在PYTHON中使用StringIO的性能提升实测(更新list-join对比)
刚开始学习PYTHON,感觉到这个语言真的是很好用,可以快速完成功能实现。
最近试着用它完成工作中的一个任务:在Linux服务器中完成对.xml.gz文件的解析,生成.csv文件,以供SqlServer服务器导入,做进一步的数据分析。
解压后的xml文件格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<bulkPmMrDataFile>
<fileHeader fileFormatVersion="V1.0.4" reportTime="2016-02-22T21:00:00.000" ></fileHeader>
<eNB id="122941">
<measurement>
<smr>MR.LteScRSRP MR.LteScRSRQ MR.LteScTadv MR.LteSceNBRxTxTimeDiff ...</smr>
<object id="31472897" MmeUeS1apId="2417300878" MmeGroupId="1025" MmeCode="199" TimeStamp="2016-02-22T20:00:02.517">
<v>38 22 6 31 34 0 34 38400 110 NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL 7 23 NIL 26 24 0 0 </v>
</object>
<object id="31472897" MmeUeS1apId="2416229278" MmeGroupId="1025" MmeCode="199" TimeStamp="2016-02-22T20:00:02.792">
<v>61 30 5 32 45 0 27 38400 110 NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL 7 14 NIL 1 49 0 0 </v>
</object>
<object id="31472897" MmeUeS1apId="2148286566" MmeGroupId="1025" MmeCode="199" TimeStamp="2016-02-22T20:00:07.177">
<v>42 26 5 31 30 412 35 38400 110 NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL 7 14 NIL 26 24 0 0 </v>
</object>
<object id="31472897" MmeUeS1apId="2417300878" MmeGroupId="1025" MmeCode="199" TimeStamp="2016-02-22T20:00:07.677">
<v>39 22 7 31 35 387 36 38400 110 36 18 38400 108 NIL NIL NIL NIL NIL NIL NIL 5 10 NIL 25 25 0 0 </v>
</object>
<object id="31472897" MmeUeS1apId="2416229278" MmeGroupId="1025" MmeCode="199" TimeStamp="2016-02-22T20:00:07.962">
<v>61 27 5 31 43 427 36 38400 110 49 4 38400 108 NIL NIL NIL NIL NIL NIL NIL 9 13 NIL 1 49 0 0 </v>
<v>61 27 5 31 43 427 36 38400 110 46 0 38400 295 NIL NIL NIL NIL NIL NIL NIL 9 13 NIL 1 49 0 0 </v>
</object>
<object id="31472897" MmeUeS1apId="269973066" MmeGroupId="1025" MmeCode="199" TimeStamp="2016-02-22T20:00:08.382">
<v>41 23 9 32 23 447 36 38400 110 32 11 38400 358 NIL NIL NIL NIL NIL NIL NIL 6 22 NIL 24 26 0 0 </v>
<v>41 23 9 32 23 447 36 38400 110 31 7 38400 295 NIL NIL NIL NIL NIL NIL NIL 6 22 NIL 24 26 0 0 </v>
<v>41 23 9 32 23 447 36 38400 110 28 8 38400 460 NIL NIL NIL NIL NIL NIL NIL 6 22 NIL 24 26 0 0 </v>
</object>
</measurement>
<measurement>
<smr>MR.LteScPlrULQci1 MR.LteScPlrULQci2 MR.LteScPlrULQci3 MR.LteScPlrULQci4 ...</smr>
<object id="60057088" MmeUeS1apId="2416982066" MmeGroupId="1025" MmeCode="206" TimeStamp="2016-02-24T06:00:03.962">
<v>NIL NIL NIL NIL NIL NIL NIL NIL 0 NIL NIL NIL NIL NIL NIL NIL NIL 0 </v>
</object>
..........................
</measurement>
<measurement>
<smr>MR.LteScRIP</smr>
<object id="60057089:37900:2" TimeStamp="2016-02-24T06:00:11.259" MmeCode="NIL" MmeGroupId="NIL" MmeUeS1apId="NIL">
<v>81</v>
</object>
..........................
</measurement>
</eNB>
</bulkPmMrDataFile>
从廖雪峰博客学习得知目前常用的两种xml解析方式为DOM和SAX,分别进行了尝试,从个人角度来看,还是DOM比较好用,包括应用逻辑以及代码编写,都相对轻松简单。
在尝试SAX解析的过程中,开始按照习惯的方式,对XML文件中筛选的可用字段进行字符串相加,导致的后果是程序运行特别的慢,于是又尝试了cStringIO内存文件,这才感受到了内存文件的速度优势。
下面列出其中的关键字段以作对比。
- 使用字符串相加方式(s为定义的字符串变量):
#处理开始标签
def start_element(self, name, attrs):
global d_eNB
global d_obj
global s
if name == 'eNB':
d_eNB = attrs
elif name == 'object':
d_obj = attrs
elif name == 'v':
s = s + d_eNB['id']+' '+ d_obj['id']+' '+d_obj['MmeUeS1apId']+' '+d_obj['MmeGroupId']+' '+d_obj['MmeCode']+' '+d_obj['TimeStamp']+' '
else:
pass
- 使用cStringIO内存文件方式(output为定义的cStringIO变量):
#处理开始标签
def start_element(self, name, attrs):
global d_eNB
global d_obj
if name == 'eNB':
d_eNB = attrs
elif name == 'object':
d_obj = attrs
elif name == 'v':
output.write(d_eNB['id']+' '+ d_obj['id']+' '+d_obj['MmeUeS1apId']+' '+d_obj['MmeGroupId']+' '+d_obj['MmeCode']+' '+d_obj['TimeStamp']+' ')
else:
pass
对于一个相同的.xml.gz文件,文件总行数为173890行,其中有用数据为90079行。实测结果如下:

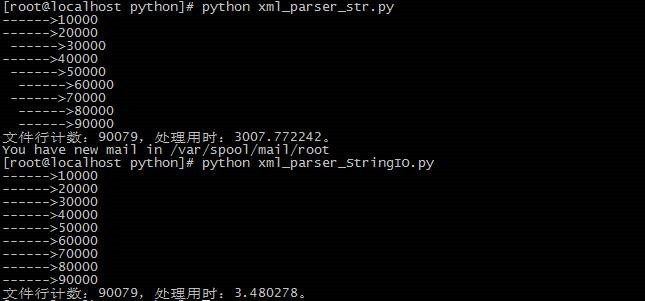{kind=link}
{kind=link}
可以看到,在应用了内存文件后,程序的处理性能有了翻天覆地的变化,处理耗时为前者的将近千分之一,赞!!!
最近又尝试修改字符串连接为list-join方式,代码如下:
- 使用list-join方式(lst为定义的list变量):
#处理开始标签
def start_element(self, name, attrs):
global d_eNB
global d_obj
global lst
if name == 'eNB':
d_eNB = attrs
elif name == 'object':
d_obj = attrs
elif name == 'v':
lst.append(d_eNB['id']+' ')
lst.append(d_obj['id']+' ')
lst.append(d_obj['MmeUeS1apId']+' ')
lst.append(d_obj['MmeGroupId']+' ')
lst.append(d_obj['MmeCode']+' ')
lst.append(d_obj['TimeStamp']+' ')
#列表连接
t.writelines(''.join(lst).replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','')) #写入解析后内容
对于一个相同的.xml.gz文件,文件总行数为173890行,其中有用数据为90079行。实测结果如下:

可以看到,在应用了list-join方式后,处理用时和StringIO方式相当,说明利用list-join方式也能够带来和StringIO相同的性能提升。
因此,推荐在编程中要避免使用过多的字符串相加,而要以list-join和StringIO代替之。
至于为什么字符串相加效率要比其他两种低那么多呢,其实我也不是很懂,但是我会搜索啊。。。
谁说python字符串相加效率低
这个看情况分析,官方文档当中也有说,相加产生的str是immutable的,如果只是两个字符串相加,并没有什么问题,但是如果是n>>1个字符串相加,这样中间会产生n-1个中间值,这些中间值都是immutable的,所以之后就是创建一个释放一个再创建下一个释放下一个。
而join在对于n个字符串相加过程中内部实现直接全部相连,就没有这种中间值了。
如果你相加的字符串不多,用加号还是更加方便的,另一方面,你选择了用Python,还真的在乎那一两秒的效率吗?
测试用的程序和文件可以到我的github页面下载,欢迎小伙伴们一起学习讨论。
xml_parser_str.py、xml_parser_list.py、xml_parser_StringIO.py
测试用例:../mro
在PYTHON中使用StringIO的性能提升实测(更新list-join对比)的更多相关文章
- python中的StringIO模块
python中的StringIO模块 标签:python StringIO 此模块主要用于在内存缓冲区中读写数据.模块是用类编写的,只有一个StringIO类,所以它的可用方法都在类中.此类中的大部分 ...
- Python中字符串操作函数string.split('str1')和string.join(ls)
Python中的字符串操作函数split 和 join能够实现字符串和列表之间的简单转换, 使用 .split()可以将字符串中特定部分以多个字符的形式,存储成列表 def split(self, * ...
- .NET 7 中 LINQ 的疯狂性能提升
LINQ 是 Language INtegrated Query 单词的首字母缩写,翻译过来是语言集成查询.它为查询跨各种数据源和格式的数据提供了一致的模型,所以叫集成查询.由于这种查询并没有制造新的 ...
- 转载:python中的StringIO模块
注意:python3中应使用io.StringIO StringIO经常被用来作为字符串的缓存,应为StringIO有个好处,他的有些接口和文件操作是一致的,也就是说用同样的代码,可以同时当成文件操作 ...
- python中日志logging模块的性能及多进程详解
python中日志logging模块的性能及多进程详解 使用Python来写后台任务时,时常需要使用输出日志来记录程序运行的状态,并在发生错误时将错误的详细信息保存下来,以别调试和分析.Python的 ...
- 禁用 Python GC,Instagram 性能提升10%
通过关闭 Python 垃圾收集(GC)机制,该机制通过收集和释放未使用的数据来回收内存,Instagram 的运行效率提高了 10 %.是的,你没听错!通过禁用 GC,我们可以减少内存占用并提高 C ...
- API设计中性能提升的10种解决方法
api的设计涉及到的方面很多, 分类是一个基本的思考方式.如果可以形成一个系列性的文字,那就从性能开始吧. 就像任何性能一样,API 性能主要取决于如何响应不同类型的请求.例如:典型的电商场景,显示用 ...
- Python性能提升小技巧
第一部分 1-使用内建函数: 你可以用Python写出高效的代码,但很难击败内建函数. 经查证. 他们非常快速 2-使用 join() 连接字符串. 你可以使用 + 来连接字符串. 但由于string ...
- async/await 的基本实现和 .NET Core 2.1 中相关性能提升
前言 这篇文章的开头,笔者想多说两句,不过也是为了以后再也不多嘴这样的话. 在日常工作中,笔者接触得最多的开发工作仍然是在 .NET Core 平台上,当然因为团队领导的开放性和团队风格的多样性(这和 ...
随机推荐
- SweetAlert – 替代 Alert 的漂亮的提示效果
Sweet Alert 是一个替代传统的 JavaScript Alert 的漂亮提示效果.SweetAlert 自动居中对齐在页面中央,不管您使用的是台式电脑,手机或平板电脑看起来效果都很棒.另外提 ...
- ScrollMe – 在网页中加入各种滚动动画效果
ScrollMe 是一款 jQuery 插件,用于给网页添加简单的滚动效果.当你向下滚动页面的时候,ScrollMe 可以缩放,旋转和平移页面上的元素.它易于设置,不需要任何自定义的 JavaScri ...
- .Net关闭数据库连接时判断ConnectionState为Open还是Closed?
两种写法: if (conn.State == System.Data.ConnectionState.Open) { conn.Close(); ...
- 微信小程序需要https后台的创业机会思考
最近比较关注微信小程序,而且微信小程序的后台必须强制要求https, https相对http成本要高很多了. 这里我感觉有2个商机 (1)提供https 中转服务器 ,按流量来收费 (2) 微信小程序 ...
- JS实现悬浮移动窗口(悬浮广告)的特效
页面加载完成之后向页面插入窗口,之后向窗口插入关闭按钮,使用setInterval()函数触发moves()函数开始动画 js方法: 复制代码代码如下: <!DOCTYPE HTML PUB ...
- Html5 dataset--自定义属性
dataset--自定义属性 HTMLElement.dataset data-*属性集 元素上保存数据 <div id="user" data-id="12345 ...
- 腾讯Tinker初入门总结
- Linux账户密码过期安全策略设置
在Linux系统管理中,有时候需要设置账号密码复杂度(长度).密码过期策略等,这个主要是由/etc/login.defs参数文件中的一些参数控制的的.它主要用于用户账号限制,里面的参数主要有下面一些: ...
- Nginx 多站点配置
最近学习和练习的时候,为Laravel应用程序添加了好几个站点,有些程序删除之后站点却还留着,这让强迫症感到非常难受,上次解决了这个问题之后并没有记录一下,于是导致今天又花了很多时间折腾,所以特地来写 ...
- 关于GUID的相关知识
全局唯一标识符(GUID,Globally Unique Identifier)是一种由算法生成的二进制长度为128位的数字标识符.GUID主要用于在拥有多个节点.多台计算机的网络或系统中.在理想情 ...