Oracle表分区分为四种:范围分区,散列分区,列表分区和复合分区(转载)
一:范围分区
就是根据数据库表中某一字段的值的范围来划分分区,例如:

1 create table graderecord
2 (
3 sno varchar2(10),
4 sname varchar2(20),
5 dormitory varchar2(3),
6 grade int
7 )
8 partition by range(grade)
9 (
10 partition bujige values less than(60), --不及格
11 partition jige values less than(85), --及格
12 partition youxiu values less than(maxvalue) --优秀
13 )
插入实验数据:
1 insert into graderecord values('511601','魁','229',92);
2 insert into graderecord values('511602','凯','229',62);
3 insert into graderecord values('511603','东','229',26);
4 insert into graderecord values('511604','亮','228',77);
5 insert into graderecord values('511605','敬','228',47);
6 insert into graderecord(sno,sname,dormitory) values('511606','峰','228');
7 insert into graderecord values('511607','明','240',90);
8 insert into graderecord values('511608','楠','240',100);
9 insert into graderecord values('511609','涛','240',67);
10 insert into graderecord values('511610','博','240',75);
11 insert into graderecord values('511611','铮','240',60);
下面查询一下全部数据,然后查询各个分区数据,代码一起写:
1 select * from graderecord;
2 select * from graderecord partition(bujige);
3 select * from graderecord partition(jige);
4 select * from graderecord partition(youxiu);
全部数据如下:


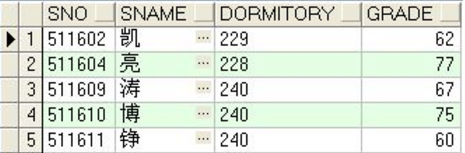

说明:数据中有空值,Oracle机制会自动将其规划到maxvalue的分区中。
二:散列分区
散列分区是根据字段的hash值进行均匀分布,尽可能的实现各分区所散列的数据相等。
还是刚才那个表,只不过把范围分区改换为散列分区,语法如下(删除表之后重建):
1 create table graderecord
2 (
3 sno varchar2(10),
4 sname varchar2(20),
5 dormitory varchar2(3),
6 grade int
7 )
8 partition by hash(sno)
9 (
10 partition p1,
11 partition p2,
12 partition p3
13 );
插入实验数据,与范围分区实验插入的数据相同。
然后查询分区数据:
1 select * from graderecord partition(p1);
2 select * from graderecord partition(p2);
3 select * from graderecord partition(p3);
p1分区的数据:

p2分区的数据:
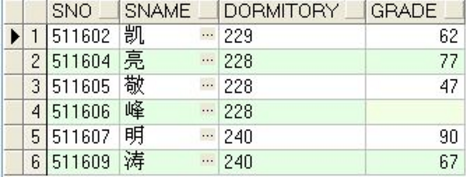
p3分区的数据:

说明:散列分区即为哈希分区,Oracle采用哈希码技术分区,具体分区如何由Oracle说的算,也可能我下一次搜索就不是这个数据了。
三:列表分区
列表分区明确指定了根据某字段的某个具体值进行分区,而不是像范围分区那样根据字段的值范围来划分的。
1 create table graderecord
2 (
3 sno varchar2(10),
4 sname varchar2(20),
5 dormitory varchar2(3),
6 grade int
7 )
8 partition by list(dormitory)
9 (
10 partition d229 values('229'),
11 partition d228 values('228'),
12 partition d240 values('240')
13 )
以上根据宿舍来进行列表分区,插入与范围分区实验相同的数据,做查询如下:
1 select * from graderecord partition(d229);
2 select * from graderecord partition(d228);
3 select * from graderecord partition(d240);
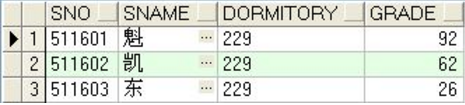
d229分区所得数据如下:
d228分区所得数据如下:
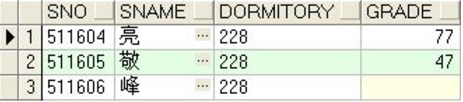
d240分区所得数据如下:

四:复合分区 (范围-散列分区,范围-列表分区)
首先讲范围-散列分区。先声明一下:列表分区不支持多列,但是范围分区和哈希分区支持多列。
代码如下:
1 create table graderecord
2 (
3 sno varchar2(10),
4 sname varchar2(20),
5 dormitory varchar2(3),
6 grade int
7 )
8 partition by range(grade)
9 subpartition by hash(sno,sname)
10 (
11 partition p1 values less than(75)
12 (
13 subpartition sp1,subpartition sp2
14 ),
15 partition p2 values less than(maxvalue)
16 (
17 subpartition sp3,subpartition sp4
18 )
19 );
以grade划分范围,然后以sno和sname划分散列分区,当数据量大的时候散列分区则趋于“平均”。
插入数据:
1 insert into graderecord values('511601','魁','229',92);
2 insert into graderecord values('511602','凯','229',62);
3 insert into graderecord values('511603','东','229',26);
4 insert into graderecord values('511604','亮','228',77);
5 insert into graderecord values('511605','敬','228',47);
6 insert into graderecord(sno,sname,dormitory) values('511606','峰','228');
7 insert into graderecord values('511607','明','240',90);
8 insert into graderecord values('511608','楠','240',100);
9 insert into graderecord values('511609','涛','240',67);
10 insert into graderecord values('511610','博','240',75);
11 insert into graderecord values('511611','铮','240',60);
12 insert into graderecord values('511612','狸','244',72);
13 insert into graderecord values('511613','杰','244',88);
14 insert into graderecord values('511614','萎','244',19);
15 insert into graderecord values('511615','猥','244',65);
16 insert into graderecord values('511616','丹','244',59);
17 insert into graderecord values('511617','靳','244',95);
查询如下:
1 select * from graderecord partition(p1);
2 select * from graderecord partition(p2);
3 select * from graderecord subpartition(sp1);
4 select * from graderecord subpartition(sp2);
5 select * from graderecord subpartition(sp3);
6 select * from graderecord subpartition(sp4);
分区p1数据如下,本例中75分以下:

分区p2数据如下,本例中75分之上包括75分:

子分区sp1:

子分区sp2:

子分区sp3:

子分区sp4:

说明:当数据量越来越大时,哈希分区的分区表中数据越来越趋于平衡。
下面讲范围-列表分区
范围-列表分区有两种创立方式,先说说没有模板的创建方式,这个表我要重建:
1 create table MobileMessage
2 (
3 ACCT_MONTH VARCHAR2(6), -- 帐期 格式:年月 YYYYMM
4 AREA_NO VARCHAR2(10), -- 地域号码
5 DAY_ID VARCHAR2(2), -- 本月中的第几天 格式 DD
6 SUBSCRBID VARCHAR2(20), -- 用户标识
7 SVCNUM VARCHAR2(30) -- 手机号码
8 )
9 partition by range(ACCT_MONTH,AREA_NO) subpartition by list(DAY_ID)
10 (
11 partition p1 values less than('200705','012')
12 (
13 subpartition shangxun1 values('01','02','03','04','05','06','07','08','09','10'),
14 subpartition zhongxun1 values('11','12','13','14','15','16','17','18','19','20'),
15 subpartition xiaxun1 values('21','22','23','24','25','26','27','28','29','30','31')
16 ),
17 partition p2 values less than('200709','014')
18 (
19 subpartition shangxun2 values('01','02','03','04','05','06','07','08','09','10'),
20 subpartition zhongxun2 values('11','12','13','14','15','16','17','18','19','20'),
21 subpartition xiaxun2 values('21','22','23','24','25','26','27','28','29','30','31')
22 ),
23 partition p3 values less than('200801','016')
24 (
25 subpartition shangxun3 values('01','02','03','04','05','06','07','08','09','10'),
26 subpartition zhongxun3 values('11','12','13','14','15','16','17','18','19','20'),
27 subpartition xiaxun3 values('21','22','23','24','25','26','27','28','29','30','31')
28 )
29 )
插入实验数据:
1 insert into MobileMessage values('200701','010','04','ghk001','13800000000');
2 insert into MobileMessage values('200702','015','12','myx001','13633330000');
3 insert into MobileMessage values('200703','015','24','hjd001','13300000000');
4 insert into MobileMessage values('200704','010','04','ghk001','13800000000');
5 insert into MobileMessage values('200705','010','04','ghk001','13800000000');
6 insert into MobileMessage values('200705','011','18','sxl001','13222000000');
7 insert into MobileMessage values('200706','011','21','sxl001','13222000000');
8 insert into MobileMessage values('200706','012','11','tgg001','13800044400');
9 insert into MobileMessage values('200707','010','04','ghk001','13800000000');
10 insert into MobileMessage values('200708','012','24','tgg001','13800044400');
11 insert into MobileMessage values('200709','014','29','zjj001','13100000000');
12 insert into MobileMessage values('200710','014','29','zjj001','13100000000');
13 insert into MobileMessage values('200711','014','29','zjj001','13100000000');
14 insert into MobileMessage values('200711','013','30','wgc001','13444000000');
15 insert into MobileMessage values('200712','013','30','wgc001','13444000000');
16 insert into MobileMessage values('200712','010','30','ghk001','13800000000');
17 insert into MobileMessage values('200801','015','22','myx001','13633330000');
查询结果如下:
1 select * from MobileMessage;

分区p1查询结果如下:

分区p2查询结果如下:

子分区xiaxun2查询结果如下:

说明:范围分区 range(A,B)的分区法则,范围分区都是 values less than(A,B)的,通常情况下以A为准,如果小于A的不用考虑B,直接插进去,如果等于A那么考虑B,要是满足B的话也插进去。
另一种范围-列表分区,包含模板的(比较繁琐,但是更加精确,处理海量存储数据十分必要):
1 create table MobileMessage
2 (
3 ACCT_MONTH VARCHAR2(6), -- 帐期 格式:年月 YYYYMM
4 AREA_NO VARCHAR2(10), -- 地域号码
5 DAY_ID VARCHAR2(2), -- 本月中的第几天 格式 DD
6 SUBSCRBID VARCHAR2(20), -- 用户标识
7 SVCNUM VARCHAR2(30) -- 手机号码
8 )
9 partition by range(ACCT_MONTH,AREA_NO) subpartition by list(DAY_ID)
10 subpartition template
11 (
12 subpartition sub1 values('01'),subpartition sub2 values('02'),
13 subpartition sub3 values('03'),subpartition sub4 values('04'),
14 subpartition sub5 values('05'),subpartition sub6 values('06'),
15 subpartition sub7 values('07'),subpartition sub8 values('08'),
16 subpartition sub9 values('09'),subpartition sub10 values('10'),
17 subpartition sub11 values('11'),subpartition sub12 values('12'),
18 subpartition sub13 values('13'),subpartition sub14 values('14'),
19 subpartition sub15 values('15'),subpartition sub16 values('16'),
20 subpartition sub17 values('17'),subpartition sub18 values('18'),
21 subpartition sub19 values('19'),subpartition sub20 values('20'),
22 subpartition sub21 values('21'),subpartition sub22 values('22'),
23 subpartition sub23 values('23'),subpartition sub24 values('24'),
24 subpartition sub25 values('25'),subpartition sub26 values('26'),
25 subpartition sub27 values('27'),subpartition sub28 values('28'),
26 subpartition sub29 values('29'),subpartition sub30 values('30'),
27 subpartition sub31 values('31')
28 )
29 (
30 partition p_0701_010 values less than('200701','011'),
31 partition p_0701_011 values less than('200701','012'),
32 partition p_0701_012 values less than('200701','013'),
33 partition p_0701_013 values less than('200701','014'),
34 partition p_0701_014 values less than('200701','015'),
35 partition p_0701_015 values less than('200701','016'),
36 partition p_0702_010 values less than('200702','011'),
37 partition p_0702_011 values less than('200702','012'),
38 partition p_0702_012 values less than('200702','013'),
39 partition p_0702_013 values less than('200702','014'),
40 partition p_0702_014 values less than('200702','015'),
41 partition p_0702_015 values less than('200702','016'),
42 partition p_0703_010 values less than('200703','011'),
43 partition p_0703_011 values less than('200703','012'),
44 partition p_0703_012 values less than('200703','013'),
45 partition p_0703_013 values less than('200703','014'),
46 partition p_0703_014 values less than('200703','015'),
47 partition p_0703_015 values less than('200703','016'),
48 partition p_0704_010 values less than('200704','011'),
49 partition p_0704_011 values less than('200704','012'),
50 partition p_0704_012 values less than('200704','013'),
51 partition p_0704_013 values less than('200704','014'),
52 partition p_0704_014 values less than('200704','015'),
53 partition p_0704_015 values less than('200704','016'),
54 partition p_0705_010 values less than('200705','011'),
55 partition p_0705_011 values less than('200705','012'),
56 partition p_0705_012 values less than('200705','013'),
57 partition p_0705_013 values less than('200705','014'),
58 partition p_0705_014 values less than('200705','015'),
59 partition p_0705_015 values less than('200705','016'),
60 partition p_0706_010 values less than('200706','011'),
61 partition p_0706_011 values less than('200706','012'),
62 partition p_0706_012 values less than('200706','013'),
63 partition p_0706_013 values less than('200706','014'),
64 partition p_0706_014 values less than('200706','015'),
65 partition p_0706_015 values less than('200706','016'),
66 partition p_0707_010 values less than('200707','011'),
67 partition p_0707_011 values less than('200707','012'),
68 partition p_0707_012 values less than('200707','013'),
69 partition p_0707_013 values less than('200707','014'),
70 partition p_0707_014 values less than('200707','015'),
71 partition p_0707_015 values less than('200707','016'),
72 partition p_0708_010 values less than('200708','011'),
73 partition p_0708_011 values less than('200708','012'),
74 partition p_0708_012 values less than('200708','013'),
75 partition p_0708_013 values less than('200708','014'),
76 partition p_0708_014 values less than('200708','015'),
77 partition p_0708_015 values less than('200708','016'),
78 partition p_0709_010 values less than('200709','011'),
79 partition p_0709_011 values less than('200709','012'),
80 partition p_0709_012 values less than('200709','013'),
81 partition p_0709_013 values less than('200709','014'),
82 partition p_0709_014 values less than('200709','015'),
83 partition p_0709_015 values less than('200709','016'),
84 partition p_0710_010 values less than('200710','011'),
85 partition p_0710_011 values less than('200710','012'),
86 partition p_0710_012 values less than('200710','013'),
87 partition p_0710_013 values less than('200710','014'),
88 partition p_0710_014 values less than('200710','015'),
89 partition p_0710_015 values less than('200710','016'),
90 partition p_0711_010 values less than('200711','011'),
91 partition p_0711_011 values less than('200711','012'),
92 partition p_0711_012 values less than('200711','013'),
93 partition p_0711_013 values less than('200711','014'),
94 partition p_0711_014 values less than('200711','015'),
95 partition p_0711_015 values less than('200711','016'),
96 partition p_0712_010 values less than('200712','011'),
97 partition p_0712_011 values less than('200712','012'),
98 partition p_0712_012 values less than('200712','013'),
99 partition p_0712_013 values less than('200712','014'),
100 partition p_0712_014 values less than('200712','015'),
101 partition p_0712_015 values less than('200712','016'),
102 partition p_0801_010 values less than('200801','011'),
103 partition p_0801_011 values less than('200801','012'),
104 partition p_0801_012 values less than('200801','013'),
105 partition p_0801_013 values less than('200801','014'),
106 partition p_0801_014 values less than('200801','015'),
107 partition p_0801_015 values less than('200801','016'),
108 partition p_other values less than(maxvalue, maxvalue)
109 );
这个是带有模板子分区的,模板子分区详细到月中的天。这种分区模式只要建立了分区就会自动创建子分区的。
插入上面不带模板分区实验相同的数据,随机查询分区数据:
查询分区p_0701_010的数据:
1 select * from MobileMessage partition(p_0701_010);
查询结果:

查询子分区p_0701_010_sub4的数据:
1 select * from MobileMessage subpartition(p_0701_010_sub4);
查询结果如下:

查询分区p_0706_011的数据:
1 select * from MobileMessage partition(p_0706_011);
查询结果如下:

查询子分区p_0706_011_sub21的数据:
1 select * from MobileMessage subpartition(p_0706_011_sub21);
查询结果如下:

下面讲讲分区的维护操作:
(1)分裂分区,以第一个范围分区为例:
1 alter table graderecord split partition jige at(75)
2 into(partition keyi,partition lianghao);
把分区及格分裂为两个分区:可以和良好。
(2)合并分区,以第一个范围分区为例:
1 alter table graderecord merge partitions keyi,lianghao
2 into partition jige;
把可以和良好两个分区合并为及格。
(3)添加分区,由于在范围分区上添加分区要求添加的分区范围大于原有分区最大值,但原有分区最大值已经为maxvalue,故本处以第二个散列分区为例:
1 alter table graderecord add partition p4;
给散列分区例子又增加了一个分区p4 。
(4)删除分区,语法:
1 alter table table_name drop partition partition_name;
(5)截断分区,清空分区中的数据
1 alter table table_name truncate partition partition_name;
说明:对待分区的操作同样可以对待子分区,效果一样。删除一个分区会同时删除其下的子分区。合并多个分区也会把他们的子分区自动合并。分裂分区时注意分裂点。
另外不带模板子分区和带有模板子分区的分区表操作的区别:带有子分区模板的分区表在添加分区时候自动添加子分区,不带模板子分区的分区表没有这个功能;带有子分区模板的分区表在更改分区时只需更改分区,不带模板子分区的分区表在更改分区时一定注意连同子分区一起更改。
Oracle表分区分为四种:范围分区,散列分区,列表分区和复合分区(转载)的更多相关文章
- kafka数据分区的四种策略
kafka的数据的分区 探究的是kafka的数据生产出来之后究竟落到了哪一个分区里面去了 第一种分区策略:给定了分区号,直接将数据发送到指定的分区里面去 第二种分区策略:没有给定分区号,给定数据的ke ...
- 领域模型中的实体类分为四种类型:VO、DTO、DO、PO
http://kb.cnblogs.com/page/522348/ 由于不同的项目和开发人员有不同的命名习惯,这里我首先对上述的概念进行一个简单描述,名字只是个标识,我们重点关注其概念: 概念: V ...
- 域模型中的实体类分为四种类型:VO、DTO、DO、PO
经常会接触到VO,DO,DTO的概念,本文从领域建模中的实体划分和项目中的实际应用情况两个角度,对这几个概念进行简析. 得出的主要结论是:在项目应用中,VO对应于页面上需要显示的数据(表单),DO对应 ...
- 转:领域模型中的实体类分为四种类型:VO、DTO、DO、PO
经常会接触到VO,DO,DTO的概念,本文从领域建模中的实体划分和项目中的实际应用情况两个角度,对这几个概念进行简析.得出的主要结论是:在项目应用中,VO对应于页面上需要显示的数据(表单),DO对应于 ...
- JavaScript表单提交四种方式
总结JavaScript表单提交四种方式 <!DOCTYPE html> <html> <head> <title>JavaScript表单提交四种方式 ...
- 远离“精神乞丐”(IBM的前CEO郭士纳把员工分为四种类型)
语音丨吴伯凡 乞丐与其说是一种身份, 不如说是一种精神状态, 习惯性索取且心安理得, 习惯性寻求安慰,习惯性抱怨, 与之截然对立的, 是“操之在我”(Proactive)的精神, 乞丐型员工是公司内部 ...
- 数据结构---哈希表的C语言实现(闭散列)
原文地址:https://blog.csdn.net/weixin_40331034/article/details/79461705 构造一种存储结构,通过某种函数(hashFunc)使元素的存储位 ...
- oracle增加表空间的四种方法,查询表空间使用情况
增加表空间大小的四种方法Meathod1:给表空间增加数据文件ALTER TABLESPACE app_data ADD DATAFILE'D:\ORACLE\PRODUCT\10.2.0\ORADA ...
- oracle增加表空间的四种方法
1. 查看所有表空间大小 select tablespace_name,sum(bytes)/1024/1024 from dba_data_files group by tablespace_nam ...
随机推荐
- react context toggleButton demo
//toggleButton demo: //code: //1.Appb.js: import React from 'react'; import {ThemeContext, themes} f ...
- 一款基于HTML5的高性能WEBGIS介绍
远景地理信息系统(RemoteGIS)是一款基于HTML5的GIS平台软件,它使用Javascript开发,旨在解决当前WEBGIS矢量数据在数据量和刷新性能上的瓶颈,并利用WEB程序的跨平台特性,打 ...
- Qt Quick程序的发布
要将程序发布出去,首先需要使用release方式编译程序,然后将生成的.exe可执行文件和需要的库文件发在一起打包进行发布. 要确定需要哪些动态库文件,可以直接双击.exe文件,提示缺少那个dll文件 ...
- GDAL读取影像并插值
影像读取 并缩放 读取大影像某一部分,并缩放到指定大小,我们有时会用如下代码: #include "gdal.h" #include "gdal_priv.h" ...
- mysql性能问题小解 Converting HEAP to MyIsam create_myisa
安定北京被性能测试困扰了N天,实在没想法去解决了,今天又收到上级的命令说安定北京要解决,无奈!把项目组唯一的DBA辞掉了,现在所以数据库的问题都得自己来处理:( 不知道上边人怎么想的.而且更不知道怎安 ...
- Android Fragment重要函数
Fragment的常用函数: 一.Fragment对象 1.void setArguments(Bundle args); 这个函数为Fragment提供构造参数(也就是数据),参数以Bundle类型 ...
- 适用于 Windows 的虚拟机扩展和功能
Azure 虚拟机扩展是小型应用程序,可在Azure 虚拟机上提供部署后配置和自动化任务. 例如,如果虚拟机要求安装软件.防病毒保护或进行 Docker 配置,便可以使用 VM 扩展来完成这些任务. ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 同时对view延时执行两个动画时候的现象
同时对view延时执行两个动画时候的现象 对于view延时执行了两个动画后,会将第一个动画效果终止了,直接在第一个动画的view的最后的状态上接执行后续的动画效果,也就是说,我们可以利用这个特性来写分 ...
- Java学习---Java面试基础考核·
Java中sleep和wait的区别 ① 这两个方法来自不同的类分别是,sleep来自Thread类,和wait来自Object类. sleep是Thread的静态类方法,谁调用的谁去睡觉,即使在a线 ...