Jax框架 —— 如何在没有GPU和TPU的设备上debug代码 —— 在CPU上使用GPU仿真设置 —— Jax框架在多卡设备上的自动并行特性的仿真体验
Jax计算框架是Google用来取代Tensorflow的新一代计算框架,这个框架使用类似pytorch的技术,但是在pytorch技术之上加入了更加强大的技术,但是这也导致该框架使用起来要比pytorch难一些,但是该框架的计算性能又比较优秀,因此依旧具有较大的吸引力。
Jax框架的性能优势主要体现在单机多卡GPU设备的自动并行上,Jax和TensorFlow同样有着编译器的优势,Jax可以通过简单的代码编写实现多卡并行的方式,在数据并行和模型并行的基础之上又实现了数据切割并行的方式,可以说Jax框架在原生水平上支持目前所有的并行操作,并且在并行的代码编写上又比pytorch更加简单,但是由于并行的复杂性,Jax的自动并行往往有着不好掌握的特点,虽然在编写上代码更加精炼,但是逻辑难度加大了,不容易掌握。
可以说,Jax对于pytorch来说最大的优点就是对于多卡设备,或者说是大规模计算的原生支持上,比如在Jax官方的讲解文档之中都是默认对8个TPU进行操作的,为实现同样的操作(代码可运行),我们也需要使用8个卡的GPU,这个要求虽然对于企业来说都是极为容易实现的,但是对于个人用户这个要求却是极为困难的。如果没有多卡的运行环境,我们也就无法体验Jax框架的特性。
为了方便体验和debug Jax框架的多卡自动计算的特性,Jax框架给出了多卡仿真的设置参数:
官方文档:
https://jax.readthedocs.io/en/latest/jax-101/06-parallelism.html
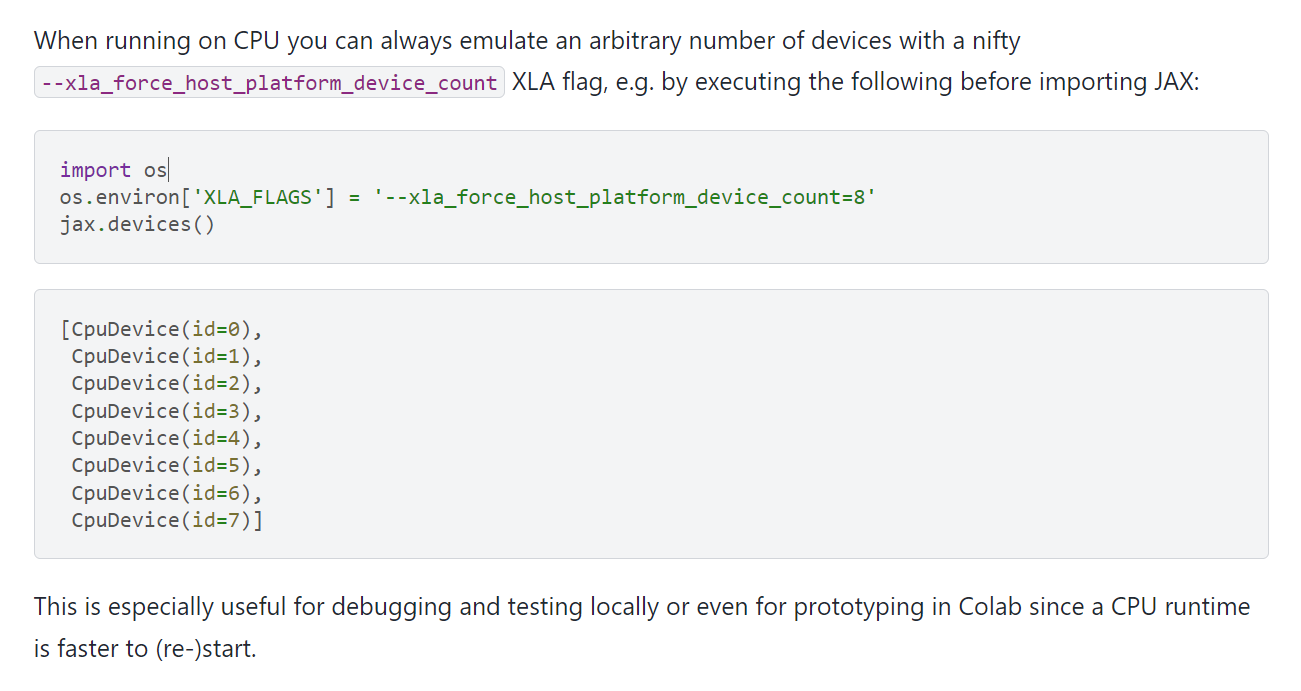
不过要注意的是,这个仿真设置的前提是本机没有GPU或TPU设备,然后才可以进行GPU和TPU的仿真设置,比如本地主机有两个GPU,那么是无法实现该仿真设置的:
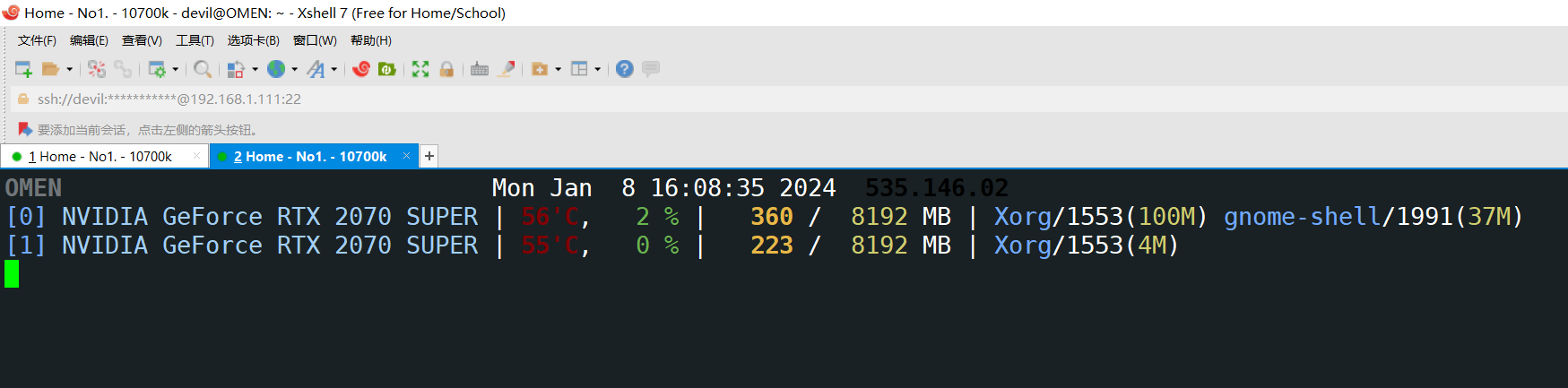
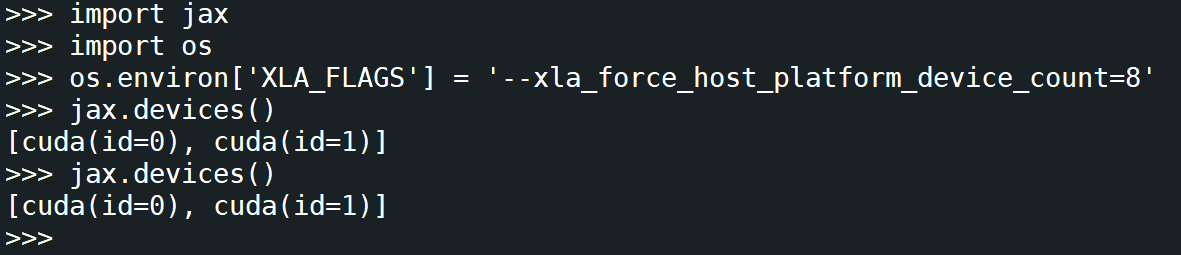
可以看到,在本地存在GPU或TPU设备的时候,是无法实现仿真环境设置的。比如我这个环境下就有两个GPU,但是由于Jax的运行特性往往是在多卡(8卡以上的主机环境)下,因此我们要运行调试一个8卡的Jax环境我们就需要Jax的多卡仿真,使用CPU仿真出8个GPU和TPU,这时我们就需要把真实存在的GPU或TPU屏蔽掉(因为物理真实存在的GPU数太少,无法调试Jax的多卡大规模计算代码):
屏蔽已有的真实物理GPU或TPU:
export CUDA_VISIBLE_DEVICES=-1
屏蔽掉真实存在的两个物理GPU后,用CPU仿真出8个卡的运行环境:(注意,这里是使用CPU仿真8个卡的环境,只能作为调试之用,判断Jax的多卡运行的代码的正取与否,并不能获得真实8卡的计算性能,要注意,这里只是使用CPU仿真8个GPU):

给出 Jax 框架的CPU仿真多卡GPU的代码:
import os
os.environ['XLA_FLAGS'] = '--xla_force_host_platform_device_count=8'
jax.devices()
Jax框架 —— 如何在没有GPU和TPU的设备上debug代码 —— 在CPU上使用GPU仿真设置 —— Jax框架在多卡设备上的自动并行特性的仿真体验的更多相关文章
- CPU GPU FPU TPU 及厂商
1,AMD 既做CPU又做显卡2,Inter 全球最大的CPU厂商,GPU,FPGA3,NVIDA 人工智能起家的公司,且一直在做,显卡最出名,CUDA让N卡胜了AMD CPU上 AMD - Inte ...
- 学习笔记TF046:TensoFlow开发环境,Mac、Ubuntu/Linux、Windows,CPU版本、GPU版本
下载TensorFlow https://github.com/tensorflow/tensorflow/tree/v1.1.0 .Tags选择版本,下载解压. pip安装.pip,Python包管 ...
- (译)综合指南:通过Ubuntu 16.04上从Source构建来安装支持GPU的Caffe2
(译)综合指南:通过Ubuntu 16.04上从Source构建来安装支持GPU的Caffe2 译者注: 原文来自:https://tech.amikelive.com/node-706/compre ...
- mesos支持gpu代码分析以及capos支持gpu实现
这篇文章涉及mesos如何在原生的mesoscontainerizer和docker containerizer上支持gpu的,以及如果自己实现一个mesos之上的framework capos支持g ...
- tensorflow 使用CPU而不使用GPU的问题解决
今天发现一个怪现象,在训练keras时,发现不使用GPU进行计算,而是采用CPU进行计算,导致计算速度很慢. 用如下代码可检测tensorflow的能使用设备情况: from tensorflow.p ...
- 关于使用实验室服务器的GPU以及跑上TensorFlow代码
连接服务器 Windows - XShell XFtp SSH 通过SSH来连接实验室的服务器 使用SSH连接已经不陌生了 github和OS课设都经常使用 目前使用 192.168.7.169 使用 ...
- FIR特性及仿真实现_01
作者:桂. 时间:2018-02-05 19:01:21 链接:http://www.cnblogs.com/xingshansi/p/8419007.html 前言 本文主要记录FIR(finit ...
- Android sync adapter初体验之为什么官方文档上的代码不能work
回答:因为其实可以work sync adapter就是google推出的一个同步框架,把各种同步操作放在一起智能管理比较省电之类的.对我而言最具体的好处反正就是,不用自己写代码了,用框架就可以了.目 ...
- 在 Ubuntu16.04上安装anaconda+Spyder+TensorFlow(支持GPU)
TensorFlow 官方文档中文版 http://www.tensorfly.cn/tfdoc/get_started/introduction.html https://zhyack.github ...
- 《深度学习框架PyTorch:入门与实践》的Loss函数构建代码运行问题
在学习陈云的教程<深度学习框架PyTorch:入门与实践>的损失函数构建时代码如下: 可我运行如下代码: output = net(input) target = Variable(t.a ...
随机推荐
- OpenSearch 与 Elasticsearch:哪个开源搜索引擎适合您?
当谈论到搜索引擎产品时,Elasticsearch 和 OpenSearch 是两个备受关注的选择.它们都以其出色的功能和灵活性而闻名,但在一些方面存在一些差异.在本文中,我们将从功能和延展性.工具与 ...
- go 1.6 废弃 io/ioutil 包后的替换函数
go 1.6 废弃 io/ioutil 包后的替换函数 io/ioutil 替代 ioutil.ReadAll -> io.ReadAll ioutil.ReadFile -> os.R ...
- The model backing the 'MainDbContext' context has changed since the database was created. Consider using Code First Migrations to update the database (http://go.microsoft.com/fwlink/?LinkId=238269).
The model backing the 'MainDbContext' context has changed since the database was created. Consider u ...
- BC6-牛牛的第二个整数
题目描述 牛牛从键盘上输入三个整数,并尝试在屏幕上显示第二个整数. 输入描述 一行输入 3 个整数,用空格隔开. 输出描述 请输出第二个整数的值. 示例 1 输入:1 2 3 输出:2 解题思路 方案 ...
- 面试官:Java中缓冲流真的性能很好吗?我看未必
一.写在开头 上一篇文章中,我们介绍了Java IO流中的4个基类:InputStream.OutputStream.Reader.Writer,那么这一篇中,我们将以四个基类所衍生出来,应对不同场景 ...
- Sealos 5.0 正式发布,云本应该是操作系统
把所有资源抽象成一个整体,一切皆应用,这才是云应该有的样子. 2018 年 8 月 15 日 Sealos 提交了第一行代码. 随后开源社区以每年翻倍的速度高速增长. 2022 年我们正式创业,经历一 ...
- xpath-猪八戒网服务商名称爬取
import requests from lxml import etree url = 'https://changsha.zbj.com/xcxkfzbjzbj/f.html?fr=zbj.sy. ...
- 【electron-vite+live2d+vue3+element-plus】实现桌面模型宠物+桌面管理系统应用(踩坑)
脚手架 项目使用 electron-vite 脚手架搭建 ps:还有一个框架是 electron-vite ,这个框架我发现与pixi库有冲突,无法使用,如果不用pixi也可以用这个脚手架. node ...
- mermaid语法画图
mermaid 脚本语言 graph TB 从上到下 graph BT 从下到上 graph RL 从右到左 graph LR 从左到右 graph LR; A001-->B001; graph ...
- JVM(Java虚拟机) 整理(一):基础理论
JVM整体结构 本文主要说的是HotSpot虚拟机, JVM 全称是 Java Virtual Machine,中文译名:Java虚拟机 简化一下: Java字节码文件 Class文件本质上是一个以8 ...