Flink BLOB架构
Flink中支持的BLOB文件类型
jar包
被user classloader使用的jar包
高负荷RPC消息
1. RPC消息长度超出了akka.framesize的大小
2. 在HA摸式中,利用底层分布式文件系统分发单个高负荷RPC消息,比如: TaskDeploymentDescriptor,给多个接受对象。
3. 失败导致重新部署过程中复用RPC消息
TaskManager的日志文件
为了在web ui上展示taskmanager的日志
按存储特性又分为两类
PERMANENT_BLOB
生命周期和job的生命周期一致,并且是可恢复的。会上传到BlobStore分布式文件系统中。
TRANSIENT_BLOB
生命周期由用户自行管理,并且是不可恢复的。不会上传到BlobStore分布式文件系统中。
架构图
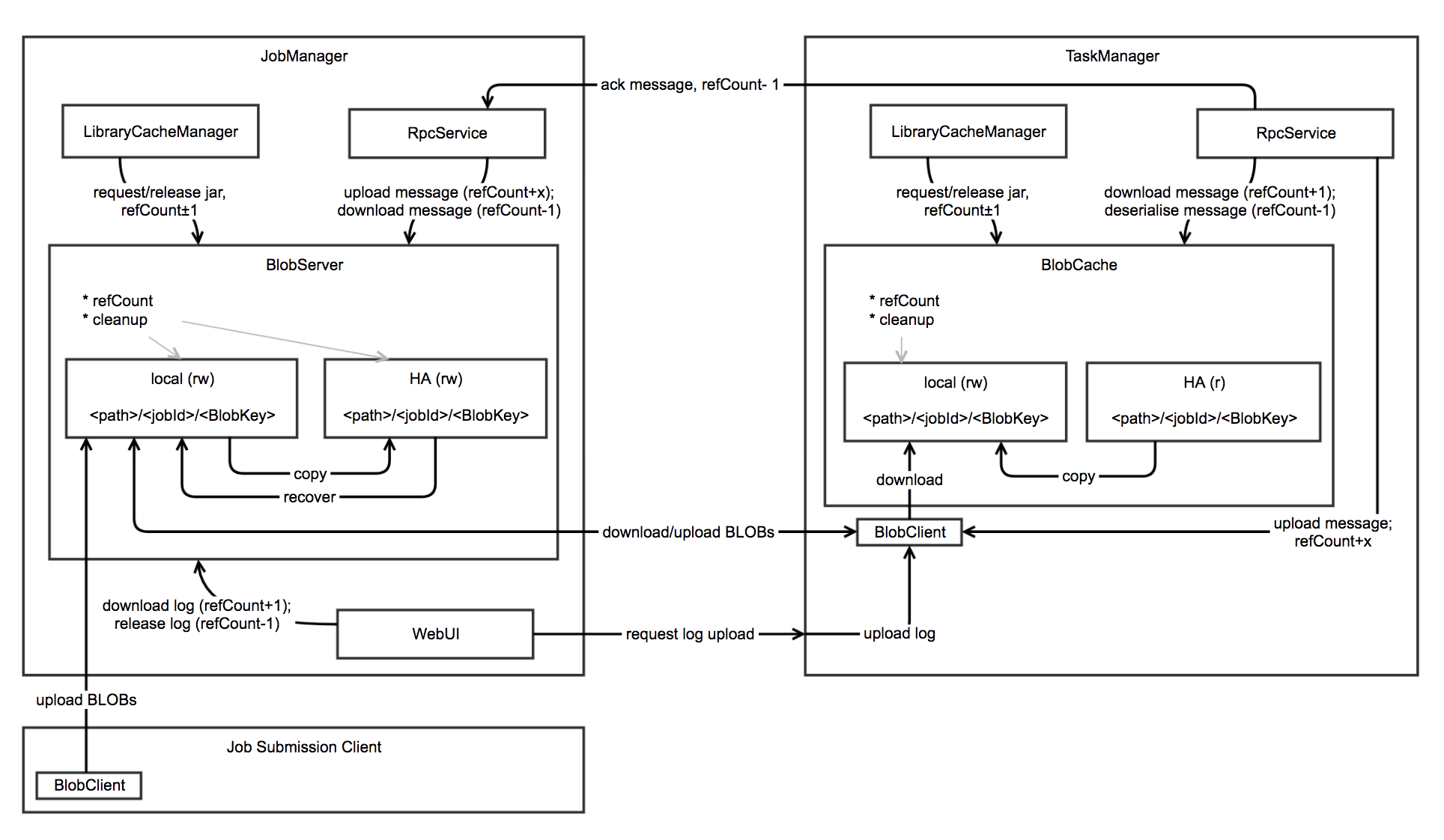
BlobStore
BLOB底层存储,支持多种实现`HDFS`,`S3`,`FTP`等,HA中使用BlobStore进行文件的恢复。
BlobServer
* 提供了基于jobId和BlobKey进行文件上传和下载的方法
* 本地文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* HA 分布式文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 负责本地文件系统和分布式文件系统的清理工作
* 先存储到本地文件系统中,然后如果需要的话再存储到分布式文件系统中
* 下载请求优先使用本地文件系统中的文件
* 进行HA恢复中,下载分布式系统中的文件到本地文件系统中
BlobClient
* 基于jobId和BlobKey对BlobServer中的文件进行本地文件缓存
* 本地文件的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 优先使用本地文件系统中的文件,然后尝试从HA分布式文件中获取,最后才尝试从BlobServer中下载
* 负责本地文件系统的清理工作
LibraryCacheManager
桥接task的classloader和缓存的库文件,其`registerJob`,`registerTask`会构建并缓存job,task运行需要的classloader
示例解析:standalone模式中的jar包管理
JobManager会创建BlobStore、BlobServer、BlobLibraryCacheManager具体过程见JobManager的createJobManagerComponents方法
try {
blobServer = new BlobServer(configuration, blobStore)
blobServer.start()
instanceManager = new InstanceManager()
scheduler = new FlinkScheduler(ExecutionContext.fromExecutor(futureExecutor))
libraryCacheManager =
new BlobLibraryCacheManager(
blobServer,
ResolveOrder.fromString(classLoaderResolveOrder),
alwaysParentFirstLoaderPatterns)
instanceManager.addInstanceListener(scheduler)
}
TaskManager注册到Jobmanager后会创建BlobCacheService、BlobLibraryCacheManager具体过程见TaskManager的associateWithJobManager方法
try {
val blobcache = new BlobCacheService(
address,
config.getConfiguration(),
highAvailabilityServices.createBlobStore())
blobCache = Option(blobcache)
libraryCacheManager = Some(
new BlobLibraryCacheManager(
blobcache.getPermanentBlobService,
config.getClassLoaderResolveOrder(),
config.getAlwaysParentFirstLoaderPatterns))
}
JobClient在向集群提交job的过程中会调用JobSubmissionClientActor的tryToSubmitJob方法进而调用JobGraph对象的uploadUserJars方法
try {
jobGraph.uploadUserJars(blobServerAddress, clientConfig);
} catch (IOException exception) {
getSelf().tell(
decorateMessage(new JobManagerMessages.JobResultFailure(
new SerializedThrowable(
new JobSubmissionException(
jobGraph.getJobID(),
"Could not upload the jar files to the job manager.",
exception)
)
)),
ActorRef.noSender());
return null;
}
LOG.info("Submit job to the job manager {}.", jobManager.path());
jobManager.tell(
decorateMessage(
new JobManagerMessages.SubmitJob(
jobGraph,
ListeningBehaviour.EXECUTION_RESULT_AND_STATE_CHANGES)),
getSelf());
public void uploadUserJars(
InetSocketAddress blobServerAddress,
Configuration blobClientConfig) throws IOException {
if (!userJars.isEmpty()) {
List<PermanentBlobKey> blobKeys = BlobClient.uploadJarFiles(
blobServerAddress, blobClientConfig, jobID, userJars);
for (PermanentBlobKey blobKey : blobKeys) {
if (!userJarBlobKeys.contains(blobKey)) {
userJarBlobKeys.add(blobKey);
}
}
}
}
然后在JobManager的submitJob方法中会调用BlobLibraryCacheManager的registerJob创建并缓存该job的classloader
try {
libraryCacheManager.registerJob(
jobGraph.getJobID, jobGraph.getUserJarBlobKeys, jobGraph.getClasspaths)
}
catch {
case t: Throwable =>
throw new JobSubmissionException(jobId,
"Cannot set up the user code libraries: " + t.getMessage, t)
}
val userCodeLoader = libraryCacheManager.getClassLoader(jobGraph.getJobID)
TaskManager在执行Task时,首先会调用LibraryCacheManager的registerTask从BlobServer下载相应的jar包并创建classloader
blobService.getPermanentBlobService().registerJob(jobId);
// first of all, get a user-code classloader
// this may involve downloading the job's JAR files and/or classes
LOG.info("Loading JAR files for task {}.", this);
userCodeClassLoader = createUserCodeClassloader();
private ClassLoader createUserCodeClassloader() throws Exception {
long startDownloadTime = System.currentTimeMillis();
// triggers the download of all missing jar files from the job manager
libraryCache.registerTask(jobId, executionId, requiredJarFiles, requiredClasspaths);
LOG.debug("Getting user code class loader for task {} at library cache manager took {} milliseconds",
executionId, System.currentTimeMillis() - startDownloadTime);
ClassLoader userCodeClassLoader = libraryCache.getClassLoader(jobId);
if (userCodeClassLoader == null) {
throw new Exception("No user code classloader available.");
}
return userCodeClassLoader;
}
涉及到的相关配置
| 参数 | 默认值 | 描述 |
|---|---|---|
| high-availability.storageDir | 无 | HA BlobStore根目录 |
| blob.storage.directory | <java.io.tmpdir> | BlobServer 本地文件根目录 |
| blob.fetch.num-concurrent | 50 | BlobServer fetch文件的最大并行度 |
| blob.fetch.backlog | 1000 | 允许最大的排队等待链接数 |
| blob.service.cleanup.interval | 3600 | BlobServer cleanup 线程运行的间隔 |
| blob.fetch.retries | 5 | 从BlobServer下载文件错误重试次数 |
| blob.server.port | 0 | BlobServer端口范围 |
| blob.offload.minsize | 1024 * 1024 | 运行通过BlobServer传递的最小消息大小 |
| classloader.resolve-order | child-first | classloader类加载顺序 |
Flink BLOB架构的更多相关文章
- Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型 本文翻译自General Architecture and Process Model ----------------------------------------- ...
- Flink| 运行架构
1. Flink运行时组件 作业管理器(JobManager) 任务管理器(TaskManager) 资源管理器(ResourceManager) 分发器(Dispatcher) 2. 任务提交流程 ...
- Flink架构,源码及debug
序 工作中用Flink做批量和流式处理有段时间了,感觉只看Flink文档是对Flink ProgramRuntime的细节描述不是很多, 程序员还是看代码最简单和有效.所以想写点东西,记录一下,如果能 ...
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink原理(一)——基础架构
Flink系列博客,基于Flink1.6,打算分为三部分:原理.源码.实例以及API使用分析,后期等系列博客完成后再弄一个目录. 该系列博客是我自己学习过程中的一些理解,若有不正确.不准确的地方欢迎大 ...
- 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?
本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识.实践.调优.内部实现等各个方面,带你由浅 ...
- 开篇 | 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?
本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识.实践.调优.内部实现等各个方面,带你由浅 ...
- Flink的应用场景和架构
Flink的应用场景 Flink项目的理念就是:Flink是为分布式,高性能,随时可用以及准确的流处理应用程序打造的开源流处理框架.自2019年开源以来,迅速成为大数据实时计算领域炙手可热的技术框架. ...
随机推荐
- Oracle从一个用户导出数据到另一个用户
如果想导入的用户已经存在: 1. 导出用户 expdp user1/pass1 directory=dumpdir dumpfile=user1.dmp 2. 导入用户 impdp user2/pas ...
- BZOJ2694:Lcm——包看得懂/看不懂题解
http://www.lydsy.com/JudgeOnline/problem.php?id=2694 Description 对于任意的>1的n gcd(a, b)不是n^2的倍数 也就是说 ...
- Linux终端里的记录器
我们在调试程序的时候,免不了要去抓一些 log ,然后进行分析. 如果 log 量不是很大的话,那很简单,只需简单的复制粘贴就好. 但是如果做一些压力测试,产生大量 log ,而且系统内存又比较小(比 ...
- ubuntu下boot分区空间不足问题的解决方案
https://blog.csdn.net/along_oneday/article/details/75148240 先查看当前内核版本号(防止误删) uname –r 查看已经安装过的内核 dpk ...
- HihoCoder - 1336 二维数状数组(单点更新 区间查询)
You are given an N × N matrix. At the beginning every element is 0. Write a program supporting 2 ope ...
- 【js】按下enter键禁止表单自动提交
//enter键盘事件 document.onkeypress=function(){ if(event.keyCode==13){ return false; } }
- 旧贴-在 win7 / win8 下安装苹果系统 (懒人版)
前言 该文转载自远景论坛,发布时间2012年,仅供学习参考 这篇安装教程的素材在国庆就准备好了,但那时学习任务比较重,没有时间发帖,一直拖到现在.趁这个周末有空,赶紧写完它,希望能帮助一些景友. 论坛 ...
- 详解 Python3 正则表达式(五)
上一篇:详解 Python3 正则表达式(四) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些注明和修改 ^_^ 非捕获组和命名 ...
- hadoop--hive数据仓库
一.hive概述 Hive是基于 Hadoop 的一个[数据仓库工具],可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进 ...
- RabbitMQ(三):消息持久化策略
原文:RabbitMQ(三):消息持久化策略 一.前言 在正常的服务器运行过程中,时常会面临服务器宕机重启的情况,那么我们的消息此时会如何呢?很不幸的事情就是,我们的消息可能会消失,这肯定不是我们希望 ...