二脉! ▌为什么这份资源值得你收藏? 分层进阶:从环境搭建→插件开发→性能优化,匹 ...