linux 多处理器概念
Linux 提出了 Multi-Processing 的概念,它的调度器可以将操作系统的线程均分到各个核(或硬件线程)上去执行,以此达到并行计算的目的,从而也可以极大地提高系统的性能。
实现计数器
1)自旋锁
spinlock不会导致线程的状态切换(用户态->内核态),
1, spinlock介绍
spinlock又称自旋锁,线程通过busy-wait-loop的方式来获取锁,任时刻只有一个线程能够获得锁,其他线程忙等待直到获得锁。spinlock在多处理器多线程环境的场景中有很广泛的使用,一般要求使用spinlock的临界区尽量简短,这样获取的锁可以尽快释放,以满足其他忙等的线程。Spinlock和mutex不同,spinlock不会导致线程的状态切换(用户态->内核态),但是spinlock使用不当(如临界区执行时间过长)会导致cpu busy飙高。
2, spinlock与mutex对比
2.1,优缺点比较
spinlock不会使线程状态发生切换,mutex在获取不到锁的时候会选择sleep。
mutex获取锁分为两阶段,第一阶段在用户态采用spinlock锁总线的方式获取一次锁,如果成功立即返回;否则进入第二阶段,调用系统的futex锁去sleep,当锁可用后被唤醒,继续竞争锁。
Spinlock优点:没有昂贵的系统调用,一直处于用户态,执行速度快。
Spinlock缺点:一直占用cpu,而且在执行过程中还会锁bus总线,锁总线时其他处理器不能使用总线。
Mutex优点:不会忙等,得不到锁会sleep。
Mutex缺点:sleep时会陷入到内核态,需要昂贵的系统调用。
2.2,使用准则
Spinlock使用准则:临界区尽量简短,控制在100行代码以内,不要有显式或者隐式的系统调用,调用的函数也尽量简短。例如,不要在临界区中调用read,write,open等会产生系统调用的函数,也不要去sleep;strcpy,memcpy等函数慎用,依赖于数据的大小。
3, spinlock系统实现
spinlock的实现方式有多种,但是思想都是差不多的,现罗列一下:
3.1,glibc-2.9中的实现方法:
int pthread_spin_lock (lock) pthread_spinlock_t *lock;
{
asm ("\n"
"1:\t" LOCK_PREFIX "decl %0\n\t"
"jne 2f\n\t"
".subsection 1\n\t"
".align 16\n"
"2:\trep; nop\n\t"
"cmpl $0, %0\n\t"
"jg 1b\n\t"
"jmp 2b\n\t"
".previous"
: "=m" (*lock)
: "m" (*lock));
return 0;
}
执行过程:
1,lock_prefix 即 lock。lock decl %0,锁总线将%0(即lock变量)减一。Lock可以保证接下来一条指令的原子性。
2, 如果lock=1,decl的执行结果为lock=0,ZF标志位为1,直接跳到return 0;否则跳到标签2。也许要问,为啥能直接跳到return 0呢?因为subsection和previous之间的代码被编译到别的段中,因此jne之后紧接着的代码就是 return 0 (leaveq;retq)。Rep nop在经过编译器编译之后被编译成 pause。
3, 如果跳到标签2,说明获取锁不成功,循环等待lock重新变成1,如果lock为1跳到标签1重新竞争锁。
该实现采用的是AT&T的汇编语法,更详细的执行流程解释可以参考“五竹”大牛的文档。
TAS: 指Test-And-Set,它是一个原子操作,修改内存的值,并返回原来的值
http://blog.itpub.net/30088583/viewspace-1512121/
http://blog.csdn.net/yuanrxdu/article/details/41170381
#include <stdio.h>
#include <stdlib.h> int test_and_set(volatile int *addr){
int old_value;
old_value=swap_atomic(addr,);
if(old_value == ){
return ;
}
return ;
} void spin_lock(volatile lock_t* lock_status)
{
while (test_and_set(lock_status) ==)
;
} void unlock(volatile *lock_status){
*lock_status=;
} int main(){
lock_t* lock_status=;
int count=;
spin_lock(lock_status);
count++;
spin_unlock(lock_status);
return ;
}
现在有两颗CPU CPU1和CPU2,同时运行上面程序
当运行完
lock_t *lock_status后,CPU1和CPU2的高速缓冲中都存放了0
执行spin_lock后,CPU1先拿到了锁(swap_aotime(addr,1) 所做的汇编为
lock bus;
movl $1,%eax;将1放进寄存器eax
movl %eax,addr;将寄存器的值放入addr所在的内存
)此时,内存中lock_status的值为1,同时,CPU1向总线发出广播,说CPU1改变了lock_status的值,CPU2收到通知后,将高速缓冲中的lock_status的状态置为invalid
当CPU2执行spin_lock时,因为CPU2的高速缓冲中的lock_status标志为invalid,所以CPU2会向总线发一个通知,CPU1接收通知后,将lock_status=1推向CPU2的调整缓存,并将值写入主存中,因为 1!=0 所以拿不到锁,只能忙等待,耗费CPU
更精确的cache实现需要考虑到其他更多的可能性,比如第二个CPU在读或者写他的cache line时,发现该cache line在第一个CPU的cache中被标记为脏数据了,此时我们就需要做进一步的处理。在这种情况下,主存储器已经失效,第二个CPU需要读取第一个CPU的cache line。通过测试,我们知道在这种情况下第一个CPU会将自己的cache line数据自动发送给第二个CPU。这种操作是绕过主存储器的,但是有时候存储控制器是可以直接将第一个CPU中的cache line数据存储到主存储器中。对第一个CPU的cache的写访问会导致本地cache line的所有拷贝被标记为无效。
用TAS来实现spin lock,此处要注意volatile的使用。volatile表示这个变量是易失的,所以会编译器会每次都去内存中取原始值,而不是直接拿寄存器中的值。
这避免了在多线程编程中,由于多个线程更新同一个变更,内存中和寄存器中值的不同步而导致变量的值错乱的问题。另外,也会影响编译器的优化行为。
http://m.blog.csdn.net/blog/gigglesun/37595689
http://blog.csdn.net/robertsong2004/article/details/38340247
自旋锁是一种非阻塞锁,也就是说,如果某线程需要获取自旋锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗CPU的时间,不停的试图获取自旋锁。
互斥量是阻塞锁,当某线程无法获取互斥量时,该线程会被直接挂起,该线程不再消耗CPU时间,当其他线程释放互斥量后,操作系统会激活那个被挂起的线程,让其投入运行。
两种锁适用于不同场景:
如果是多核处理器,如果预计线程等待锁的时间很短,短到比线程两次上下文切换时间要少的情况下,使用自旋锁是划算的。
如果是多核处理器,如果预计线程等待锁的时间较长,至少比两次线程上下文切换的时间要长,建议使用互斥量。
如果是单核处理器,一般建议不要使用自旋锁。因为,在同一时间只有一个线程是处在运行状态,那如果运行线程发现无法获取锁,只能等待解锁,但因为自身不挂起,所以那个获取到锁的线程没有办法进入运行状态,只能等到运行线程把操作系统分给它的时间片用完,才能有机会被调度。这种情况下使用自旋锁的代价很高。
如果加锁的代码经常被调用,但竞争情况很少发生时,应该优先考虑使用自旋锁,自旋锁的开销比较小,互斥量的开销较大。
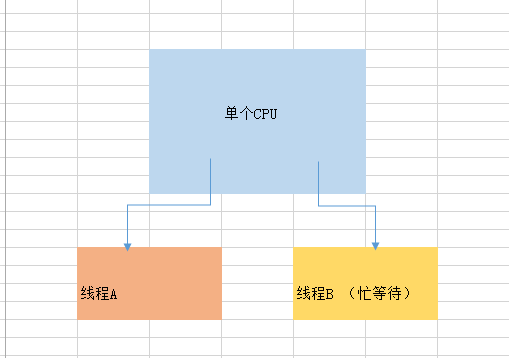
单CPU情况下,
线程A取得锁,这时线程B尝试获得锁,得不到,不停向CPU发起请求,
线程A得不到CPU,即使想释放锁,也不行,因为CPU使用权在线程B
当CPU分给线程A的时间片用完,线程A也释放了锁,线程B在时间片范围内即可拿到锁
可见,单CPU下面的自旋锁浪费了好多时间

上面的TAS有一个问题 ,当某个线程拿不到锁时,会不停的执行while(test_and_set(lock_status)==1),这个lock_status是volatile修饰符,这就需要不停的经过总线,向内存取数据,可能造成总线风暴,于是出现了TTAS
TAS
void spin_lock(volatile int* lock_status){
while(test_and_set(lock_status) == 1)
;
}
TTAS
void spin_lock(volatile int* lock_status){ //volatile 表示从内存取数据
while(test_and_set(lock_status) == 1) //然后放入CPU高速缓存中
while(lock_status) //在高速缓存中循环,不会消耗总线资源,当持锁的线程解锁后,这里的数据变成invalid,再向内存读数据, 加锁成功
//http://my.oschina.net/clopopo/blog/140479
}
改进
http://blog.csdn.net/david_henry/article/details/5405093/
http://blog.csdn.net/robertsong2004/article/details/38340247
http://www.cnblogs.com/dolphin0520/p/3920373.html
http://blog.csdn.net/liu251/article/details/6439453
http://my.oschina.net/clopopo/blog/140479
java中外部锁实现就用到了自旋锁这个概念,之前看jdk的concurrent包源码的时候,对这部分实现一直是无法透彻的理解。正所谓”外行看热闹,内行看门道“。虽然代码按行看都能看懂,但是连在一起不知道是为什么这么做。只能对Doug Lea大神佩服的十体投地。这么复杂精巧的代码是怎么想出来的?
后面看了《多处理器编程的艺术》这本书时,对自旋的概念开始有了一点概念。要想了解并应用好自旋锁,不仅仅是对相关算法的了解,还需要一些些底层硬件的知识哦。不过不用担心,需要的底层硬件知识不是很多(万幸),所以在详细讲解各个自旋锁之前,需要对这些一点点的硬件知识了解一下,正好以此作为开篇。这个系列大部分内容和代码都来自于《多处理器编程的艺术》一书,算是一个读书笔记吧。
1、处理器和线程
一个多处理器是由多个硬件处理器组成。其中每一个处理器都能执行一个顺序程序。处理器提取和执行一条指令的时间叫做时钟周期,这也是我们用来衡量程序执行性能的基本时间单位。处理器可以执行线程一段时间,然后不去管这个线程有没有执行完,转而去执行另一个线程。这个切换过程就是我们熟悉的上下文切换。处理器会因为各种原因从调度中删除一个线程去执行其他的线程。在多处理器系统中,当线程从一个处理器调度中被删除后,可能重新在另一个处理器上执行。
2、互连线
互连线是cpu和内存以及cpu和cpu之间进行通信的一种媒介。有两种基本的连接模式:SMP(对称duochuli)和
NUMA(非一致性内存访问)。

在SMP系统结构中,处理器和存储器通过总线来通信。处理器和存储器都有用来负责发送和监听总线上广播信息的总线控制单元。SMP系统结构非常普遍,因为它们比较容易构建。但是对于处理器数量较多的系统来说,这种结构不利于扩展,因为最终总线会成为瓶颈。

NUMA中,一系列节点通过点对点网络连接,就像一个小的局域网。每个节点包含一个或多个处理器和一个存储器。一个节点的存储器对于其他节点来说是可以访问的。所有节点的本地存储器组成了一个所有处理器共享的全局存储器。NUMA名字叫做非一致性内存访问,意思就是处理器访问自己的本地存储要比访问其他处理器的存储要快。访问内存的速度并不是一致的。NUMA结构显然比较复杂,需要的协议也更复杂。但是对于处理器数量多的系统来说扩展性更好。
可以在SMP和NUMA之间找一个平衡。每个节点用SMP来构造,而连接节点则采用NUMA结构。当然对于我们程序员来说,我们只要知道一点:互连线是由处理器共享的有限资源。如果一个处理器占用了较多的互连线资源,其他的处理器必然会被延时执行。这一点非常重要。
3、主存
主存可以看成一个由所有处理器共享的由字组成的一个大数组。我们通过特定的地址来访问主存对应的区域。通常字长是32字节或者64字节。字长为32字节的系统主存地址是32位的,字长为64字节的系统主存地址是64位的。也就是我们通常说的32位机和64位机。处理器通过连接线给主存发送包含目的地址的信息,用来获取主存中对应目的地址的值。或者发送包含目的地址以及一个新的数据,用于向主存对应的地址中中写入新值,当新值被写入后,主存会发送确认信息。我们可以看到,处理器对主存的读取和写入都会占用互连线资源。
4、高速缓存
处理器对主存的一次访问可能会花费数百个时钟周期,如果处理器频繁的对主存进行读取操作意味着处理器将会花费大量的时间等待主存响应请求。另外,处理器访问主存会占用互连线资源,造成其他的处理器的延迟。所以高速缓存就出现了,这是一个介于处理器和主存之间的一个小容量存储器。高速缓存的读取速度比主存要快的多。当处理器要读取一个值时,首先会到高速缓存中去寻找,如果存在,处理器就不用再去访问比较慢的主存了,否则处理器必须还要到主存中去取值。我们把读取的值在高速缓存中存在这种情况叫做”cache 命中“,不存在这种情况叫做”cache缺失“。理解”cache命中“和”cache缺失“对设计高性能的自旋锁可是非常必要的哦。
5、一致性
当一个处理器读或写了被另一个处理器装入高速缓存的主存地址时,将发生共享。例如处理器A读写了主存的一个值,并装入自己的高速缓存。处理器B也在随后读取了同一个值,此时会发生共享(或者叫内存争用)。如果两个处理器共享同一个主存地址,一个处理器修改了改地址的值,另一个处理器的高速缓存中保存的值将会被作废,以确保不会读到过期值。这个问题就是缓存的一致性问题。
有一种最常用的叫做MESI的协议用于解决缓存一致性问题,下面来详细了解一下。
首先对缓存块的状态进行命名:
- modified (修改):缓存块中的数据已经被修改,需要最终写回到主存中去。其他处理器不能缓存该数据。
- exclusive(独占):缓存块中的数据只被一个处理器未被修改。其他处理器可以缓存该数据。
- shared(共享):缓存快中的数据被多个处理器共享且未被修改。其他处理器可以缓存该数据
- invalid(无效):缓存块中的数据无效。
我们用例子来解释一下MESI协议:
(1)刚开始,处理器A读取主存中的数据a并储存在高速缓存中。此时A的缓存块对应的状态是Exclusive。这个不用解释。

(2)然后处理器B也读取了相同的数据a也缓存到了自己的高速缓存中。此时A和B共享主存中的同一个数据a。所以它们的缓存块状态都是shared。
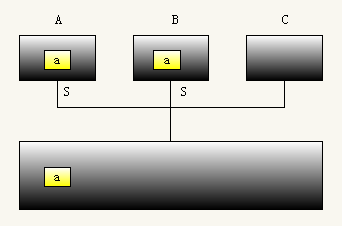
(3)接着,处理器B修改了数据a为b,但是只是修改了缓存块中的数据,并没有同步到主存中去。此时B的缓存块状态是modified,同时A的缓存块状态变为了invalid。B在修改的同时回向其他处理器广播,所以A修改了自己的缓存块状态。

(4)如果A此时要从读取a时,会广播请求。B收到请求将修改后的值同时发送给处理器A和主存,并将A和B的缓存块状态变成和谐的shared状态。
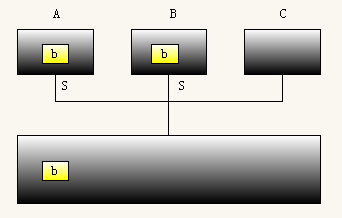
其实这个MESI协议还是比较好理解的。
6、自旋
如果处理器不断的测试内存中的某个字,并等待另一个处理器处理它,则称该处理器正在自旋。举例来说,内存中存在一个布尔变量a,初始值为false。A处理器不断地去读取它,知道a被另一个处理器设置成true为止。我们称处理器A的行为(不断的读取a,并测试a是不是为true)叫做自旋。其实也就是名字唬人罢了。
对于没有高速缓存的SMP系统结构来说,自旋是一种非常糟糕的想法。因为,每次自旋都是处理器到主存中去读取值。每次的读取操作都会消耗总线资源(还记得上面SMP的结构图吗),会直接影响到其他处理器的推进。
对于无高速缓存的NUMA系统结构来说(NUMA也可以带高速缓存的)。如果自旋的地址位于本地存储器中,这个是可以接受的。否则也是糟糕的想法。还好目前不带高速缓存的多处理器系统结构很少见。
对于有高速缓存的SMP和NUMA系统结构来说,自旋仅消耗非常少的资源。因为处理器第一次读取肯会直接到主存中去读(cache缺失),但后面自旋过程中,只要数据没有改变,处理器都会从自己的高速缓存中去读取数据(cache命中)。这种我们称为”本地自旋“。一旦高速缓存中的数据被改变,立刻会产生一个cache缺失(缓存块状态为invalid),既然数据已经被改变,自旋也会随之停止。
linux 多处理器概念的更多相关文章
- Linux 基本概念和操作2
接着上一篇 "Linux 基本概念和操作" 1.删除文件 有时候我们想要删除的文件是只读文件,直接使用rm 文件名,会报错.这时使用" -f " 参数强制删除. ...
- Linux磁盘概念及其管理工具fdisk
Linux磁盘概念及其管理工具fdisk [日期:2016-08-27] 来源:Linux社区 作者:chawan [字体:大 中 小] 引言:冯诺依曼体系中的数据存储器就是我们常说的磁盘或硬盘 ...
- Linux - 链接概念详解
1> Linux链接概念Linux链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link).默认情况下,ln命令产生硬链接. [硬连接]硬连接指通过 ...
- 【Linux大系】Linux的概念与体系
感谢原作者:Vamei 出处:http://www.cnblogs.com/vamei 我在这一系列文章中阐述Linux的基 本概念.Linux操作系统继承自UNIX.一个操作系统是一套控制和使用计算 ...
- Linux的概念与体系
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 我在这一系列文章中阐述Linux的基本概念.Linux操作系统继承自UNIX.一个 ...
- Linux 进程状态 概念 Process State Definition
From : http://www.linfo.org/process_state.html 进程状态是指在进程描述符中状态位的值. 进程,也可被称为任务,是指一个程序运行的实例. 一个进程描述符是一 ...
- linux 进程概念
1,pcb:进程控制块结构体:/usr/src/linux-headers-4.15.0-29/include/linux/sched.h 进程id:系统中每个进程有唯一的id,在c语言中用pid_t ...
- linux挂载概念简述:
挂载概念简述: 根文件系统之外的其他文件要想能够被访问,都必须通过“关联”至根文件系统上的某个目录来实现,此关联操作即为“挂载”,此目录即为“挂载点”,解除此关联关系的过程称之为“卸载” 1.挂载:根 ...
- jsp/servlet/mysql/linux基本概念和操作
一.什么是OOP编程? 面向对象,以结果为导向,并封装整个过程,并尽可能地增加代码的复用性和可扩展性...... 二.Junit? JUnit是一个java语言的单元测试框架.Junit测试时程序员测 ...
随机推荐
- 如何理解JS项目
JS API(DOM/PhoneGap/Cordova/NodeJS/Library/Android/MongoDB....)最基础,可以看懂一行代码. -------> JS OOP, JS语 ...
- Sqli-labs less 27
Less-27 本关主要考察将union,select和26关过滤掉的字符.此处我们依旧和26关的方式是一样的,只需要将union和select改为大小写混合就可以突破. 示例:127.0.0.1/s ...
- 新浪SAE中文分词接口
最近发现新浪SAE平台上竟然也提供分词功能,分词效果也还不错,由新浪爱问提供的分词服务,研究了一番,做了一个简易版的在线调用接口(get方式,非post) 官网说明:http://apidoc.sin ...
- POJ3164 Command Network(最小树形图)
图论填个小坑.以前就一直在想,无向图有最小生成树,那么有向图是不是也有最小生成树呢,想不到还真的有,叫做最小树形图,网上的介绍有很多,感觉下面这个博客介绍的靠谱点: http://www.cnblog ...
- KMP模板,最小循环节
(可以转载,但请注明出处!) 下面是有关学习KMP的参考网站 http://blog.csdn.net/yaochunnian/article/details/7059486 http://blog. ...
- POJ 1477
#include <iostream> #define MAXN 100 using namespace std; int _[MAXN]; int main() { //freopen( ...
- 2013 ACM/ICPC Asia Regional Changsha Online G Goldbach
比赛的时候,被题目误导了,题目最后说结果可能很大,要取模,那时就想直接求会TLE的!!! 赛后才知道,坑啊………… 代码如下: #include<iostream> #include< ...
- js小技巧(一)
事件源对象 event.srcElement.tagName event.srcElement.type 捕获释放 event.srcElement.setCapture(); event.srcE ...
- Swift 使用CollectionView 实现图片轮播封装就是这样简单
前言: 这篇你可以学会自定义视图,创建collectionView,协议的使用,定时器; 自制图片 先上Demo:Github上封装好的下载即用, 好用请Star Thanks首先新建一个继承于UIV ...
- eclipse 代码格式化 行宽设置
windows--preferences--java--code style--formatter--edit--line wrapping--maximum line width