MySQL基础架构之查询语句执行流程
这篇笔记主要记录mysql的基础架构,一条查询语句是如何执行的。
比如,在我们从student表中查询一个id=2的信息
select * from student where id=2;
在解释这条语句执行流程之前,我们看看mysql的基础架构。
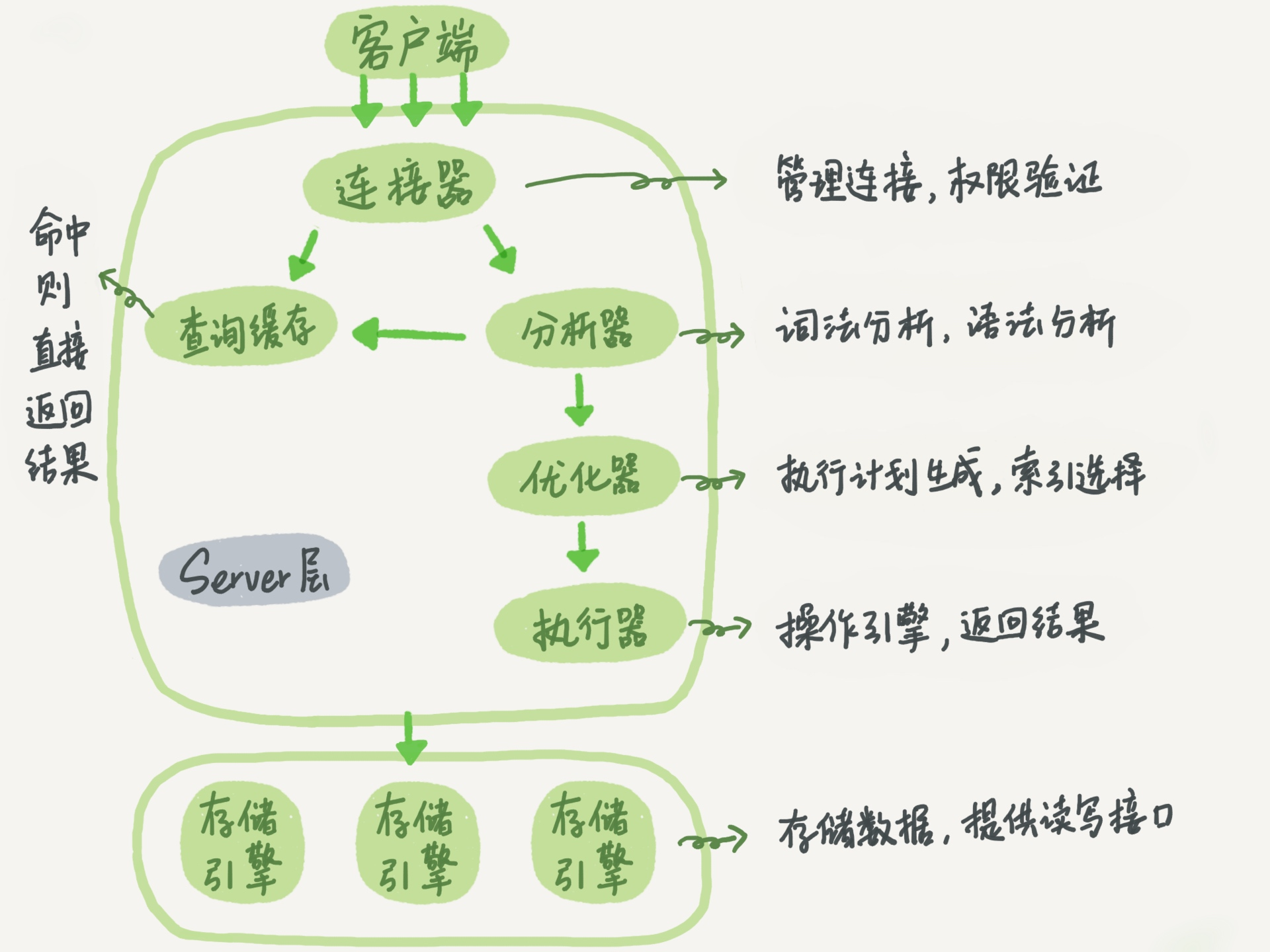
图来自极客时间的mysql实践,该图是描述的是MySQL的逻辑架构。
- server层包括连接器、查询缓存、分析器、优化器、执行器涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视等。
- 存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory 等多个存储引擎,平常我们比较常用的是innoDB引擎
连接器
我们在使用数据库之前,需要连接到数据库,连接语句是
mysql -h $ip -u $username -p $password
而我们的连接器就是处理这个过程的,连接器的主要功能是负责跟客户端建立连接、获取权限、维持和管理连接,连接器在使用的过程中如果该用户的权限改变,是不会马上生效的,因为用户权限是在连接的时候读取的,只能重新连接才可以更新权限
连接器与客户端通信的协议是tcp协议的,连接以后可以使用show processlist;看到执行的连接数

同时在连接时间内超过8小时是sleep的状态会自动断开,这个是mysql默认设置,如果一直不断开,那么这个过程可以叫做一个长连接。
与之对应的有短连接,短连接是指在执行一条或几条的以后断开连接。
当不断使用长连接的时候会占用很大的内存资源,在mysql5.7以后可以使用mysql_reset_connection语句来重新初始化资源。
查询缓存
经过连接以后,就连接上数据库了,这个时候可以执行语句了。
执行语句的时候,mysql首先是去查询缓存,之前有没有执行过这样的语句,mysql会将之前执行过的语句和结果以key-value的形式存储起来(当然有一定的存储和实效时间)。如果存在缓存,则直接返回缓存的结果。
缓存的工作流程是
- 服务器接收SQL,以SQL和一些其他条件为key查找缓存表
- 如果找到了缓存,则直接返回缓存
- 如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等。
- 执行完SQL查询结果以后,将SQL查询结果缓存入缓存表
当然,如果这个表修改了,那么使用这个表中的所有缓存将不再有效,查询缓存值得相关条目将被清空。所以在一张被反复修改的表中进行语句缓存是不合适的,因为缓存随时都会实效,这样查询缓存的命中率就会降低很多,不是很划算。
当这个表正在写入数据,则这个表的缓存(命中缓存,缓存写入等)将会处于失效状态,在Innodb中,如果某个事务修改了这张表,则这个表的缓存在事务提交前都会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存。
一般来说,如果是一张静态表或者是很少变化的表就可以进行缓存,这样的命中率就很高。
下面来说说缓存的使用时机,衡量打开缓存是否对系统有性能提升是一个很难的话题
- 通过缓存命中率判断, 缓存命中率 = 缓存命中次数 (
Qcache_hits) / 查询次数 (Com_select) - 通过缓存写入率, 写入率 = 缓存写入次数 (
Qcache_inserts) / 查询次数 (Qcache_inserts) - 通过 命中-写入率 判断, 比率 = 命中次数 (
Qcache_hits) / 写入次数 (Qcache_inserts), 高性能MySQL中称之为比较能反映性能提升的指数,一般来说达到3:1则算是查询缓存有效,而最好能够达到10:1
分析器
在查询缓存实效或者是无缓存的时候,这个时候MySQL的server就会利用分析器来分析语句,分析器也叫解析器。
MySQL分析器由两部分组成,第一部分是用来词法分析扫描字符流,根据构词规则识别单个单词,MySQL使用Flex来生成词法扫描程序在sql/lex.h中定义了MySQL关键字和函数关键字,用两个数组存储;第二部分的功能是语法分析在词法分析的基础上将单词序列组成语法短语,最后生成语法树,提交给优化器语法分析器使用Bison,在sql/sql_yacc.yy中定义了语法规则。然后根据关系代数理论生成语法树。
上面解释分析器太官方和复杂了,其实分析器主要是用来进行“词法分析”然后知道这个数据库语句是要干嘛,代表啥意思。
这个时候如果分析器分析出这个语句有问题的时候会报错,比如ERROR 1064 (42000): You have an error in your SQL syntax
优化器
在分析器分析完了以后知道这个语句是干嘛的时候,接下来是专门用一个优化器进行语句优化,优化器的任务是发现执行SQL查询的最佳方案。大多数查询优化器,包括MySQL的查询优化器,总或多或少地在所有可能的查询评估方案中搜索最佳方案。
优化器主要是选择一个最佳的执行方案,执行方案是为了减少开销,提高执行效率。
MySQL的优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划:
- 重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
- 优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值,具体原理见下文)
- 提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
- 优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型应用,效率会高很多)
随着MySQL的不断发展,优化器使用的优化策略也在不断的进化,这里仅仅介绍几个非常常用且容易理解的优化策略而已。
执行器
在分析器知道语句要干什么,优化器知道怎么做以后,下面就到了执行的阶段,执行是交给执行器的。
执行器在执行的时候首先判断该用户对该表有没有执行权限,如果没有则会返回denied之类的错误提示。
如果有权限,则会打开表继续执行。打开表的时候,执行器会根据表定义的引擎,去使用该引擎的接口。
最后执行语句得到数据返回给客户端。
总结
MySQL得到sql语句后,大概流程如下:
- 0.连接器负责和客户端进行通信
- 1.查询缓存:首先查询缓存看是否存在k-v缓存
- 2.解析器:负责解析和转发sql
- 3.预处理器:对解析后的sql树进行验证
- 4.优化器:得到一个执行计划
- 5.查询执行引擎:执行器执行语句得到数据结果集
- 6.将数据放回给调用端。

MySQL基础架构之查询语句执行流程的更多相关文章
- MySql基础架构以及SQL语句执行流程
01. mysql基础架构 SQL语句是如何执行的 学习一下mysql的基础架构,从一条sql语句是如何执行的来学习. 一般我们写一条查询语句类似下面这样: select user,password ...
- SQL查询语句执行流程
msyql执行流程 你有个最简单的表,表里只有一个 ID 字段,在执行下面这个查询语句时:: select * from T where ID=10: 我们看到的只是输入一条语句,返回一个结果,却不知 ...
- mysql 8.0.28 查询语句执行顺序实测结果
TL;NRs 根据实测结果,MySQL8.0.28 中 SQL 语句的执行顺序为: (8) SELECT (5) DISTINCT <select_list> (1) FROM <l ...
- Mysql查询语句执行过程
Mysql查询语句执行过程 Mysql分为server层和存储引擎两部分,或许可以再加一层连接层 连接层(器) Mysql使用的是典型的C/S架构.连接器通过典型的TCP握手完成连接. 需要注 ...
- MySQL查询语句执行过程及性能优化(JOIN/ORDER BY)-图
http://blog.csdn.net/iefreer/article/details/12622097 MySQL查询语句执行过程及性能优化-查询过程及优化方法(JOIN/ORDER BY) 标签 ...
- python 3 mysql sql逻辑查询语句执行顺序
python 3 mysql sql逻辑查询语句执行顺序 一 .SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_t ...
- [转]MySQL查询语句执行过程详解
Mysql查询语句执行原理 数据库查询语句如何执行?语法分析:首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树.语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是 ...
- 深入学习MySQL 01 一条查询语句的执行过程
在学习SpringCloud的同时,也在深入学习MySq中,听着<mysql45讲>,看着<高性能MySQL>,本系列文章是本人学习过程的总结,水平有限,仅供参考,若有不对之处 ...
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
随机推荐
- ES(ElasticSearch)学习总结
基本概念 一个分布式多用户能力的全文搜索引擎,基于RESTful web接口. Elasticsearch和MongoDB/Redis/Memcache一样,是非关系型数据库.是一个接近实时的搜索平台 ...
- Ubuntu18.04 使用过程遇到的问题记录
索引: 1.Ubuntu 18.04 安装搜狗输入法 2.在 Ubuntu 18.04 中将第三方软件添加至 favorite 菜单栏 3.在 VMware workstation 中为虚拟机安装 V ...
- python第十六课——外部函数and内部函数
1.外部函数&内部函数 内部函数: 定义在某个函数的内部,就是内部函数: [注意事项]: 1).内部函数可以随意使用它外部函数中的内容 2).外部函数不能使用内部函数中的内容 3).内部函数不 ...
- nodejs的expresss中post的req.body总是undefined的原因
1)因为express将body-parser分离了出来,所以你需要手动添加进下面的内容即可 var path = require('path'); var bodyParser = require( ...
- 解析Array.prototype.slice.call(arguments)
在es5标准中,我们经常需要把arguments对象转换成真正的数组 // 你可以这样写 var arr = Array.prototype.slice.call(arguments) // 你还可以 ...
- spring boot集成dubbo
spring-boot-start-dubbo spring-boot-start-dubbo,让你可以使用spring-boot的方式开发dubbo程序.使dubbo开发变得如此简单. 如何使用 1 ...
- atom / vscode (配置c++环境流程)
最初主要是被这个炫酷的插件吸引了,这么打代码太特么有激情了 还有跳舞的初音姐姐哦!! 现附上一篇文章,这篇文章步骤讲得很详细了 http://blog.csdn.net/qq_36731677/art ...
- java 工作流项目源码 SSM 框架 Activiti-master springmvc 集成web在线流程设计器
即时通讯:支持好友,群组,发图片.文件,消息声音提醒,离线消息,保留聊天记录 (即时聊天功能支持手机端,详情下面有截图) 工作流模块---------------------------------- ...
- 查询job的几个语句
select * from dba_jobs ;select * from dba_scheduler_job_run_details t; ------>这个语句通过制定job名,来查看 ...
- day 81 Vue学习一之vue初识
Vue学习一之vue初识 本节目录 一 Vue初识 二 ES6的基本语法 三 Vue的基本用法 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 vue初识 vue称为渐进式js ...