Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法
有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/,然后右击空白处,选择“查看网页源代码”,如下所示:
就会发现一片空白

留意到红线处指定了一个名为api.json的文件,于是打开浏览器的调试器中的Network面板,找到名为api.json的标签
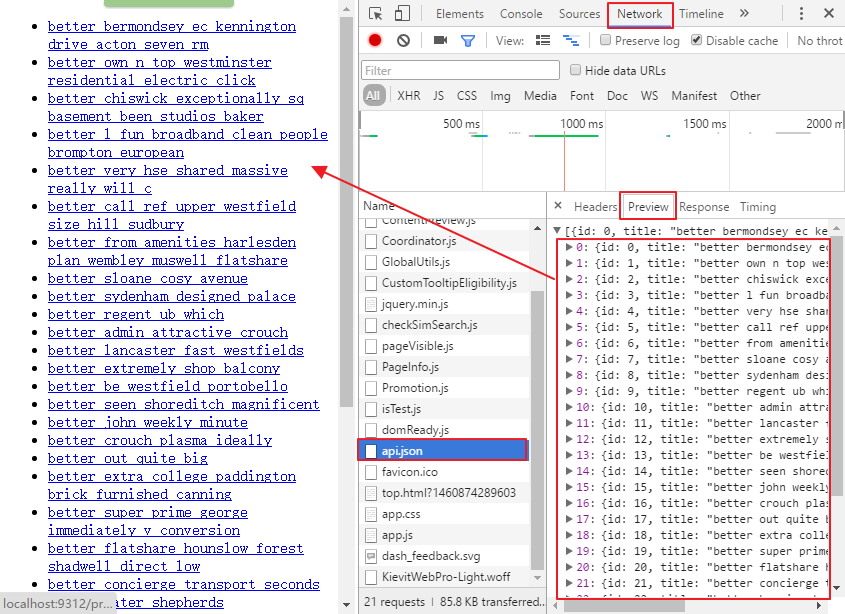
在上图的红色框里就找到了原网页中的内容,这是一个简单的JSON API,有些复杂的API会要求你先登录,发送POST请求,或者返回一些更加有趣的数据结构。Python提供了一个用于解析JSON的库,可以通过语句json.loads(response.body)将JSON数据转变成Python对象
api.py文件的源代码地址:
https://github.com/Kylinlin/scrapybook/blob/master/ch05%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,做以下改动:
将spider名修改为api
将start_urls修改为JSON API的URL,如下
start_urls = (
'http://web:9312/properties/api.json',
)
如果在获取这个json的api之前,需要登录,就使用start_request()函数(参考《Learning Scrapy笔记(五)- Scrapy登录网站》)
- 修改parse函数
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_%06d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
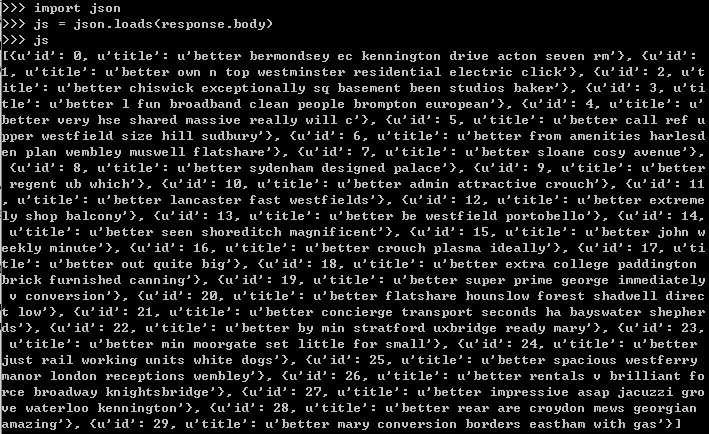
上面的js变量是一个列表,每个元素都代表了一个条目,可以使用scrapy shell工具来验证:
scrapy shell http://web:9312/properties/api.json
运行该spider:scrapy crawl api
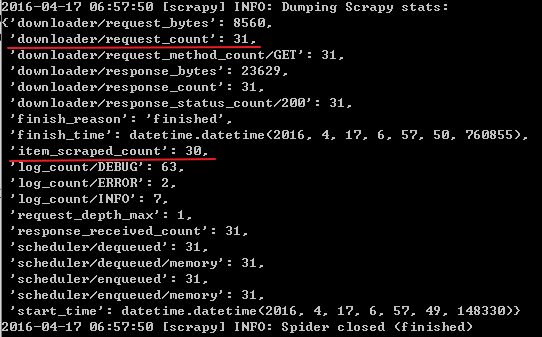
可以看到总共发送了31个request,获取了30个item
再观察上图中使用scrapy shell工具检查js变量的图,其实除了id字段外,还可以获取title字段,所以可以在parse函数中同时获取title字段,并将该字段的值传送到parse_item函数中填充到item里(省去了在parse_item函数中使用xpath来提取title的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,可以在response中提取这个字段
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title))
Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面的更多相关文章
- Gin-Go学习笔记六:Gin-Web框架 Api的编写
Api编写 1> Gin框架的Api返回的数据格式有json,xml,yaml这三种格式.其中yaml这种格式是一种特殊的数据格式.(本人暂时没有实现获取节点值得操作) 2> ...
- Scrapy基础(六)————Scrapy爬取伯乐在线一通过css和xpath解析文章字段
上次我们介绍了scrapy的安装和加入debug的main文件,这次重要介绍创建的爬虫的基本爬取有用信息 通过命令(这篇博文)创建了jobbole这个爬虫,并且生成了jobbole.py这个文件,又写 ...
- 钉钉开发笔记(六)使用Google浏览器做真机页面调试
注: 参考文献:https://developers.google.com/web/ 部分字段为翻译文献,水平有限,如有错误敬请指正 步骤1: 从Windows,Mac或Linux计算机远程调试And ...
- Learning Scrapy笔记(零) - 前言
我已经使用了scrapy有半年之多,但是却一直都感觉没有入门,网上关于scrapy的文章简直少得可怜,而官网上的文档(http://doc.scrapy.org/en/1.0/index.html)对 ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- scrapy笔记集合
细读http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 目录 Scrapy介绍 安装 基本命令 项目结构以及爬虫应用介绍 简单使用示例 选 ...
- Scrapy 笔记(二)
一个scrapy爬虫知乎项目的笔记 1.通过命令创建项目 scrapy startproject zhihucd zhihuscrapy genspider zhihu www.zhihu.com(临 ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy笔记(1)- 入门篇
Scrapy笔记01- 入门篇 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说, ...
随机推荐
- Ant not found - Make sure it's in the path or use --with-ant-home
# pacman -S apache-ant 参考:http://blog.csdn.net/linshutao/article/details/6638116
- ASP.NET MVC 4 部署到 Windows Azure 如何轉換時區設定
由於公司慢慢地開始將新的專案都移往 Windows Azure 雲端平台做網站代管,漸漸地也開始遇到一些小問題,這些問題在還沒上雲端之前通常不會發生,像我們這次遇到的問題就跟顯示時間有關.由於 Win ...
- wmware10安装ghost win7问题处理
随便找到了ghostwin7.iso, 先建立空的虚拟机, 加载iso, 按F2, 设置启动从光盘启动, 启动进去后点直安装Ghost镜像到C盘, 失盘, 直接跳到dos界面了. 忘记先要分区了, 使 ...
- Android ImageView 详述
结构 继承关系 public classView.OnClickListner extendsView java.lang.Object android.view.View android.widge ...
- VISUAL STUDIO 2008 WINDOWS FORM项目发布生成安装包详解(转)
转自:http://www.cnblogs.com/killerofyang/archive/2012/05/31/2529193.html Visual Studio 2008 Windows Fo ...
- 华为OJ平台——查找组成一个偶数最接近的两个素数
import java.util.Scanner; /** * 问题描述:任意一个偶数(大于2)都可以由2个素数组成,组成偶数的2个素数有很多种情况, * 本题目要求输出组成指定偶数的两个素数差值最小 ...
- js的数组申明
//数组的3种申明方法,如下example //数组是一种object类型 通过typeof 来检查 //example 1 var arr= new Array("h",&quo ...
- 【MySQL】MySQL无基础学习和入门之一:数据库基础概述和实验环境搭建
数据库基础概述 大部分互联网公司都选择MySQL作为业务数据存储数据库,除了MySQL目前还有很多公司使用Oracle(甲骨文).SQLserver(微软).MongoDB等. 从使用成本来区分可以 ...
- (笔记)angular Select选择
- thinkphp验证码点击更换js实现
<img src="__CONTROLLER__/verify" alt="" onclick=this.src="__CONTROLLER__ ...