Pulsar3.0新功能介绍

在上一篇文章 Pulsar3.0 升级指北讲了关于升级 Pulsar 集群的关键步骤与灾难恢复,本次主要分享一些 Pulsar3.0 的新功能与可能带来的一些问题。
升级后所遇到的问题
先来个欲扬先抑,聊聊升级后所碰到的问题吧。
其中有两个问题我们感知比较明显,特别是第一个。
topic被删除
我们在上个月某天凌晨从 2.11.2 升级到 3.0.1 之后,进行了上一篇文章中所提到的功能性测试,发现没什么问题,觉得一切都还挺顺利的,半个小时搞定后就下班了。
结果哪知道第二天是被电话叫醒的,有部分业务反馈业务重启之后就无法连接到 Pulsar 了。

最终定位是 topic 被删除了。
其中的细节还蛮多的,修复过程也是一波三折,后面我会单独写一篇文章来详细梳理这个过程。
在这个 issue 和 PR 中有详细的描述:
https://github.com/apache/pulsar/issues/21653
https://github.com/apache/pulsar/pull/21704
感兴趣的朋友也可以先看看。
监控指标丢失
第二个问题不是那么严重,是升级后发现 bookkeeper 的一些监控指标丢失了,比如这里的写入延迟:
我也定位了蛮久,但不管是官方的 docker 镜像还是源码编译都无法复现这个问题。
最终丢失的指标有这些:
- bookkeeper_server_ADD_ENTRY_REQUEST
- bookkeeper_server_ADD_ENTRY_BLOCKED
- bookkeeper_server_READ_ENTRY_BLOCKED
- bookie_journal_JOURNAL_CB_QUEUE_SIZE
- bookie_read_cache_hits_count
- bookie_read_cache_misses_count
- bookie_DELETED_LEDGER_COUNT
- bookie_MAJOR_COMPACTION_COUNT
详细内容可以参考这个 issue:
https://github.com/apache/pulsar/issues/21766
新特性
讲完了遇到的 bug,再来看看带来的新特性,重点介绍我们用得上的特性。
支持低负载均衡
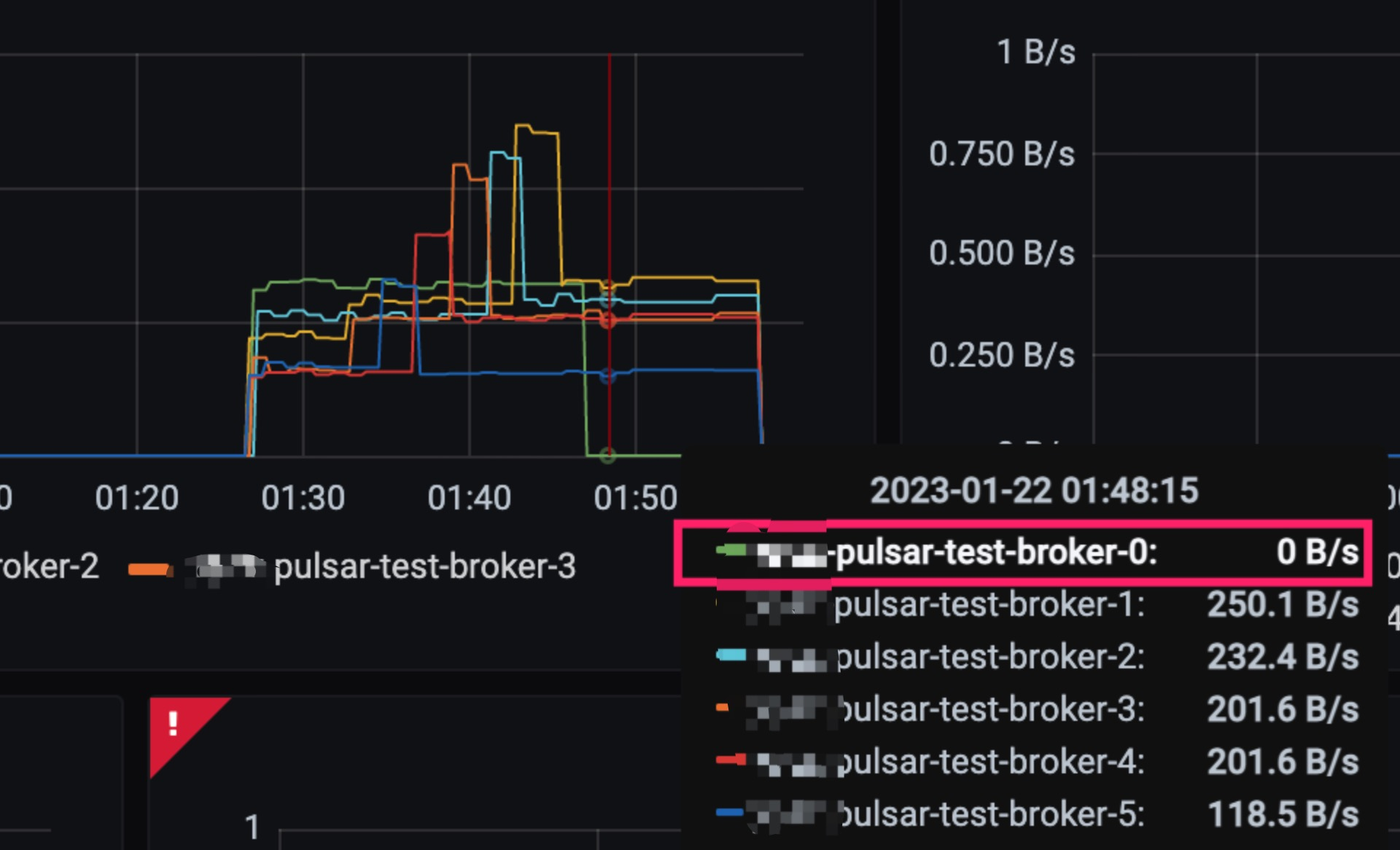
当我们升级或者是重启 broker 的时候,全部重启成功后其实会发现最后重启的那个 broker 是没有流量的。
这个原理和优化在之前写过的 Pulsar负载均衡原理及优化 其实有详细介绍。
本次 3.0 终于将那个优化发版了,之后只要我们配置 lowerBoundarySheddingEnabled: true 就能开启这个低负载均衡的一个特性,使得低负载的 broker 依然有流量进入。
跳过空洞消息

Pulsar 可能会因为消息消费异常导致游标出现空洞,从而导致磁盘得不到释放;
所以我们有一个定时任务,会定期扫描积压消息的 topic 判断是否存在空洞消息,如果存在便可以在管理台使用 skipMessage API 跳过空洞消息,从而释放磁盘。
但在 3.0 之前这个跳过 API 存在 bug,只要跳过的数量超过 8 时,实际跳过的数量就会小于 8.
具体 issue 和修复过程在这里:
https://github.com/apache/pulsar/issues/20262
https://github.com/apache/pulsar/pull/20326
总之这个问题在 3.0 之后也是修复了,有类似需求的朋友也可以使用。
新的负载均衡器
同时也支持了一个新的负载均衡器,解决了以下问题:
- 以前的负载均衡大量依赖 zk,当 topic 数量增多时对扩展性带来问题。
- 新的负载均衡器使用
non-persistent来存储负载信息,就不再依赖 zk 。
- 新的负载均衡器使用
- 以前的负载均衡器需要依赖
leader broker进行重定向到具体的 broker,其实这些重定向并无意义,徒增了系统开销。- 新的负载均衡器使用了 SystemTopic 来存放 topic 的所有权信息,这样每个 broker 都可以拿到数据,从而不再需要从 leader broker 重定向了。
更多完整信息可以参考这个 PIP: PIP-192: New Pulsar Broker Load Balancer
支持大规模延迟消息
第二个重大特性是支持大规模延迟消息,相信是有不少企业选择 Pulsar 也是因为他原生就支持延迟消息。
我们也是大量在业务中使用延迟消息,以往的延迟消息有着以下一些问题:
- 内存开销过大,延迟消息的索引都是保存在内存中,即便是可以分布在多个 broker 中分散存储,但消耗依然较大
- 重点优化了索引的内存占有量。
- 重启 broker 时会消耗大量时候重建索引
- 支持了索引快照,最大限度的降低了构建索引的资源消耗。
待优化功能
监控面板优化
最后即便是升级到了 3.0 依然还有一些待优化的功能,在之前的 从 Pulsar Client 的原理到它的监控面板中有提到给客户端加了一些监控埋点信息。
最终使用下来发现还缺一个 ack 耗时的一个面板,其实日常碰到最多的问题就是突然不能消费了(或者消费过慢)。
这时如果有这样的耗时面板,首先就可以定位出是否是消费者本身的问题。
目前还在开发中,大概类似于这样的数据。
总结
Pulsar3.0 是 Pulsar 的第一个 LTS 版本,推荐尽快升级可以获得长期支持。
但只要是软件就会有 bug,即便是 LTS 版本,所以大家日常使用碰到 Bug 建议多向社区反馈,一起推动 Pulsar 的进步。
Pulsar3.0新功能介绍的更多相关文章
- Redis 4.0新功能介绍
Redis 的作者 antirez 在三天之前通过博客文章<The first release candidate of Redis 4.0 is out>发布了 Redis 4.0 的第 ...
- Redis 5.0新功能介绍
Redis 5.0 Redis5.0版是Redis产品的重大版本发布,我们先看一下它的最新特点: 新的流数据类型(Stream data type) https://redis.io/topics/s ...
- Eviews 8.0&9.0界面新功能介绍
Eviews 8.0&9.0界面新功能介绍 本文其中一些是自己的整理,也有一些是经管之家论坛中一位热心.好学坛友的整理,其中只是简单介绍一下这两个新版本的部分特性,分享出来,有兴趣的看客可以一 ...
- Kafka 0.11新功能介绍:空消费组延迟rebalance
Kafka 0.11新功能介绍:空消费组延迟rebalance 在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer inst ...
- CentOS以及Oracle数据库发展历史及各版本新功能介绍, 便于构造环境时有个对应关系
CentOS版本历史 版本 CentOS版本号有两个部分,一个主要版本和一个次要版本,主要和次要版本号分别对应于RHEL的主要版本与更新包,CentOS采取从RHEL的源代码包来构建.例如CentOS ...
- 原创开源项目HierarchyViewer for iOS 2.1 Beta新功能介绍
回顾 HierarchyViewer for iOS是我们发布的一个开源项目,采用GPL v3.0协议. HierarchyViewer for iOS可以帮助iOS应用的开发和测试人员,在没有源代码 ...
- Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性 Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+ ...
- webpack 4.0.0-beta.0 新特性介绍
webpack 可以看做是模块打包机.它做的事情是:分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,TypeScript等),并将其打包为合适的格式 ...
- Apache Cassandra 4.0新特性介绍
引言 大家好,我是蔡一凡,是Cassandra的贡献者之一.(虽然我不便透露我的公司名称),但目前我们公司Cassandra的部署是全世界最大的之一,Cassandra在我们公司也有很多的应用. Ca ...
- ORM 创新解放劳动力 -SqlSugar 新功能介绍
介绍 SqlSugar是一款 老牌 .NET 开源ORM框架,由果糖大数据科技团队维护和更新 ,Github star数仅次于EF 和 Dapper 优点: 简单易用.功能齐全.高性能.轻量级.服务齐 ...
随机推荐
- Teamcenter RAC 开发之《Excel模版导出》
背景 在做 Teamcenter RAC客制化表单后,TMD肯定有一个需求要导出表单,毕竟所谓的客制化表单就是从纸质表单中出来的,那么写代码必不可少......... 那么问题来了,对于一个Excel ...
- IPv6的基本认识
IPv6 1.IPv6的基本认识 IPv4 位数是 32位,4字节,能够提供的IP地址大约是42亿,但你知道的,如今一个人都不止一个IP地址,看看如今设备的数量及发展速度就知道,所以有了IPv6,IP ...
- Update 1.82.1: The update addresses this security issue.
August 2023 (version 1.82) 更新后显示发行说明 Update 1.82.1: The update addresses this security issue. Welcom ...
- Go 代码块与作用域,变量遮蔽问题详解
Go 代码块与作用域详解 目录 Go 代码块与作用域详解 一.引入 二.代码块 (Block) 2.1 代码块介绍 2.2 显式代码块 2.3 隐式代码块 2.4 空代码块 2.5 支持嵌套代码块 三 ...
- 16.2 ARP 主机探测技术
ARP (Address Resolution Protocol,地址解析协议),是一种用于将 IP 地址转换为物理地址(MAC地址)的协议.它在 TCP/IP 协议栈中处于链路层,为了在局域网中能够 ...
- Go 常用标准库之 fmt 介绍与基本使用
Go 常用标准库之 fmt 介绍与基本使用 目录 Go 常用标准库之 fmt 介绍与基本使用 一.介绍 二.向外输出 2.1 Print 系列 2.2 Fprint 系列 2.3 Sprint 系列 ...
- Java文件与IO流
首先我们要清楚什么是流,正如其名,很形象,流就是像水一样的东西,具有方向性,在java中 ,流大概就是类 接下来,我们要对输入输出流有一个基本认识,什么是输入输出流呢? 输入输出明显需要一个参照,而这 ...
- Safepoints: Meaning, Side Effects and Overheads(译文)
Safepoints: Meaning, Side Effects and Overheads (安全点:含义.副作用和开销) 去年,我一直在进行有关profiling以及JVM运行时/执行的一些讨论 ...
- [数据校验/数据质量] 数据校验框架:hibernate-validation
0 前言 其一,项目中普遍遇到了此问题,故近两天深入地研究了一下. 其二,能够自信地说,仔细看完本篇,就无需再看其他的Java数据校验框架的文章了. 1 数据校验框架概述 1.0 数据校验框架的产生背 ...
- python计算代码运行时间
记录一下自己用python编写计算运行时间的代码 时间类 import time import numpy as np # 编写时间类来方便操作 class Timer: def __init__(s ...