Flink BLOB架构
Flink中支持的BLOB文件类型
jar包
被user classloader使用的jar包
高负荷RPC消息
1. RPC消息长度超出了akka.framesize的大小
2. 在HA摸式中,利用底层分布式文件系统分发单个高负荷RPC消息,比如: TaskDeploymentDescriptor,给多个接受对象。
3. 失败导致重新部署过程中复用RPC消息
TaskManager的日志文件
为了在web ui上展示taskmanager的日志
按存储特性又分为两类
PERMANENT_BLOB
生命周期和job的生命周期一致,并且是可恢复的。会上传到BlobStore分布式文件系统中。
TRANSIENT_BLOB
生命周期由用户自行管理,并且是不可恢复的。不会上传到BlobStore分布式文件系统中。
架构图
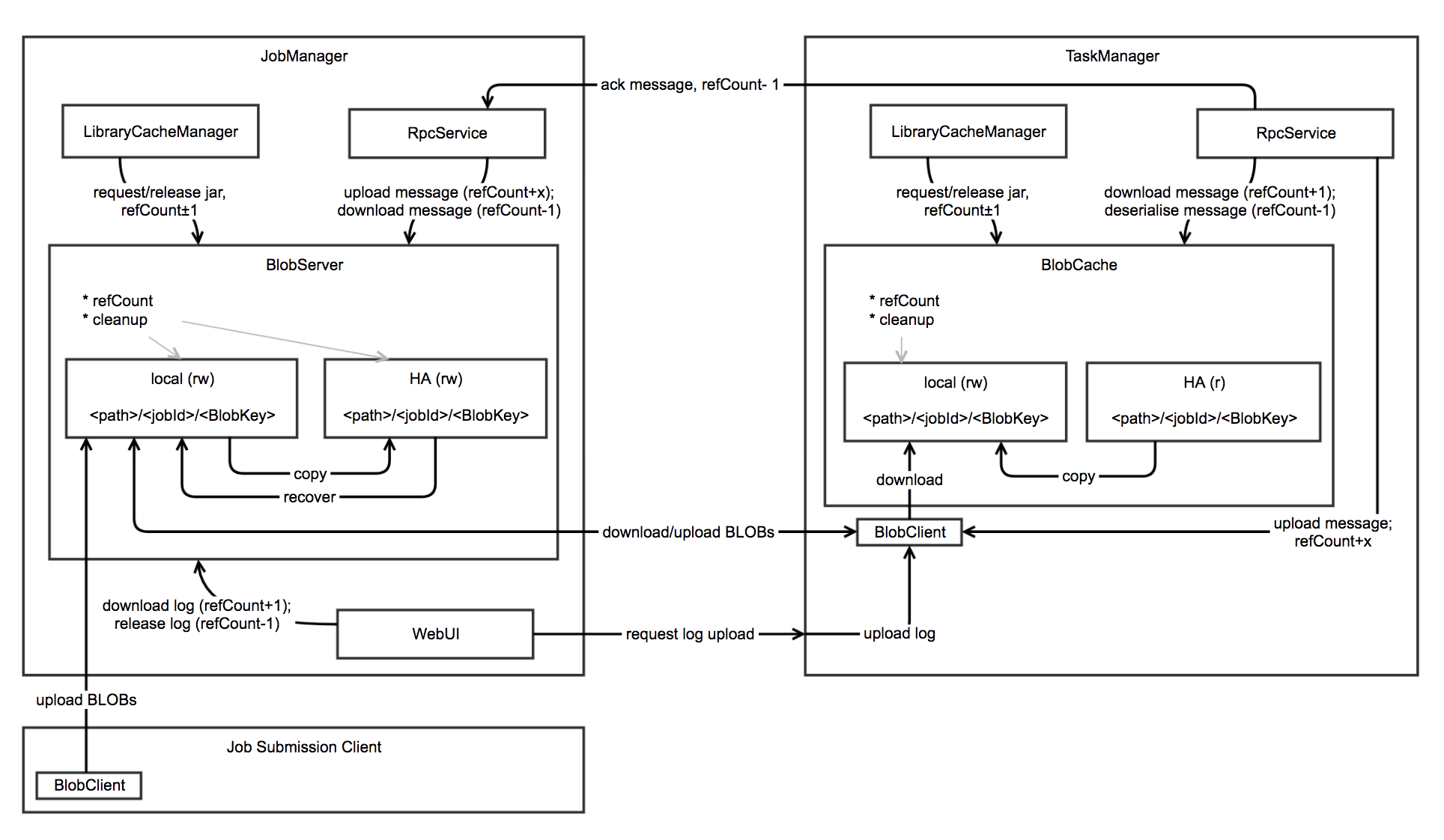
BlobStore
BLOB底层存储,支持多种实现`HDFS`,`S3`,`FTP`等,HA中使用BlobStore进行文件的恢复。
BlobServer
* 提供了基于jobId和BlobKey进行文件上传和下载的方法
* 本地文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* HA 分布式文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 负责本地文件系统和分布式文件系统的清理工作
* 先存储到本地文件系统中,然后如果需要的话再存储到分布式文件系统中
* 下载请求优先使用本地文件系统中的文件
* 进行HA恢复中,下载分布式系统中的文件到本地文件系统中
BlobClient
* 基于jobId和BlobKey对BlobServer中的文件进行本地文件缓存
* 本地文件的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 优先使用本地文件系统中的文件,然后尝试从HA分布式文件中获取,最后才尝试从BlobServer中下载
* 负责本地文件系统的清理工作
LibraryCacheManager
桥接task的classloader和缓存的库文件,其`registerJob`,`registerTask`会构建并缓存job,task运行需要的classloader
示例解析:standalone模式中的jar包管理
JobManager会创建BlobStore、BlobServer、BlobLibraryCacheManager具体过程见JobManager的createJobManagerComponents方法
try {
blobServer = new BlobServer(configuration, blobStore)
blobServer.start()
instanceManager = new InstanceManager()
scheduler = new FlinkScheduler(ExecutionContext.fromExecutor(futureExecutor))
libraryCacheManager =
new BlobLibraryCacheManager(
blobServer,
ResolveOrder.fromString(classLoaderResolveOrder),
alwaysParentFirstLoaderPatterns)
instanceManager.addInstanceListener(scheduler)
}
TaskManager注册到Jobmanager后会创建BlobCacheService、BlobLibraryCacheManager具体过程见TaskManager的associateWithJobManager方法
try {
val blobcache = new BlobCacheService(
address,
config.getConfiguration(),
highAvailabilityServices.createBlobStore())
blobCache = Option(blobcache)
libraryCacheManager = Some(
new BlobLibraryCacheManager(
blobcache.getPermanentBlobService,
config.getClassLoaderResolveOrder(),
config.getAlwaysParentFirstLoaderPatterns))
}
JobClient在向集群提交job的过程中会调用JobSubmissionClientActor的tryToSubmitJob方法进而调用JobGraph对象的uploadUserJars方法
try {
jobGraph.uploadUserJars(blobServerAddress, clientConfig);
} catch (IOException exception) {
getSelf().tell(
decorateMessage(new JobManagerMessages.JobResultFailure(
new SerializedThrowable(
new JobSubmissionException(
jobGraph.getJobID(),
"Could not upload the jar files to the job manager.",
exception)
)
)),
ActorRef.noSender());
return null;
}
LOG.info("Submit job to the job manager {}.", jobManager.path());
jobManager.tell(
decorateMessage(
new JobManagerMessages.SubmitJob(
jobGraph,
ListeningBehaviour.EXECUTION_RESULT_AND_STATE_CHANGES)),
getSelf());
public void uploadUserJars(
InetSocketAddress blobServerAddress,
Configuration blobClientConfig) throws IOException {
if (!userJars.isEmpty()) {
List<PermanentBlobKey> blobKeys = BlobClient.uploadJarFiles(
blobServerAddress, blobClientConfig, jobID, userJars);
for (PermanentBlobKey blobKey : blobKeys) {
if (!userJarBlobKeys.contains(blobKey)) {
userJarBlobKeys.add(blobKey);
}
}
}
}
然后在JobManager的submitJob方法中会调用BlobLibraryCacheManager的registerJob创建并缓存该job的classloader
try {
libraryCacheManager.registerJob(
jobGraph.getJobID, jobGraph.getUserJarBlobKeys, jobGraph.getClasspaths)
}
catch {
case t: Throwable =>
throw new JobSubmissionException(jobId,
"Cannot set up the user code libraries: " + t.getMessage, t)
}
val userCodeLoader = libraryCacheManager.getClassLoader(jobGraph.getJobID)
TaskManager在执行Task时,首先会调用LibraryCacheManager的registerTask从BlobServer下载相应的jar包并创建classloader
blobService.getPermanentBlobService().registerJob(jobId);
// first of all, get a user-code classloader
// this may involve downloading the job's JAR files and/or classes
LOG.info("Loading JAR files for task {}.", this);
userCodeClassLoader = createUserCodeClassloader();
private ClassLoader createUserCodeClassloader() throws Exception {
long startDownloadTime = System.currentTimeMillis();
// triggers the download of all missing jar files from the job manager
libraryCache.registerTask(jobId, executionId, requiredJarFiles, requiredClasspaths);
LOG.debug("Getting user code class loader for task {} at library cache manager took {} milliseconds",
executionId, System.currentTimeMillis() - startDownloadTime);
ClassLoader userCodeClassLoader = libraryCache.getClassLoader(jobId);
if (userCodeClassLoader == null) {
throw new Exception("No user code classloader available.");
}
return userCodeClassLoader;
}
涉及到的相关配置
| 参数 | 默认值 | 描述 |
|---|---|---|
| high-availability.storageDir | 无 | HA BlobStore根目录 |
| blob.storage.directory | <java.io.tmpdir> | BlobServer 本地文件根目录 |
| blob.fetch.num-concurrent | 50 | BlobServer fetch文件的最大并行度 |
| blob.fetch.backlog | 1000 | 允许最大的排队等待链接数 |
| blob.service.cleanup.interval | 3600 | BlobServer cleanup 线程运行的间隔 |
| blob.fetch.retries | 5 | 从BlobServer下载文件错误重试次数 |
| blob.server.port | 0 | BlobServer端口范围 |
| blob.offload.minsize | 1024 * 1024 | 运行通过BlobServer传递的最小消息大小 |
| classloader.resolve-order | child-first | classloader类加载顺序 |
Flink BLOB架构的更多相关文章
- Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型 本文翻译自General Architecture and Process Model ----------------------------------------- ...
- Flink| 运行架构
1. Flink运行时组件 作业管理器(JobManager) 任务管理器(TaskManager) 资源管理器(ResourceManager) 分发器(Dispatcher) 2. 任务提交流程 ...
- Flink架构,源码及debug
序 工作中用Flink做批量和流式处理有段时间了,感觉只看Flink文档是对Flink ProgramRuntime的细节描述不是很多, 程序员还是看代码最简单和有效.所以想写点东西,记录一下,如果能 ...
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink原理(一)——基础架构
Flink系列博客,基于Flink1.6,打算分为三部分:原理.源码.实例以及API使用分析,后期等系列博客完成后再弄一个目录. 该系列博客是我自己学习过程中的一些理解,若有不正确.不准确的地方欢迎大 ...
- 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?
本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识.实践.调优.内部实现等各个方面,带你由浅 ...
- 开篇 | 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?
本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识.实践.调优.内部实现等各个方面,带你由浅 ...
- Flink的应用场景和架构
Flink的应用场景 Flink项目的理念就是:Flink是为分布式,高性能,随时可用以及准确的流处理应用程序打造的开源流处理框架.自2019年开源以来,迅速成为大数据实时计算领域炙手可热的技术框架. ...
随机推荐
- swift的Hashable
Conforming to the Hashable Protocol To use your own custom type in a set or as the key type of a dic ...
- redis key/value 出现\xAC\xED\x00\x05t\x00\x05
1.问题现象: 最近使用spring-data-redis 和jedis 操作redis时发现存储在redis中的key不是程序中设置的string值,前面还多出了许多类似\xac\xed\x00\x ...
- 【洛谷】【归并排序】P1908 逆序对
[题目描述:] 猫猫TOM和小老鼠JERRY最近又较量上了,但是毕竟都是成年人,他们已经不喜欢再玩那种你追我赶的游戏,现在他们喜欢玩统计.最近,TOM老猫查阅到一个人类称之为“逆序对”的东西,这东西是 ...
- mongodb的学习-6-命令简单使用
1.创建数据库 use DATABASE_NAME 举例说明: > use another //创建了数据库another switched to db another > db anot ...
- oracle数据库之操作总结
## 连接数据库: sqlplus test/test##@localhost:/ORCL ## 查询数据库所有的表: select table_name from user_tables; ## 查 ...
- servlet使用
一.使用IDEAL创建项目 1) 2) 3) 4) 5) 6) 7) 8) 9) 二.路径介绍: 配置文件: servlet配置文件: package ser_Test; import javax.s ...
- Servlet基础笔记
一.什么Servlet? servlet 是运行在 Web 服务器中的小型 Java 程序(即:服务器端的小应用程序).servlet 通常通过 HTTP(超文本传输协议)接收和响应来自 Web 客户 ...
- Centos7安装elasticsearch、logstash、kibana、elasticsearch head
环境:Centos7, jdk1.8 安装logstash 1.下载logstash 地址:https://artifacts.elastic.co/downloads/logstash/logsta ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- python3通过纯真IP数据库查询IP归属地信息
在网上看到的别人写的python2的代码,修改成了python3. 把纯真IP数据库文件qqwry.dat放到czip.py同一目录下. #! /usr/bin/env python # -*- co ...