Hession-free 的共轭梯度法的高效计算版本的部分代码(pytorch实现,实现一阶求导的一次计算重复使用)
Hession-free 的共轭梯度法的高效计算版本的部分代码(pytorch实现,实现一阶求导的一次计算重复使用)
Hession-free 的共轭梯度法在求解 H*v 的时候是先求一阶导,即雅可比向量,然后雅可比向量与向量v乘积后再求二导数,这样可以避免Hession矩阵在内存中的完全展开,减少内存消耗,使大规模矩阵的计算实现可行;但是该种传统的计算过程中会出现大量重复的对相同计算图的一阶求导,而这部分求导是在整个共轭梯度算法中保持不变的,我们完全可以避免掉这部分计算的重复进行,因此在pytorch版本中对一阶计算图求导时使用create_graph=True参数,而在二阶求导时使用retain_graph=True参数,这样我们就可以对一阶计算图进行重复使用。
给出部分代码,H*v部分代码:
import torch
w=torch.tensor([1.],requires_grad=True) # w=1
x=torch.tensor([2.],requires_grad=True) # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y, [w, x], create_graph=True)
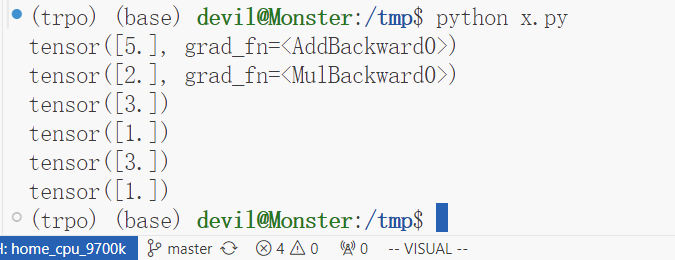
print(w_grad) # 2w+x+1 = 5
print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z, [w, x], retain_graph=True)
print(w_grad2) # 3
print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2, [w, x])
print(w_grad2) # 3
print(x_grad2) # 1
计算结果:
性能比较:一个简单例子
import torch
import numpy as np
import time
w=torch.tensor(torch.randn(10000), requires_grad=True) # w=1
x=torch.tensor(torch.randn(10000), requires_grad=True) # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
##########################################
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
a_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
b_t = time.time()
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
b2_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
c_t = time.time()
print(b_t - a_t)
print(c_t - b2_t)
运行结果:

可以看到,使用该种方法可以避免一次求导的重复进行,可以提速10%,虽然没有因为避免一阶求导的重复进行而省掉较大的计算时间,但是提速10%也算是不错的表现了,当然这个例子只是使用CPU进行的。
给出GPU版本:
点击查看代码
import torch
import numpy as np
import time
w=torch.tensor(torch.randn(10000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # w=1
x=torch.tensor(torch.randn(10000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
##########################################
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
a_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
b_t = time.time()
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
b2_t = time.time()
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
c_t = time.time()
print(b_t - a_t)
print(c_t - b2_t)
运行结果:
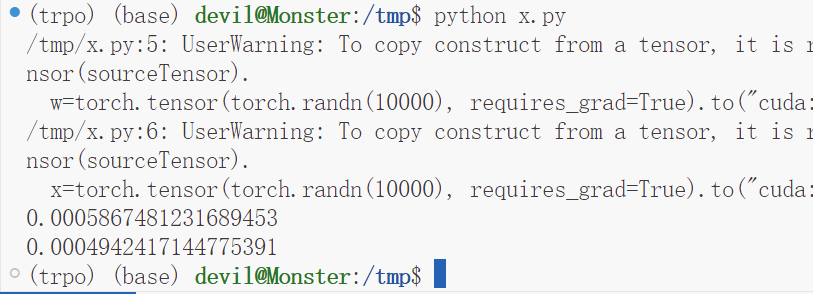
可以看到,性能提升了15%左右。
更正:
上面的测评标准不是很正确,下面给出更正后的测评代码和性能表现:
import torch
import numpy as np
import time
w=torch.tensor(torch.randn(10000000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # w=1
x=torch.tensor(torch.randn(10000000), requires_grad=True).to("cuda:0" if torch.cuda.is_available() else "cpu") # x=2
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
z2 = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z2.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
##########################################
##########################################
a_t = time.time()
def f():
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x])
# print(w_grad2) # 3
# print(x_grad2) # 1
for i in range(5):
f()
###################################
###################################
b_t = time.time()
a=torch.add(w,x) # a = w+x
b=torch.add(w,1) # b = w+1
y=torch.mul(a,b) # y = w**2+w*x+w+x
# w_grad, x_grad = torch.autograd.grad(y, [w, x], retain_graph=True, create_graph=True)
w_grad, x_grad = torch.autograd.grad(y.mean(), [w, x], create_graph=True)
# print(w_grad) # 2w+x+1 = 5
# print(x_grad) # w+1 = 2
def f2():
z = w_grad + x_grad
w_grad2, x_grad2 = torch.autograd.grad(z.mean(), [w, x], retain_graph=True)
# print(w_grad2) # 3
# print(x_grad2) # 1
for i in range(5):
f2()
c_t = time.time()
print(b_t - a_t)
print(c_t - b_t)
性能表现:


可以看到,用时为之前的32%,可以说提速了70%左右,可以看到在更正后的测评中本文提出的Hession-free的共轭梯度加速计算方法可以有不错的性能表现。
Hession-free 的共轭梯度法的高效计算版本的部分代码(pytorch实现,实现一阶求导的一次计算重复使用)的更多相关文章
- 【Java】一个小程序,计算它包含的代码所需的耗时
写一个小程序,用来计算它包含的代码所需的耗时.虽然简单,测试代码是否耗时还是有点用的,不用重新写嘛~ import java.util.Date; import java.util.concurren ...
- js学习笔记-编写高效、规范的js代码-Tom
编写高效.规范的js代码: 1.变量命名空间问题,尽量使用局部变量,防止命名冲突(污染作用域中的全局变量):全局空间命名的变量可以在对应的文档域任意位置中使用window调用. 2.尽量使用单var定 ...
- 基于jquery判断浏览器版本过低代码
基于jquery判断浏览器版本过低代码.这是一款对不支持HTML5跟CSS3代码的浏览器提示用户更换特效代码.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div sty ...
- 编写一个ComputerAverage抽象类,类中有一个抽象方法求平均分average,可以有参数。定义 Gymnastics 类和 School 类,它们都是 ComputerAverage 的子类。Gymnastics 类中计算选手的平均成绩的方法是去掉一个最低分,去掉一个最高分,然后求平均分;School 中计算平均分的方法是所有科目的分数之和除以总科目数。 要求:定义ComputerAv
题目: 编写一个ComputerAverage抽象类,类中有一个抽象方法求平均分average,可以有参数. 定义 Gymnastics 类和 School 类,它们都是 ComputerAverag ...
- 构建一个学生Student,根据类Student的定义,创建五个该类的对象,输出每个学生的信息,计算并输出这五个学生Java语言成绩的平均值,以及计算并输出他们Java语言成绩的最大值和最小值。
定义一个表示学生信息的类Student,要求如下: (1)类Student的成员变量: sNO 表示学号: sName表示姓名: sSex表示性别: sAge表示年龄: sJava:表示Java课程成 ...
- Git创建、diff代码、回退版本、撤回代码,学废了吗
.eye-care { background-color: rgba(199, 237, 204, 1); padding: 10px } .head-box { display: flex } .t ...
- Linux网络通信(线程池和线程池版本的服务器代码)
线程池 介绍 线程池: 一种线程使用模式.线程过多会带来调度开销,进而影响缓存局部性和整体性能.而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务.这避免了在处理短时间任务时创建与销毁线程的 ...
- 一个快速、高效的Levenshtein算法实现——代码实现
在网上看到一篇博客讲解Levenshtein的计算,大部分内容都挺好的,只是在一些细节上不够好,看了很长时间才明白.我对其中的算法描述做了一个简单的修改.原文的链接是:一个快速.高效的Levensht ...
- KubeEdge v0.2发布,全球首个K8S原生的边缘计算平台开放云端代码
KubeEdge开源背景 KubeEdge在18年11月24日的上海KubeCon上宣布开源,技术圈曾掀起一阵讨论边缘计算的风潮,从此翻开了边缘计算和云计算联动的新篇章. KubeEdge即Kube+ ...
- IE浏览器版本判断 HTML代码
<!--[if IE 6.0]> <div id="noie6" style="z-index: 20002;border: 1px solid #F7 ...
随机推荐
- k8s搭建安装 Harbor 私有镜像仓库(本地仓库,内网仓库)
主要参考 https://www.cnblogs.com/wangzy-Zj/p/14011228.html 额外: 1.如果 harbor.yml中的域名和openssl 生成的不一致,你改了hos ...
- C#.NET Winform使用线程承载WCF (硬编码配置)
winform同步承载WCF时,遇到大量请求,可能会阻塞UI线程.这时就需要开个线程来承载WCF. 1.硬编码形式创建WCF服务,WCFServer类: using CommonUtils; usin ...
- 流程控制之case
1.case语句作用 case和if一样,都是用于处理多分支的条件判断 但是在条件较多的情况,if嵌套太多就不够简洁了 case语句就更简洁和规范了 2.case用法参考 常见用法就是如根据用户输入的 ...
- Docker中部署单机Redis详细教程
1.拉取Redis镜像 # 拉取redis镜像,不指定版本则默认是最新版本 docker pull redis 2.查看镜像 # 列出本地镜像 docker images 3.准备配置文件路径 # 创 ...
- 实验8.Vlan Hybrid实验
# 实验8.Vlan Hybrid实验 本实验用于测试华为独有的混合式接口类型hybrid 实验组 配置交换机 对交换机sw1与sw2做具体配置 SW1 vlan ba 10 20 100 int g ...
- Freertos学习:00-介绍
--- title: rtos-freertos-000-介绍 EntryName: rtos-freertos-00-about date: 2020-06-09 23:21:44 categori ...
- Coap 协议学习:1-有关概念
COAP协议简介 不像人接入互联网的简单方便,由于物联网设备大多都是资源限制型的,有限的CPU.RAM.Flash.网络宽带等.对于这类设备来说,想要直接使用现有网络的TCP和HTTP来实现设备实现信 ...
- CF1864F 题解
写了一小时结果被卡常了(笑. 考虑新加入一个数什么时候会产生贡献,或者什么时候不会产生贡献. 发现当一个数的位置与他前一次出现时的位置所构成的区间内假若有一个比它小的数那么就不得不对这个数新进行一次操 ...
- JDK1.8新特性Lambda表达式简化if-else里都有for循环的优化方式
在日常开发过程当中,能把代码写出来,不一定就意味着能把代码写好,说不准,所写的代码在他人看来,其实就是一坨乱七八糟的翔,因此,代码简化尤其重要,我曾经遇到过这样一个类型的代码,即if-else里都有相 ...
- SQLserver中的存储过程
变量分为: ->局部变量: •局部变量必须以标记@作为前缀 ,如@Age int •局部变量:先声明,再赋值 1 -- 语法:声明一个变量,然后赋值,打印出来 2 -- 第一步 3 declar ...