Apache Flink学习笔记
Apache Flink学习笔记
简介
大数据的计算引擎分为4代
第一代:Hadoop承载的MapReduce。它将计算分为两个阶段,分别为Map和Reduce。对于上层应用来说,就要想办法去拆分算法,在上层应用实现多个Job串联,完成一个完整算法。例如:迭代计算
第二代:支持DAG框架的计算引擎,如Tez以及更上层的Oozie。
第三代:Spark为代表的计算引擎。特点是Job内部的DAG支持(不跨越Job),以及强调的实时计算。
第四代:Flink对流计算的支持,也可以支持Batch任务以及DAG的运算。
需要体会各个框架的差异,以及更适合的场景。并进行理解,没有哪一个框架可以完美的支持所有的场景,也就不可能有任何一个框架能够完全取代另一个。就像Spark没有取代Hadoop,Flink也不可能取代Spark。
Flink是一个针对流数据和批数据的分布式处理引擎。主要是由Java代码实现,目前还依靠开源社区的贡献发展。对Flink而言,所要处理的主要场景就是流数据。会把所有任务当做流来处理,也是最大的特点。
可以支持本地的快速迭代,以及一些环形的迭代任务。并且Flink可以定制化内存管理。就框架本身与应用场景来说,Flink更相似与Storm。
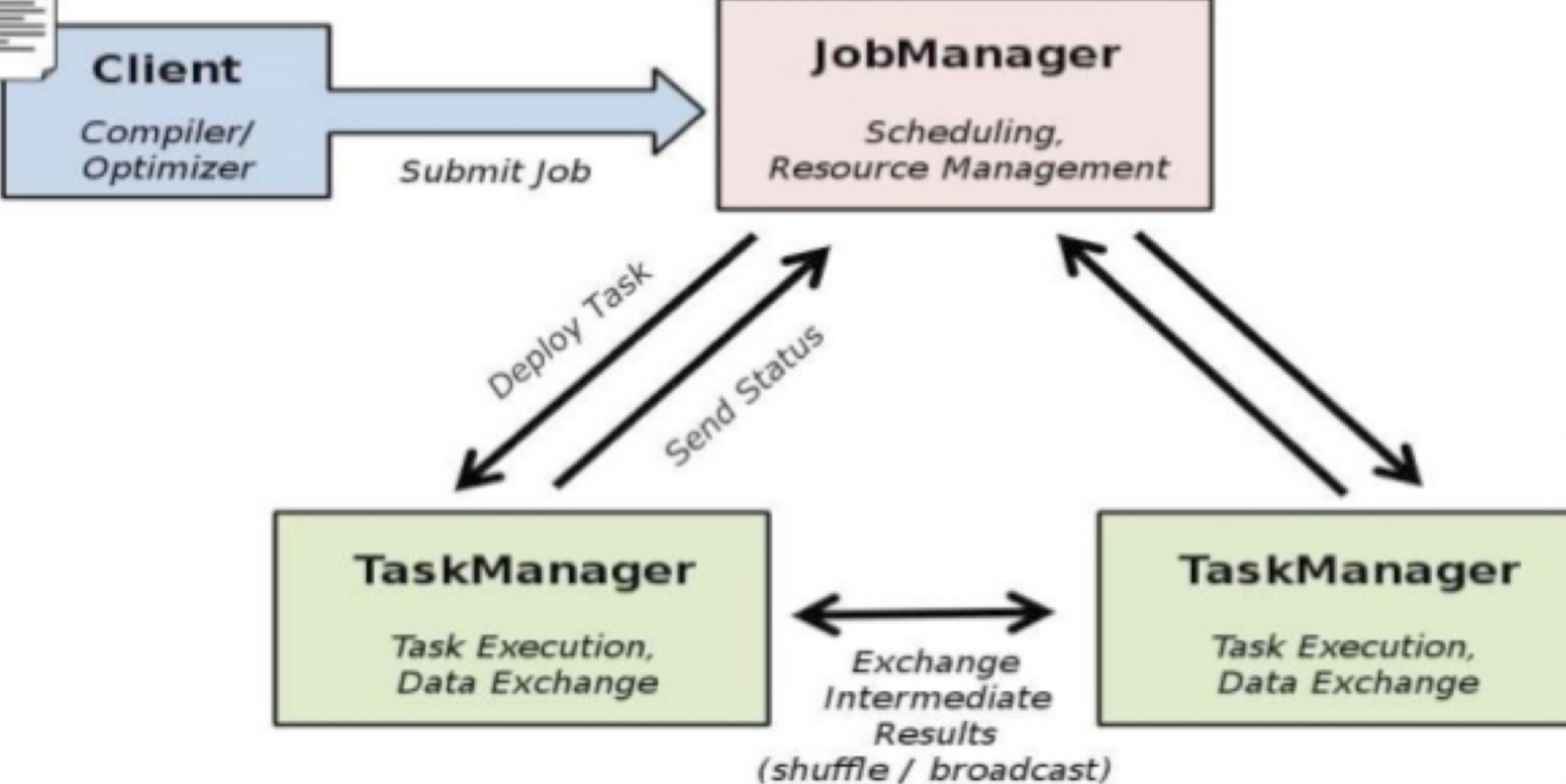
Client用来提交任务给JobManager
JobManager分发任务给TaskManager去执行,然后TaskManager会心跳的汇报任务状态。
Flink调度简述
在Flink集群中,计算资源被定义为Task Slot。每个TaskManager会拥有一个或多个Slots。JobManager会以Slot为单位调度Task。但这里的Task跟我们在Hadoop中的理解是有区别的。对Flink的JobManager来说,其调度的是一个Pipeline的Task,而不是一个点。
在Hadoop中Map和Reduce是两个独立调度的Task,并且都会去占用计算资源。对Flink来说MapReduce是一个Pipeline的Task,只占用一个计算资源。
在TaskManager中,根据其所拥有的Slot个数,同时会拥有多个Pipeline
因为Flink自身也需要简单的管理计算资源(Slot)。当Flink部署在Yarn上面之后,Flink并没有弱化资源管理。也就是说这时候的Flink再做一些Yarn该做的事情。
生态圈
Flink支持Scala和Java的API,Python在测试中。Flink通过Gelly支持了图操作,还有机器学习的FlinkML。Table是一种接口化的SQL支持,也就是API支持,而不是文本化的SQL解析和执行。
部署
Flink有三种部署模型,分别是Local,Standalone Cluster和Yarn Cluster。对于Local模式来说,JobManager和TaskManager会公用一个JVM来完成Workload。如果要验证简单的应用,Local模式是最方便的。实际应用中大多数使用Standalone或者Yarn Cluster
Standalone模式
搭建Standalone模式的Flink集群之前,需要先下载Flink安装包。
需要指定Master和Worker。Master机器会启动JobManager,Worker则会启动TaskManager。
需要修改conf目录中的master和slaves。在配置master文件时,需要指定JobManager的UI监听端口。
JobManager只需配置一个,Worker则需配置一个或多个。
在conf目录中找到文件flink-conf.yaml。文件中定义了Flink各个模块的基本属性,如RPC的端口。JobManager和TaskManager堆的大小等。一般只需要修改taskmanager.numberOfTaskSlots,拥有Slot个数。一般设置成CPU的core数。
Yarn Cluster模式
为了最大化利用集群资源,会在一个集群中同时运行多种类型的Workload。因此Flink也支持在Yarn上面运行。
#
Apache Flink学习笔记的更多相关文章
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:异步I/O访问外部数据
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Connectors概述
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- PHP解决网站大数据大流量与高并发
1:硬件方面 普通的一个p4的服务器每天最多能支持10万左右的IP,如果访问量超过10W那么需要专用的服务器才能解决,如果硬件不给力软件怎么优化都是于事无补的.主要影响服务器的速度 有:网络-硬盘读写 ...
- Ubunt16.04下安装PHP7+Nginx+MySQL
本文通过Ubuntu PPA来安装PHP7. 1.添加PPA $ sudo apt-get install python-software-properties software-properti ...
- Win7如何设置多用户同时远程登录
有时候服务器是Win7系统的时候,远程登录桌面时,即使登录的是不同的管理账号,还是会把远程登录的人给记下来.即不同的账号只能同时存在一个会话窗.本文教大家如果设置Win7让两个账号的两会话同时存在,且 ...
- centos6 安装glibc-2.14.1
CentOS默认的glibc版本为2.12.1, 网上都是给出的升级至glibc-2.14.1的方法, 都是用glibc-2.14.1.tar.gz [root@192-168-0-151 ~]# s ...
- JavaScript数组方法的兼容性写法 汇总:indexOf()、forEach()、map()、filter()、some()、every()
ECMA Script5中数组方法如indexOf().forEach().map().filter().some()并不支持IE6-8,但是国内依然有一大部分用户使用IE6-8,而以上数组方法又确实 ...
- 设计模式之——单例模式(Singleton)的常见应用场景(转):
单例模式(Singleton)也叫单态模式,是设计模式中最为简单的一种模式,甚至有些模式大师都不称其为模式,称其为一种实现技巧,因为设计模式讲究对象之间的关系的抽象,而单例模式只有自己一个对象,也因此 ...
- ZT 安卓手机的安全性 prepare for Q
如何增强安卓手机的安全性?安卓的安全性太低了!!! 众所周知,安卓手机是非常容易破解的,刷过机的人都知道,不管你之前在手机怎么设置密码,只要进入recovery清空使用记录,手机就会恢复出厂设置,到时 ...
- [MongoDB]------windos远程服务器部署连接
1.连接前的准备 这里就省略了服务器上安装的操作,跟上一节是一样的流程. 连接到远程服务器,首先需要到远程服务器上在mongoDb安装根目录下的bin文件夹(默认安装目录是C:\Program Fil ...
- Keepalived + haproxy双机高可用方案
上一篇文章已经讲到了keepalived实现双机热备,且遗留了一个问题 master的网络不通的时候,可以立即切换到slave,但是如果只是master上的应用出现问题的时候,是不会 主动切换的. 上 ...
- python第十四课--排序及自定义函数之案例二:冒泡排序
案例二:冒泡排序 lt1=[45,12,56,-32,-3,44,75,-22,100] print('排序前:'+str(lt1)) 自定义函数:实现冒泡排序(升序)原则:1).有没有形参?有,接受 ...