Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法
有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/,然后右击空白处,选择“查看网页源代码”,如下所示:
就会发现一片空白

留意到红线处指定了一个名为api.json的文件,于是打开浏览器的调试器中的Network面板,找到名为api.json的标签
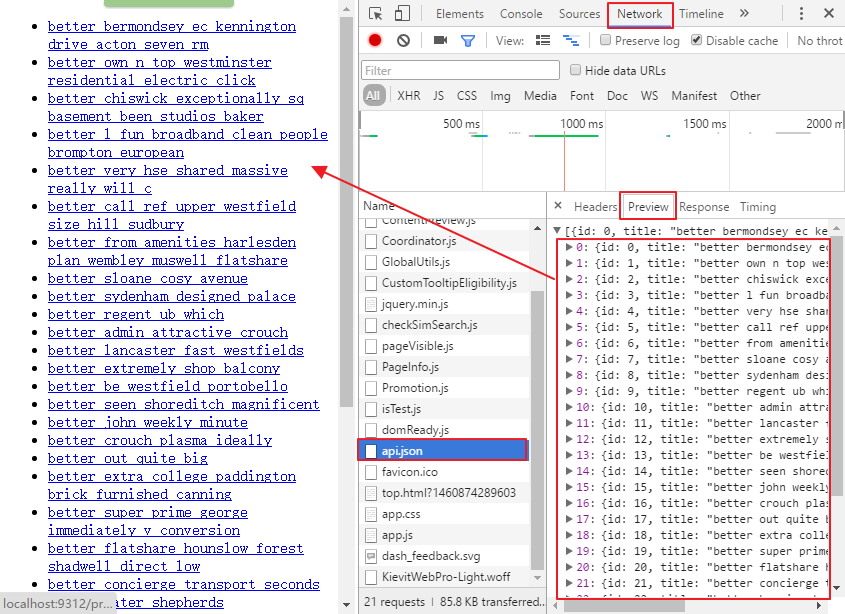
在上图的红色框里就找到了原网页中的内容,这是一个简单的JSON API,有些复杂的API会要求你先登录,发送POST请求,或者返回一些更加有趣的数据结构。Python提供了一个用于解析JSON的库,可以通过语句json.loads(response.body)将JSON数据转变成Python对象
api.py文件的源代码地址:
https://github.com/Kylinlin/scrapybook/blob/master/ch05%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,做以下改动:
将spider名修改为api
将start_urls修改为JSON API的URL,如下
start_urls = (
'http://web:9312/properties/api.json',
)
如果在获取这个json的api之前,需要登录,就使用start_request()函数(参考《Learning Scrapy笔记(五)- Scrapy登录网站》)
- 修改parse函数
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_%06d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
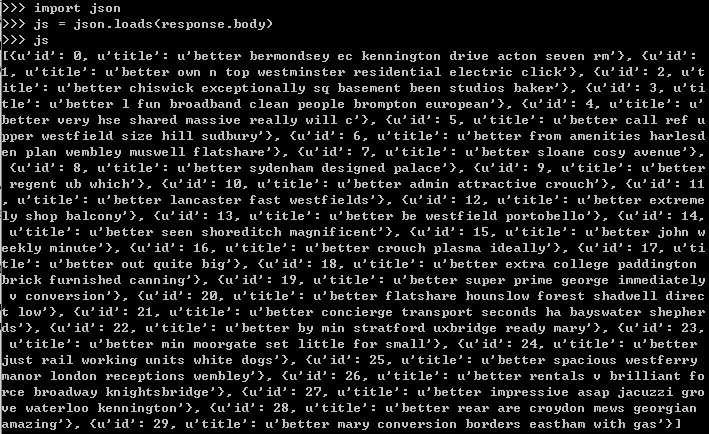
上面的js变量是一个列表,每个元素都代表了一个条目,可以使用scrapy shell工具来验证:
scrapy shell http://web:9312/properties/api.json
运行该spider:scrapy crawl api
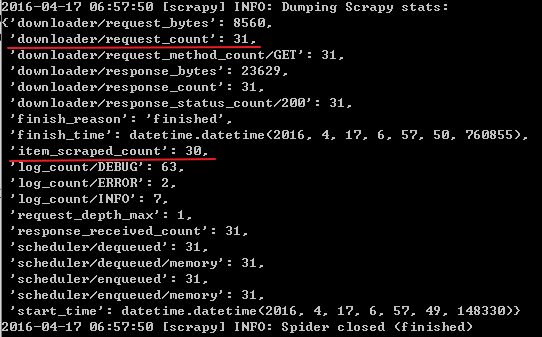
可以看到总共发送了31个request,获取了30个item
再观察上图中使用scrapy shell工具检查js变量的图,其实除了id字段外,还可以获取title字段,所以可以在parse函数中同时获取title字段,并将该字段的值传送到parse_item函数中填充到item里(省去了在parse_item函数中使用xpath来提取title的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,可以在response中提取这个字段
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title))
Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面的更多相关文章
- Gin-Go学习笔记六:Gin-Web框架 Api的编写
Api编写 1> Gin框架的Api返回的数据格式有json,xml,yaml这三种格式.其中yaml这种格式是一种特殊的数据格式.(本人暂时没有实现获取节点值得操作) 2> ...
- Scrapy基础(六)————Scrapy爬取伯乐在线一通过css和xpath解析文章字段
上次我们介绍了scrapy的安装和加入debug的main文件,这次重要介绍创建的爬虫的基本爬取有用信息 通过命令(这篇博文)创建了jobbole这个爬虫,并且生成了jobbole.py这个文件,又写 ...
- 钉钉开发笔记(六)使用Google浏览器做真机页面调试
注: 参考文献:https://developers.google.com/web/ 部分字段为翻译文献,水平有限,如有错误敬请指正 步骤1: 从Windows,Mac或Linux计算机远程调试And ...
- Learning Scrapy笔记(零) - 前言
我已经使用了scrapy有半年之多,但是却一直都感觉没有入门,网上关于scrapy的文章简直少得可怜,而官网上的文档(http://doc.scrapy.org/en/1.0/index.html)对 ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- scrapy笔记集合
细读http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 目录 Scrapy介绍 安装 基本命令 项目结构以及爬虫应用介绍 简单使用示例 选 ...
- Scrapy 笔记(二)
一个scrapy爬虫知乎项目的笔记 1.通过命令创建项目 scrapy startproject zhihucd zhihuscrapy genspider zhihu www.zhihu.com(临 ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy笔记(1)- 入门篇
Scrapy笔记01- 入门篇 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说, ...
随机推荐
- Android——requestWindowFeature
requestWindowFeature可以设置的值有:1.DEFAULT_FEATURES:系统默认状态,一般不需要指定2.FEATURE_CONTEXT_MENU:启用ContextMenu,默认 ...
- 使用pscp实现Windows 和 Linux服务器间远程拷贝文件
转自:http://www.linuxidc.com/Linux/2012-05/60966.htm 在工作中,每次部署应用时都需要从本机Windows服务器拷贝文件到Linux上,有时还将Linux ...
- Flash Air 打包安卓 ane
工具: 1.flash builder 2.adt打包工具 3.数字证书 一. 创建 jar 文件 1. 打开flash builder, 新建一个java 项目. 2.点击项目属性,选择Java构建 ...
- 【测试】通过RMAN联机全库备份,包括控制文件,归档日志文件,备份成功后,删除已备份的归档日志。
RMAN是一个很方便很好用的备份,恢复,还原的一个工具,做这个小测试其实只有一个RMAN语句就完全解决了这么大的需求: RMAN> backup as backupset full databa ...
- MapReduce和Tez对比
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)". Tez是Apache开源的支持D ...
- number对象,bom对象
number对象 新创建一个number的对象,toFixed是精确到位数 var num =new Number('123.1231'); console.log(num.toFixed(1)); ...
- BZOJ 1036 树的统计-树链剖分
[ZJOI2008]树的统计Count Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 12904 Solved: 5191[Submit][Status ...
- JavaBean和内省
JavaBean和内省 JavaBean是一个遵循特定的写法的java类 1. 必须有一个无参的构造方法 2.属性私有化 3.私有你给的属性必须通过public类型的方法暴露给 ...
- 多文件目录下makefile文件递归执行编译所有c文件
首先说说本次嵌套执行makefile文件的目的:只需make根目录下的makefile文件,即可编译所有c文件,包括子目录下的. 意义:自动化编译行为,以后编译自己的c文件时可把这些makefile文 ...
- java基础回顾(三)——HashMap与HashTable
public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable public cla ...