最大似然估计 (MLE) 最大后验概率(MAP)
1) 最大似然估计 MLE
给定一堆数据,假如我们知道它是从某一种分布中随机取出来的,可是我们并不知道这个分布具体的参,即“模型已定,参数未知”。 例如,我们知道这个分布是正态分布,但是不知道均值和方差;或者是二项分布,但是不知道均值。 最大似然估计(MLE,Maximum Likelihood Estimation)就可以用来估计模型的参数。MLE的目标是找出一组参数,使得模型产生出观测数据的概率最大:
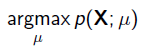
其中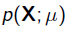 就是似然函数,表示在参数
就是似然函数,表示在参数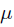 下出现观测数据的概率。我们假设每个观测数据是独立的,那么有
下出现观测数据的概率。我们假设每个观测数据是独立的,那么有
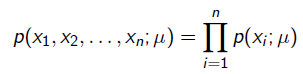
为了求导方便,一般对目标取log。 所以最优化对似然函数等同于最优化对数似然函数:
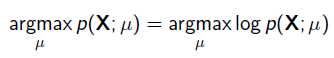
举一个抛硬币的简单例子。 现在有一个正反面不是很匀称的硬币,如果正面朝上记为H,方面朝上记为T,抛10次的结果如下:
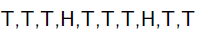
求这个硬币正面朝上的概率有多大?
很显然这个概率是0.2。现在我们用MLE的思想去求解它。我们知道每次抛硬币都是一次二项分布,设正面朝上的概率是,那么似然函数为:
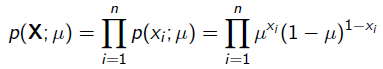
x=1表示正面朝上,x=0表示方面朝上。那么有:
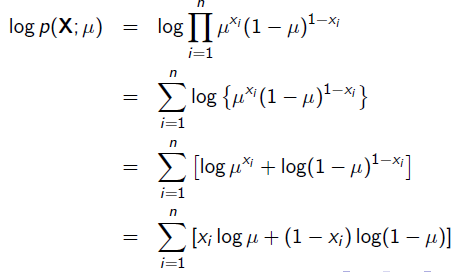
求导:
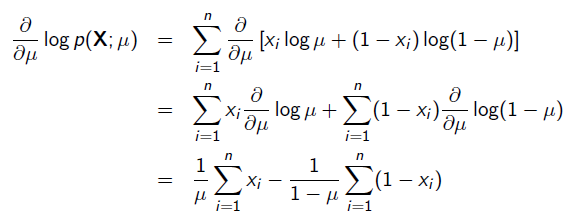
令导数为0,很容易得到:
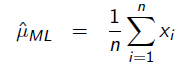
也就是0.2 。
2) 最大后验概率 MAP
以上MLE求的是找出一组能够使似然函数最大的参数,即。 现在问题稍微复杂一点点,假如这个参数有一个先验概率呢?比如说,在上面抛硬币的例子,假如我们的经验告诉我们,硬币一般都是匀称的,也就是=0.5的可能性最大,=0.2的可能性比较小,那么参数该怎么估计呢?这就是MAP要考虑的问题。 MAP优化的是一个后验概率,即给定了观测值后使概率最大:
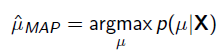
把上式根据贝叶斯公式展开:
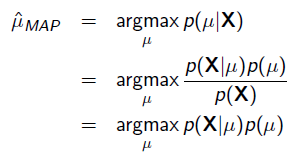
我们可以看出第一项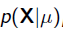 就是似然函数,第二项
就是似然函数,第二项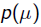 就是参数的先验知识。取log之后就是:
就是参数的先验知识。取log之后就是:
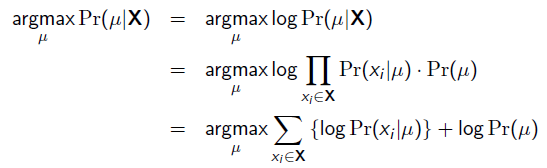
回到刚才的抛硬币例子,假设参数有一个先验估计,它服从Beta分布,即:
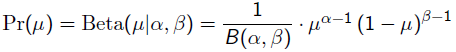
而每次抛硬币任然服从二项分布:
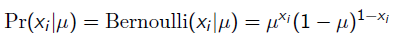
那么,目标函数的导数为:
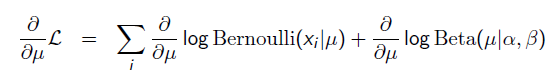
求导的第一项已经在上面MLE中给出了,第二项为:
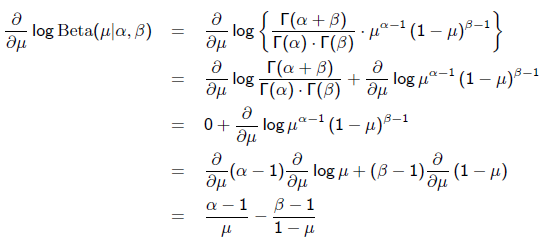
令导数为0,求解为:
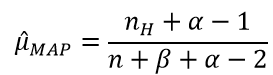
其中,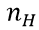 表示正面朝上的次数。这里看以看出,MLE与MAP的不同之处在于,MAP的结果多了一些先验分布的参数。
表示正面朝上的次数。这里看以看出,MLE与MAP的不同之处在于,MAP的结果多了一些先验分布的参数。
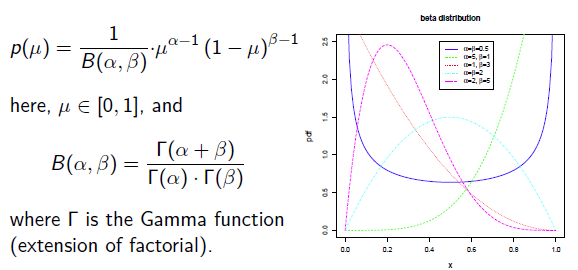
补充知识: Beta分布
Beat分布是一种常见的先验分布,它形状由两个参数控制,定义域为[0,1]
Beta分布的最大值是x等于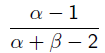 的时候:
的时候:
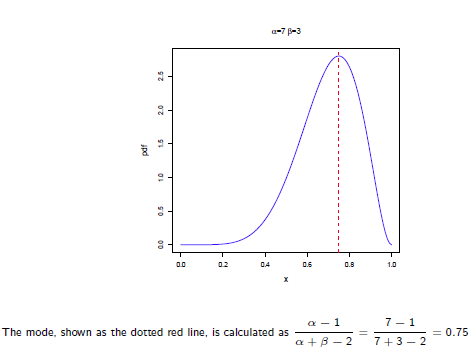
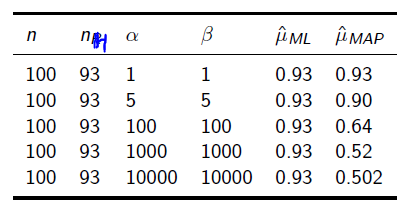
所以在抛硬币中,如果先验知识是说硬币是匀称的,那么就让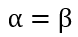 。 但是很显然即使它们相等,它两的值也对最终结果很有影响。它两的值越大,表示偏离匀称的可能性越小:
。 但是很显然即使它们相等,它两的值也对最终结果很有影响。它两的值越大,表示偏离匀称的可能性越小:
原创博客,转载请注明出处 Leavingseason http://www.cnblogs.com/sylvanas2012/p/5058065.html
最大似然估计 (MLE) 最大后验概率(MAP)的更多相关文章
- 机器学习基础系列--先验概率 后验概率 似然函数 最大似然估计(MLE) 最大后验概率(MAE) 以及贝叶斯公式的理解
目录 机器学习基础 1. 概率和统计 2. 先验概率(由历史求因) 3. 后验概率(知果求因) 4. 似然函数(由因求果) 5. 有趣的野史--贝叶斯和似然之争-最大似然概率(MLE)-最大后验概率( ...
- 最大似然估计和最大后验概率MAP
最大似然估计是一种奇妙的东西,我觉得发明这种估计的人特别才华.如果是我,觉得很难凭空想到这样做. 极大似然估计和贝叶斯估计分别代表了频率派和贝叶斯派的观点.频率派认为,参数是客观存在的,只是未知而矣. ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 萌新笔记——Cardinality Estimation算法学习(二)(Linear Counting算法、最大似然估计(MLE))
在上篇,我了解了基数的基本概念,现在进入Linear Counting算法的学习. 理解颇浅,还请大神指点! http://blog.codinglabs.org/articles/algorithm ...
- 最大似然估计(MLE)与最小二乘估计(LSE)的区别
最大似然估计与最小二乘估计的区别 标签(空格分隔): 概率论与数理统计 最小二乘估计 对于最小二乘估计来说,最合理的参数估计量应该使得模型能最好地拟合样本数据,也就是估计值与观测值之差的平方和最小. ...
- Cardinality Estimation算法学习(二)(Linear Counting算法、最大似然估计(MLE))
在上篇,我了解了基数的基本概念,现在进入Linear Counting算法的学习. 理解颇浅,还请大神指点! http://blog.codinglabs.org/articles/algorithm ...
- 补充资料——自己实现极大似然估计(最大似然估计)MLE
这篇文章给了我一个启发,我们可以自己用已知分布的密度函数进行组合,然后构建一个新的密度函数啦,然后用极大似然估计MLE进行估计. 代码和结果演示 代码: #取出MASS包这中的数据 data(geys ...
- 详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
转载声明:本文为转载文章,发表于nebulaf91的csdn博客.欢迎转载,但请务必保留本信息,注明文章出处. 原文作者: nebulaf91 原文原始地址:http://blog.csdn.net/ ...
- 最大似然估计 (MLE)与 最大后验概率(MAP)在机器学习中的应用
最大似然估计 MLE 给定一堆数据,假如我们知道它是从某一种分布中随机取出来的,可是我们并不知道这个分布具体的参,即“模型已定,参数未知”. 例如,对于线性回归,我们假定样本是服从正态分布,但是不知道 ...
随机推荐
- 个人对final发布产品的排名
结果 作品 组长 个人评委名次 个人评委平均 个人评委方差 投票数 团队评委名次 团队评委平均 团队评委方差 武志远-新蜂-俄罗斯 武志远 1 2.22 1.91 23 1 2 0.80 王森-天天向 ...
- 顺序队列的C语言实现
#include <stdio.h> #define MAXSIZE 101 #define ELEMTYPE int #define QUEUE_EMPTY -10000 typedef ...
- JSON与js对象序列化
JavaScript对象表示法(JavaScript Object Notation,简称JSON)是一种轻量级的数据交换格式,它基于js字面量表示法,是js的一个子集.虽然是一个js的子集但是他与语 ...
- tab切换(修改)
html代码: <div class="tabContent"> <ul class="tab clearFix"> <li cl ...
- Web.config自定义节点configSections
1.为什么需要自定义节点 为了增加应用程序的可移植性,通常网站需要配置一些自定义的节点,例如:文件上传的路径等,再深入的应用,可以定义工厂方法需要创建的类. 2.configSections使用方法 ...
- iOS开发--QQ音乐练习,后台播放和锁屏界面
一.设置后台播放 首先允许程序后台播放 代码实现 - (BOOL)application:(UIApplication *)application didFinishLaunchingWithOpti ...
- iPad开发--QQ空间布局,登录模块
一.登录模块 登录逻辑 - (IBAction)loginClick:(UIButton *)sender { self.view.userInteractionEnabled = NO; [self ...
- .Net Core 1.0.0正式版安装及示例教程
使用VS Code 从零开始开发调试.NET Core 1.0 RTM. .NET Core 是一个开源的.跨平台的 .NET 实现. VS Code 全称是 Visual Studio Code,V ...
- 强联通 HDU 2767 3836
n个点m条边 最少需要几条边变成强连通图 设有a个结点的入读为0, b个结点的出度为0, 则 max{a, b}就是答案. 注意特殊情况: 当原图已经强连通时, 答案是0而不是1. 加一条边少一个入度 ...
- URL详解与URL编码
作为前端,每日与 URL 打交道是必不可少的.但是也许每天只是单纯的用,对其只是一知半解,随着工作的展开,我发现在日常抓包调试,接口调用,浏览器兼容等许多方面,不深入去理解URL与URL编码则会踩到很 ...