Hive HQL基本操作
一. DDL操作 (数据定义语言)
具体参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
其实就是我们在创建表的时候用到的一些sql,比如说:CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上
1 、创建/ 删除/ 修改/使用数据库
1.1创建数据库
首先启动:
启动集群: service iptables stop zkServer.sh start start-all.sh 启动hive:
node02(服务端): hive --service metastore
node03(客户端):hive
①创建:
hive> create database lisi;
OK
Time taken: 5.271 seconds
hive> show databases;
OK
ceshi
default
lisi
mgh
shanghai
Time taken: 0.059 seconds, Fetched: 5 row(s)
②hdfs中查看:hdfs:///user/hive/warehouse
1.2 删除数据库:
①命令:drop lisi;
hive> drop database lisi;
OK
Time taken: 0.979 seconds
hive> show databases;
OK
ceshi
default
mgh
shanghai
Time taken: 0.082 seconds, Fetched: 4 row(s)
②刷新hdfs:查看结果(此时lisi.db删除!)
1.3 修改数据库
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0) ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0) ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
1.4 使用数据库:use 数据库名称 (use lisi;)
2.创建/删除表
2.1 创建表
①常见表的类型:数据类型:
data_type
primitive_type 原始数据类型
| array_type 数组
| map_type map 映射类型
| struct_type 结构类型
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
| TINYINT 非常小的整数(SQL Server数据库的一种数据类型,范围从0到255之间的整数)
| SMALLINT 短整型
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION
|STRING 基本可以搞定一切
| BINARY 二进制
| TIMESTAMP 时间戳
| DECIMAL 小数
| DECIMAL(precision, scale)
| DATE
| VARCHAR 变长字符型
| CHAR
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... >
②创建:在数据库ceshi.db中创建表:test01 ------>建议:在建表前,可以先把要建的表的信息创建好,那么根据表中所涉及的字段信息,来设计即将要创建的表:也就是根据
表内容对应设计字段类型,比如id: int等 ,后面关于row_format直接copy官网即可!
hive> create table test01(
> id int,
> name string,
> age int,
> likes array<string>,
> address map<string,string>
> )
> row format delimited fields terminated by ','
> COLLECTION ITEMS TERMINATED by '-'
> map keys terminated by ':'
> lines terminated by '\n';
OK
Time taken: 1.091 seconds
hive> show tables;
OK
abc
test01
②hdfs中查看:

③ 加载数据:在本地目录中加载
a:在root目录下新建hivedata文件夹:mkdir hivedata
b:在hivedata目录中hivedata新建文件: vim hivedata
[root@node03 hivedata]# vim hivedata
1,zshang,18,game-girl-book,stu_addr:beijing-work_addr:shanghai
2,lishi,16,shop-boy-book,stu_addr:hunan-work_addr:shanghai
3,wang2mazi,20,fangniu-eat,stu_addr:shanghai-work_addr:tianjing
4,zhangsna,23,girl-boy-game,stu_addr:songjiang-work_addr:beijing
5,lisi,65,sleep-girl,stu_addr:nanjing-work_addr:anhui
6.wanggu,45,sleep-girl,stu_addr:nanzhou-work_addr:hubei
ok!
c:加载: load data local inpath '/root/hivedata/hivedata' into table test01 /(如果是hsfs上加载: load data inpath 'hdfs://user/ceshi.db/hivedata' ('hdfs实际路径为准') into table test01 加载方法类似! )
hive> load data local inpath '/root/hivedata/hivedata' into table test01;
Loading data to table ceshi.test01
Table ceshi.test01 stats: [numFiles=1, totalSize=363]
OK
Time taken: 2.711 seconds
d:查看结果:
hive> select * from test01;
OK
1 zshang 18 ["game","girl","book"] {"stu_addr":"beijing","work_addr":"shanghai"}
2 lishi 16 ["shop","boy","book"] {"stu_addr":"hunan","work_addr":"shanghai"}
3 wang2mazi 20 ["fangniu","eat"] {"stu_addr":"shanghai","work_addr":"tianjing"}
4 zhangsna 23 ["girl","boy","game"] {"stu_addr":"songjiang","work_addr":"beijing"}
5 lisi 65 ["sleep","girl"] {"stu_addr":"nanjing","work_addr":"anhui"}
NULL 45 NULL ["stu_addr:nanzhou","work_addr:hubei"] NULL
NULL NULL NULL NULL NULL
NULL NULL NULL NULL NULL
Time taken: 0.99 seconds, Fetched: 8 row(s)
2.2 删除表: drop table 表名 (工作中慎用!)
2.3 修改表:
将abc更名为aaa:
hive> alter table abc rename to aaa;
OK
Time taken: 0.833 seconds
hive> show tables;
OK
aaa
test01
Time taken: 0.101 seconds, Fetched: 2 row(s)
2.4 更新/删除数据:本机现在安装的是hive1.2.1 不支持hive中的行级的更新/插入/删除,需要配置hive-site.xml文件
① UPDATE tablename SET column = value [, column =value ...] [WHERE expression]
② DELETE FROM tablename [WHERE expression]
参考博客:https://blog.csdn.net/wzy0623/article/details/51483674
二. DML操作(数据操作语言)
Hive 不能很好的支持用 insert 语句一条一条的进行插入操作,不支持 update 操作。数据是以 load 的方式加载到建立好的表中。数据一旦导入就不可以修改。
1.插入/导入数据:
方法一: insert overwrite table ps1 select id,name,age,likes,address from test01;
先创建新表ps1-->再插入数据:
①按照test01的表结构创建一张空表ps1:
create table ps1 like test01; ②插入:
insert overwrite table ps1 select id,name,age,likes,address from test01;
方法二: LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例如:①导入到分区表中
load data local inpath '/root/hivedata/pt01' into table eee partition(part='2018-08-09 09:04);
②在数据库mgh。db中创建表test01,并导入数据:
hive> create table test01(
> name string,
> age int,
> school string,
> project string)
> row format delimited fields terminated by ','; hive> desc test01;
OK
name string
age int
school string
project string hive> load data local inpath '/root/hivedata/pt01' into table test01; hive> select * from test01;
OK
zhangsan 25 sxt java
lisi 23 bj python
wangwu 31 dalei php
zhousi 27 laonanhai web
方法三:(基本同DDL中导入操作类似)
FROM person t1
INSERT OVERWRITE TABLE person1 [PARTITION(dt='2008-06-08', country)]
SELECT t1.id, t1.name, t1.age ;
例如:在mgh.db数据库中创建表test02,它的数据来源从表test01中插入:
hive> from test01
> insert overwrite table test02
> select name,age,school,project;
这里也可以插入多张表!
或者:
insert overwrite table test02 select name,age,school,project from test01;
2.查询并保存
2.1保存本地:将数据库mgh.db中的表test01保存到/root/hivedata中:
insert overwrite local directory '/root/hivedata' row format delimited fields terminated by ',' select * from test01; 类比:将本地目录的文件加载到表:
load data local inpath '/root/hivedata/test01' into table test02;
2.2 保存到hdfs:
insert overwrite directory '/user/hive/warehouse/hive_exp_emp' select * from test01; (hive_exp_emp 单独创建该目录用来存放上传的文件)
注:这里包括上面的插入操作涉及到MapReduce运行,因为本机性能及磁盘内存限制,导致结果无法跑出来,后来重启集群重新跑数据才成功,最佳的解决方式:为虚拟机配置内存空间,但受本机实际内存限制
暂无法实现!
2.3 备份还原数据
1.备份:将mgh.db中的表test01 备份到数据库hehe.db
hive> export table test01 to '/user/hive/warehouse/hehe.db' ;
2.删除:将mgh.db中的test01表删除,再进行恢复
hive> drop table test01;
OK
Time taken: 2.271 seconds
hive> show tables;
OK
abc
test02
test03 hive> import from '/user/hive/warehouse/hehe.db'; hive> show tables;
OK
abc
test01
test02
test03
三.分区操作
1.创建分区
1.1单分区:在mgh.db中创建带有单分区的表---test03
①创建空表
create table test03(
> name string,
> age int,
> likes string) partitioned by(part string)
> row format delimited fields terminated by ',';
OK
②新建表:vim part01
zhang,12,sing
lisi,23,drink
wanger,34,swim
zhousi,23,eat
③导入数据并查看分区:
hive> load data local inpath '/root/hivedata/part01' into table test03 partition(part='2018-08-09 16:02' );
hive> select *from test03;
OK
zhang 12 sing 2018-08-09 16:02
lisi 23 drink 2018-08-09 16:02
wanger 34 swim 2018-08-09 16:02
zhousi 23 eat 2018-08-09 16:02
1.2创建双分区表--test04
操作同test03类似:
hive> create table test04(
> name string,
> age int,
> likes string) partitioned by(year string,month string)
> row format delimited fields terminated by ',';
OK hive> show tables;
OK
abc
test01
test02
test03
test04 hive> load data local inpath '/root/hivedata/part01' into table test04 partition(year='2018' ,month='08-08' ); hive> select * from test04;
OK
zhang 12 sing 2018 08-08
lisi 23 drink 2018 08-08
wanger 34 swim 2018 08-08
zhousi 23 eat 2018 08-08
1.3 添加分区
这里添加分区不是添加分区字段,而是在原有分区字段的基础上添加新的值(内容)!
例如:ceshi.db数据库中,找到之前已建立的分区表---fenqu,它的分区字段是dt(='20180808')
现在在已有的字段dt基础再添加新的值:'2018-08-09',操作如下:
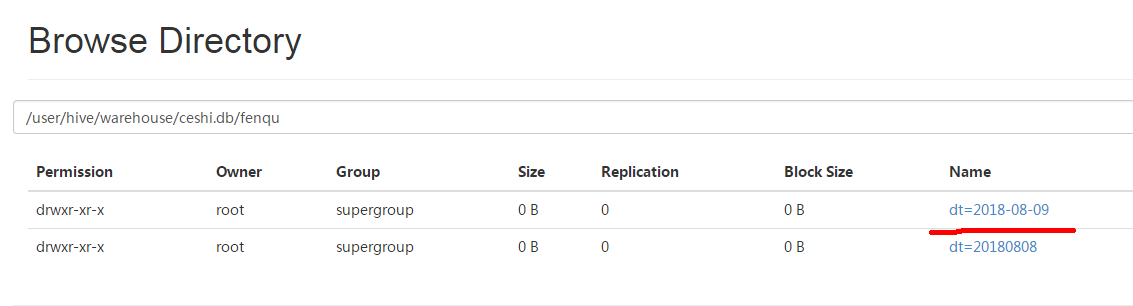
hive>alter table fenqu add partition(dt='2018-08-09'); 查看分区:
hive> show partitions fenqu;
OK
dt=2018-08-09
dt=20180808
再去hdfs集群查看:
如果多分区怎么添加:
hive> alter table fenqu add partition(dt='123456') partition(dt='8888');
OK
Time taken: 0.51 seconds
hive> show partitions fenqu;
OK
dt=112233
dt=123456
dt=2018-08-09
dt=20180808
dt=234567
dt=8888
这里多分区的添加格式:
alter table fenqu add partition(dt='xxxx') partition(dt='xxxx')....;
1.4 删除分区
现在将之前乱七八糟建的分区统统删除,如下:
hive> alter table fenqu drop partition(dt=''), partition(dt=''), partition(dt=''), partition(dt='');
Dropped the partition dt=112233
Dropped the partition dt=123456
Dropped the partition dt=234567
Dropped the partition dt=8888
OK
Time taken: 4.033 seconds hive> show partitions fenqu;
OK
dt=2018-08-09
dt=20180808
Time taken: 0.396 seconds, Fetched: 2 row(s) 这里删除的格式:
alter table fenqu drop partition(dt='xxx'), partition(dt='xxx'), partition(dt='xxx'), partition(dt='xxx').....;
1.5 加载数据到分区:
例如:将/root/hivedata/test01 表的数据,加载到数据库ceshi.db中的fenqu表,如下:
hive> load data local inpath '/root/hivedata/test01' into table fenqu partition(dt='2018-08-09', dt='20180808');
Loading data to table ceshi.fenqu partition (dt=2018-08-09)
Partition ceshi.fenqu{dt=2018-08-09} stats: [numFiles=1, totalSize=83]
OK
Time taken: 8.112 seconds
hive> select *from fenqu;
OK
NULL 25 2018-08-09
NULL 23 2018-08-09
NULL 31 2018-08-09
NULL 27 2018-08-09
1 lier 20180808
2 wanger 20180808
3 zhanger 20180808
4 zhouer 20180808
5 qier 20180808
Time taken: 0.394 seconds, Fetched: 9 row(s)
1.6 重命名分区:
hive> alter table fenqu partition(dt='2018-08-10',dt='20180808') rename to partition(dt='2018-08-10 00:05',dt='20180810 12:05');
OK
Time taken: 1.158 seconds
hive> show partitions fenqu;
OK
dt=2018-08-10
dt=2018-08-10 00%3A05
Time taken: 0.297 seconds, Fetched: 2 row(s)
1.7 动态分区
流程:①在/root/hivedata/创建一个数据文件aaa.txt (方便导入到后面的表中)
② 设置相关参数:hive.exec.dynamic.partition(默认关闭动态分区:false,需要设为true) /hive.exec.dynamic.partition.mode(默认分区模式:strict,需要设置为:nonstrict)
/hive.exec.max.dynamic.partitions.pernode(默认每个节点最大分区数为100,需要根据实际需要来调整) /hive.exec.max.dynamic.partitions(在所有节点最大默认分区数:1000,需要根据实际来调整,不然会报错!)
hive.exec.max.created.files(在整个mr任务中默认可以创建10万个hdfs文件,也可以调整一般足够了) /hive.error.on.empty.partition(当生成空文件时,默认不抛出错误)
③在数据库ceshi.db中创建一张非分区表---test05 ,同时再创建另一张外表(external table) -----test06并将test05的表内容导入test06.
具体:
vim aaa.txt
aa,US,CA
aaa,US,CB
bbb,CA,BB
bbb,CA,BC
------------------------参数设置--------------------------
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=100;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.max.created.files=100000;
set hive.error.on.empty.partition=flase;
-------------------------------创建非分区表test05----------------------------------
create table test05(name string,cty string,st string)row format delimited fields terminated by ','; ---------------------------------创建外表test06--------------------------------
create external table test06(name string)partitioned by(country string,state string); ----------------------------从表test05加载数据到test06-------------------------------
insert table test06 partition(country,state) select name,cty,st from test05;
-----------------------------------检查分区-------------
hive> show partitions test06;
OK
country=CA/state=BB
country=CA/state=BC
country=US/state=CA
country=US/state=CB
注:也可以去集群里查看!
Hive HQL基本操作的更多相关文章
- Hive的基本操作和数据类型
Hive的基本操作 1.启动Hive bin/hive 2.查看数据库 hive>show databases; 3. 打开默认数据库 hive>use default; 4.显示defa ...
- 【Hadoop离线基础总结】Hive的基本操作
Hive的基本操作 创建数据库与创建数据库表 创建数据库的相关操作 创建数据库:CREATE TABLE IF NOT EXISTS myhive hive创建表成功后的存放位置由hive-site. ...
- Hive HQL学习
HQL学习 1.hive的数据类型 2.hive_DDL 2.1创建.删除.修改.使用数据库 Default数据库,默认的,优先级相对于其他数据库是最高的 2.2重点:创建表_内部表_ ...
- hive的基本操作与应用
通过hadoop上的hive完成WordCount 启动hadoop Hdfs上创建文件夹 创建文件夹 上传文件至hdfs 启动Hive 创建原始文档表 导入文件内容到表docs并查看 用HQL进行词 ...
- hive的基本操作
1.创建表 First, create a table with tab-delimited text file format: (1)CREATE TABLE u_data ( userid INT ...
- Hive之基本操作
1,CREATE table. CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col ...
- Hive:HQL和Mysql:SQL 的区别
HQL: group by 后面的参数一定要和select非聚集函数一致 where 1 要改成 where 1 = 1
- Hive(二)hive的基本操作
一.DDL操作(定义操作) 1.创建表 (1)建表语法结构 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type ...
- 2、hive的基本操作
1.创建数据库和表 1)创建数据库 hive> CREATE DATABASE IF NOT EXISTS userdb; OK Time taken: 0.252 seconds hive&g ...
随机推荐
- SpringMVC与shiro集成及配置文件说明!
在项目中xml文件的配置是必不可少的,特别是SpringMVC框架.但是几乎所有项目的配置都是大同小异,很多人都是直接复制黏贴了事,不少人对其具体含义及用途都不甚全知.本片文章将正对项目中常用的框架S ...
- 在 Windows Server Container 中运行 Azure Storage Emulator(一):能否监听自定义地址?
我要做什么? 改 ASE 的监听地址.对于有强迫症的我来说,ASE 默认监听的是 127.0.0.1:10000-10002,这让我无法接受,所以我要将它改成域名 + 80 端口的方式: 放到容器中. ...
- JQuery学习---JQuery深入学习
属性操作 $("p").text() $("p").html() $(":checkbox").val() $(".te ...
- SP2-0734: unknown command beginning "lsnrctl st..." - rest of line ignored.
SP2-0734: unknown command beginning "lsnrctl st..." - rest of line ignored. Cause(原因):Comm ...
- JAXB实现java对象与xml之间转换
JAXB简介: 1.JAXB能够使用Jackson对JAXB注解的支持实现(jackson-module-jaxb-annotations),既方便生成XML,也方便生成JSON,这样一来可以更好的标 ...
- 激活老电脑的第二春:内存盘为Chrome浏览器做缓存
AMD Radeon RAMDisk 4.2.1 正式版 下载地址:http://dl.pconline.com.cn/html_2/1/73/id=7204&pn=0.html 适用于:wi ...
- 异常处理与MiniDump详解(1) C++异常(转)
异常处理与MiniDump详解(1) C++异常 write by 九天雁翎(JTianLing) -- blog.csdn.net/vagrxie 讨论新闻组及文件 一. 综述 我很少敢为自己写 ...
- python内置模块(三)
hashlib模块 通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示). Python2中使用hashlib: import hashlib m = hashlib ...
- (六)Linux下的压缩命令
======================================================================================== .zip格式的压缩和解 ...
- 苹果浏览器样式重置submit
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/XTQueen_up/article/details/34446541 大家刚接触写手机页面 也许都会 ...