Hadoop集群(第2期)_机器信息分布表
1、分布式环境搭建
采用4台安装Linux环境的机器来构建一个小规模的分布式集群。
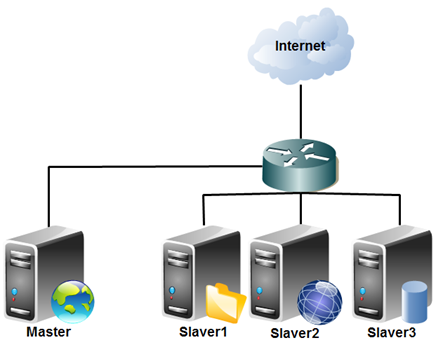
图1 集群的架构
其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点。这四台机器彼此间通过路由器相连,从而实验相互通信以及数据传输。它们都可以通过路由器访问Internet,实验网页文档的采集。
2、集群机器详细信息
2.1 Master服务器
|
名称 |
详细信息 |
|
机器名称 |
Master.Hadoop |
|
机器IP地址 |
192.168.1.2 |
|
最高用户名称(Name) |
root |
|
最用用户密码(PWD) |
hadoop(全小写) |
|
一般用户名称(Name) |
hadoop(全小写) |
|
一般用户密码(PWD) |
hadoop(全小写) |
2.2 Slave1服务器
|
名称 |
详细信息 |
|
机器名称 |
Slave1.Hadoop |
|
机器IP地址 |
192.168.1.3 |
|
最高用户名称(Name) |
root |
|
最用用户密码(PWD) |
hadoop(全小写) |
|
一般用户名称(Name) |
hadoop(全小写) |
|
一般用户密码(PWD) |
hadoop(全小写) |
2.3 Slave2服务器
|
名称 |
详细信息 |
|
机器名称 |
Slave2.Hadoop |
|
机器IP地址 |
192.168.1.4 |
|
最高用户名称(Name) |
root |
|
最用用户密码(PWD) |
hadoop(全小写) |
|
一般用户名称(Name) |
hadoop(全小写) |
|
一般用户密码(PWD) |
hadoop(全小写) |
2.4 Slave3服务器
|
名称 |
详细信息 |
|
机器名称 |
Slave3.Hadoop |
|
机器IP地址 |
192.168.1.5 |
|
最高用户名称(Name) |
root |
|
最用用户密码(PWD) |
hadoop(全小写) |
|
一般用户名称(Name) |
hadoop(全小写) |
|
一般用户密码(PWD) |
hadoop(全小写) |
备注:
添加新用户命令:useradd;修改新用户密码:passwd 用户名
退出当前用户:exit; 登录root用户:su –
3、集群机器实际布局
下面是几张Hadoop集群实际机器的部署情况,可以从图中看到那时的我们怎么实际配置Hadoop集群的。
3.1 Hadoop工作集群
该Hadoop集群机器是学习和研究之用,上面运行着已经搭建好的的Hadoop平台以及运行着一些实际程序。

图3.1-1 Hadoop工作集群部署图(1)

图3.1-2 Hadoop工作集群部署图(2)
上面从两个角度来分别观察Hadoop集群部署,作为Hadoop集群的Master节点,用的是机器较为不错的新Dell,而三台Slave机器则是实验室淘汰的旧Lenovo,用一个小路由器他们组成了一个局域网。

图3.1-3 路由器特写
3.2 Hadoop实验集群
为了方便新成员练习Hadoop技术,又防止在实际Hadoop集群上破坏已运行的程序,故另外弄了两台旧Lenovo电脑组成:一个"主——TMaster";一个"辅——TSlave"。

图3.2-1 Hadoop实验集群部署
上面就是实验室Hadoop集群的样子,虽然很简陋,但足够学习用了。
Hadoop集群(第2期)_机器信息分布表的更多相关文章
- Hadoop集群(第3期)机器信息分布表
1.分布式环境搭建 采用4台安装Linux环境的机器来构建一个小规模的分布式集群. 图1 集群的架构 其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点.这四台机器彼 ...
- Hadoop(2)_机器信息分布表
1.分布式环境搭建 采用4台安装Linux环境的机器来构建一个小规模的分布式集群. 图1 集群的架构 其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点.这四台机器彼 ...
- Hadoop集群(第1期)_CentOS安装配置
CentOS 是什么? CentOS是一个基于Red Hat 企业级 Linux 提供的可自由使用的源代码企业级的 Linux 发行版本.每个版本的 CentOS 都会获得七年的支持(通过安全更新方式 ...
- Hadoop集群(第1期)CentOS安装配置
1.准备安装 1.1 系统简介 CentOS 是什么? CentOS是一个基于Red Hat 企业级 Linux 提供的可自由使用的源代码企业级的 Linux 发行版本.每个版本的 CentOS 都会 ...
- [转]大数据hadoop集群硬件选择
问题导读 1.哪些情况会遇到io受限制? 2.哪些情况会遇到cpu受限制? 3.如何选择机器配置类型? 4.为数据节点/任务追踪器提供的推荐哪些规格? 随着Apache Hadoop的起步,云客户 ...
- 为你的 Hadoop 集群选择合适的硬件
随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hadoop集群选择合适的硬件. 尽管Hadoop被设计为运行在行业标准的硬件上,提出一个理想的集群配置不想提供硬件 ...
- 为Hadoop集群选择合适的硬件配置
随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hadoop集群选择合适的硬件. 尽管Hadoop被设计为运行在行业标准的硬件上,提出一个理想的集群配置不想提供硬件 ...
- Hadoop集群中添加硬盘
Hadoop工作节点扩展硬盘空间 接到老板任务,Hadoop集群中硬盘空间不够用,要求加一台机器到Hadoop集群,并且每台机器在原有基础上加一块2T硬盘,老板给力啊,哈哈. 这些我把完成这项任务的步 ...
- hadoop(二)hadoop集群的搭建
一.集群环境准备工作 1.修改主机名 在root 账户下 vi /etc/sysconfig/network 或者 sudo vi /etc/sysconfig/network 2.设置系统默认启 ...
随机推荐
- HDU1014Uniform Generator
Uniform Generator Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u ...
- sublime 3 注册码
Sublime_Text_Build_3080_x64_Setup.e... 下载地址: http://download.csdn.net/detail/hyz301/8529945 注册码 Subl ...
- 解决Flash和html在多标签浏览器中互访问题
在Flash播放器运行时,将不同来源的资源划分到独立的沙箱(sandbox)内,不同沙箱之间不能 彼此操作数据(除非目标沙箱做过一些设置,授权其他沙箱可访问),这就是Flash的跨沙箱问题.当Flas ...
- 远程数据源Combobox
Ext.define('bookInfo', { extend: 'Ext.data.Model',//新类继承自model fields: [{ name: 'b ...
- 各大公司广泛使用的在线学习算法FTRL详解 - EE_NovRain
转载请注明本文链接:http://www.cnblogs.com/EE-NovRain/p/3810737.html 现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression ...
- delphi的socket通讯 多个客户端 (转)
ClientSocket组件为客户端组件.它是通信的请求方,也就是说,它是主动地与服务器端建立连接. ServerSocket组件为服务器端组件.它是通信的响应方,也就是说,它的动作是监听以及被动接受 ...
- HDU4782 Beautiful Soup
成都赛里的一道坑爹码力题,突然间脑抽想做一下弥补一下当时的遗憾.当时没做出这道题一是因为当时只剩大概45分钟,对于这样的具有各种条件的题无从下手,二则是因为当时估算着已经有银牌了,所以就不挣扎了.但是 ...
- 《从零开始学习jQuery》及《jQuery风暴》学习笔记
第一章 jQuery入门 1.用$()函数其实是一个事件,使用这个函数调用的方法,会在DOM加载完毕.资源文件加载完之前触发. 第二章 必须知道的JavaScript知识 1.JavaScript实际 ...
- Minifilter微过滤框架:框架介绍以及驱动层和应用层的通讯
minifilter是sfilter后微软推出的过滤驱动框架.相比于sfilter,他更容易使用,需要程序员做的编码更简洁. 系统为minifilter专门制作了一个过滤管理器,这个管理器本身其实是一 ...
- 复习一下,? extends T 和 ? super T
前话 最近学一些杂七杂八的东西,都把基础给忘了. 比如Java泛型中的 ? extends T和 ? super T 吧. 刚看开源项目的时候遇到它,表情如下: 源码分析 直接用源码来讲解吧 pack ...