Hession-free 的共轭梯度法的高效计算版本的部分代码(pytorch实现,实现一阶求导的一次计算重复使用)
Hession-free 的共轭梯度法的高效计算版本的部分代码(pytorch实现,实现一阶求导的一次计算重复使用)
Hession-free 的共轭梯度法在求解 H*v 的时候是先求一阶导,即雅可比向量,然后雅可比向量与向量v乘积后再求二导数,这样可以避免Hession矩阵在内存中的完全展开,减少内存消耗,使大规模矩阵的计算实现可行;但是该种传统的计算过程中会出现大量重复的对相同计算图的一阶求导,而这部分求导是在整个共轭梯度算法中保持不变的,我们完全可以避免掉这部分计算的重复进行,因此在pytorch版本中对一阶计算图求导时使用create_graph=True参数,而在二阶求导时使用retain_graph=True参数,这样我们就可以对一阶计算图进行重复使用。
给出部分代码,H*v部分代码:
import torch
w=torch.tensor([1.],requires_grad=True) # w=1
x=torch.tensor([2.],requires_grad=True) # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y, [w, x], create_graph=True)
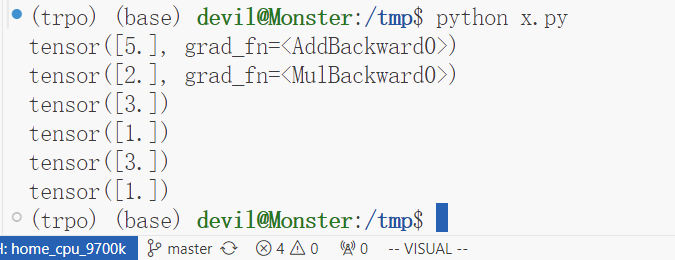
print(w_grad) # 2w+x+1 = 5
print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z, [w, x], retain_graph=True)
print(w_grad2) # 3
print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2, [w, x])
print(w_grad2) # 3
print(x_grad2) # 1
计算结果:
性能比较:一个简单例子
import torch
import numpy as np
import time
w=torch.tensor(torch.randn(10000), requires_grad=True) # w=1
x=torch.tensor(torch.randn(10000), requires_grad=True) # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
##########################################
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
a_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
b_t = time.time()
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
b2_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
c_t = time.time()
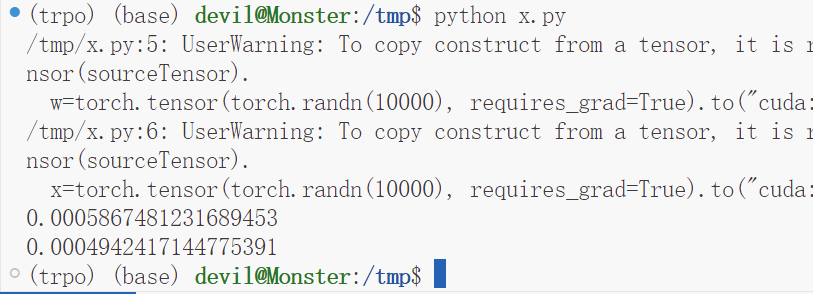
print(b_t - a_t)
print(c_t - b2_t)
运行结果:

可以看到,使用该种方法可以避免一次求导的重复进行,可以提速10%,虽然没有因为避免一阶求导的重复进行而省掉较大的计算时间,但是提速10%也算是不错的表现了,当然这个例子只是使用CPU进行的。
给出GPU版本:
点击查看代码
import torch
import numpy as np
import time
w=torch.tensor(torch.randn(10000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # w=1
x=torch.tensor(torch.randn(10000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
##########################################
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
a_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
b_t = time.time()
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
b2_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
c_t = time.time()
print(b_t - a_t)
print(c_t - b2_t)
运行结果:
可以看到,性能提升了15%左右。
更正:
上面的测评标准不是很正确,下面给出更正后的测评代码和性能表现:
import torch
import numpy as np
import time
w=torch.tensor(torch.randn(10000000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # w=1
x=torch.tensor(torch.randn(10000000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
##########################################
##########################################
a_t = time.time()
def f():
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
for i in range(5):
f()
###################################
###################################
b_t = time.time()
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
def f2():
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
for i in range(5):
f2()
c_t = time.time()
print(b_t - a_t)
print(c_t - b_t)
性能表现:


可以看到,用时为之前的32%,可以说提速了70%左右,可以看到在更正后的测评中本文提出的Hession-free的共轭梯度加速计算方法可以有不错的性能表现。
Hession-free 的共轭梯度法的高效计算版本的部分代码(pytorch实现,实现一阶求导的一次计算重复使用)的更多相关文章
- 【Java】一个小程序,计算它包含的代码所需的耗时
写一个小程序,用来计算它包含的代码所需的耗时.虽然简单,测试代码是否耗时还是有点用的,不用重新写嘛~ import java.util.Date; import java.util.concurren ...
- js学习笔记-编写高效、规范的js代码-Tom
编写高效.规范的js代码: 1.变量命名空间问题,尽量使用局部变量,防止命名冲突(污染作用域中的全局变量):全局空间命名的变量可以在对应的文档域任意位置中使用window调用. 2.尽量使用单var定 ...
- 基于jquery判断浏览器版本过低代码
基于jquery判断浏览器版本过低代码.这是一款对不支持HTML5跟CSS3代码的浏览器提示用户更换特效代码.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div sty ...
- 编写一个ComputerAverage抽象类,类中有一个抽象方法求平均分average,可以有参数。定义 Gymnastics 类和 School 类,它们都是 ComputerAverage 的子类。Gymnastics 类中计算选手的平均成绩的方法是去掉一个最低分,去掉一个最高分,然后求平均分;School 中计算平均分的方法是所有科目的分数之和除以总科目数。 要求:定义ComputerAv
题目: 编写一个ComputerAverage抽象类,类中有一个抽象方法求平均分average,可以有参数. 定义 Gymnastics 类和 School 类,它们都是 ComputerAverag ...
- 构建一个学生Student,根据类Student的定义,创建五个该类的对象,输出每个学生的信息,计算并输出这五个学生Java语言成绩的平均值,以及计算并输出他们Java语言成绩的最大值和最小值。
定义一个表示学生信息的类Student,要求如下: (1)类Student的成员变量: sNO 表示学号: sName表示姓名: sSex表示性别: sAge表示年龄: sJava:表示Java课程成 ...
- Git创建、diff代码、回退版本、撤回代码,学废了吗
.eye-care { background-color: rgba(199, 237, 204, 1); padding: 10px } .head-box { display: flex } .t ...
- Linux网络通信(线程池和线程池版本的服务器代码)
线程池 介绍 线程池: 一种线程使用模式.线程过多会带来调度开销,进而影响缓存局部性和整体性能.而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务.这避免了在处理短时间任务时创建与销毁线程的 ...
- 一个快速、高效的Levenshtein算法实现——代码实现
在网上看到一篇博客讲解Levenshtein的计算,大部分内容都挺好的,只是在一些细节上不够好,看了很长时间才明白.我对其中的算法描述做了一个简单的修改.原文的链接是:一个快速.高效的Levensht ...
- KubeEdge v0.2发布,全球首个K8S原生的边缘计算平台开放云端代码
KubeEdge开源背景 KubeEdge在18年11月24日的上海KubeCon上宣布开源,技术圈曾掀起一阵讨论边缘计算的风潮,从此翻开了边缘计算和云计算联动的新篇章. KubeEdge即Kube+ ...
- IE浏览器版本判断 HTML代码
<!--[if IE 6.0]> <div id="noie6" style="z-index: 20002;border: 1px solid #F7 ...
随机推荐
- 夜莺监控发布 v6.7 版本,推送部分商业版功能
熟悉夜莺的小伙伴都知道夜莺分为开源版.专业版.企业版,三个版本良性发展.近期夜莺团队发布了 v6.7 版本,把机器Metadata管理功能推送到了开源版,下面是该功能的简单介绍. 如上图,机器列表页面 ...
- Mysql常见安装失败的解决方法
问题一:安装时出现Initializing database失败 解决方法: 1.关闭安装页面并卸载MySQL Installer与MySQL Server (如果卸载不掉需要重启电脑) 2.查看并勾 ...
- 前端使用 Konva 实现可视化设计器(16)- 旋转对齐、触摸板操作的优化
这一章解决两个缺陷,一是调整一些快捷键,使得 Mac 触摸板可以正常操作:二是修复一个 Issue,使得即使素材节点即使被旋转之后,也能正常触发磁贴对齐效果,有个小坑需要注意. 请大家动动小手,给我一 ...
- OpenSSL&&libcurl库的交叉编译
一.编译前环境准备 使用的内核:4.15.0-118-generic(命令:uname -r可以查看) 交叉编译器:aarch64-linux-gnu-gcc curl源码:curl-7.72.0.t ...
- Lfu缓存在Rust中的实现及源码解析
一个 lfu(least frequently used/最不经常使用页置换算法 ) 缓存的实现,其核心思想是淘汰一段时间内被访问次数最少的数据项.与LRU(最近最少使用)算法不同,LFU更侧重于数据 ...
- 执行insmod提示 invalid module format
内核版本和驱动版本不匹配: 1.假如内核版本是2018.3,驱动使用了另外一个版本,可能会出现这样的问题 2.内核和驱动版本一致,但内核进行了一些配置,导致驱动装不上,此时应该: make clean ...
- V4L2视频采集操作流程和接口说明
背景: V4L2是V4L的升级版本,为linux下视频设备程序提供了一套接口规范.包括一套数据结构和底层V4L2驱动接口. <WAV文件格式分析> 一般操作流程(视频设备): 1.打开设备 ...
- sql-labs通关笔记(上)
sql-labs通关笔记(上) 这里我们先只讲解less-1到less-9 联合查询注入 Less-1:GET -Error based.Single quotes -string 界面 在url中加 ...
- webdav协议及我的笔记方案(私有部署)
背景 用markdown用于文章写作,有几年时间了,不是很喜欢折腾,主要就是在电脑上写,用的笔记软件就是typora.由于里面有很多工作相关的,以及个人资料相关的(包含了各种账号.密码啥的),所以不敢 ...
- 面试题:Linux 系统基础提问 (一)
Linux系统中如何管理用户和组? Linux系统中用户和组的管理通常包括以下几个方面: 1.创建用户和组: 使用useradd和groupadd命令创建新用户和新组. 2.修改用户和组信息: 使用u ...