强化学习:一种新的并行算法下的参数同步更新方式——半异步更新方式——( 同步、异步 -> 半异步 )
Abstract:
并行算法下的参数同步方式一般有同步更新和异步更新两种方式,本文在此基础之上提出了一种新的参数同步方式——半异步更新方式。
Introduction:
这里用神经网络举例子,也就是神经网络的并行中的参数同步的情况,给出同步、异步方式:
同步:
各个客户端分别各自运行神经网络的前向和后向操作,计算出梯度;各个客户端把计算出的梯度发送给服务器端,并且进入阻塞状态,等待服务器发送回新的参数;服务器需要收到所有客户端的梯度参数,汇总后计算出新的参数,然后再发送给所有客户端,因此每一个batch的计算中所有的客户端都进行了同步。
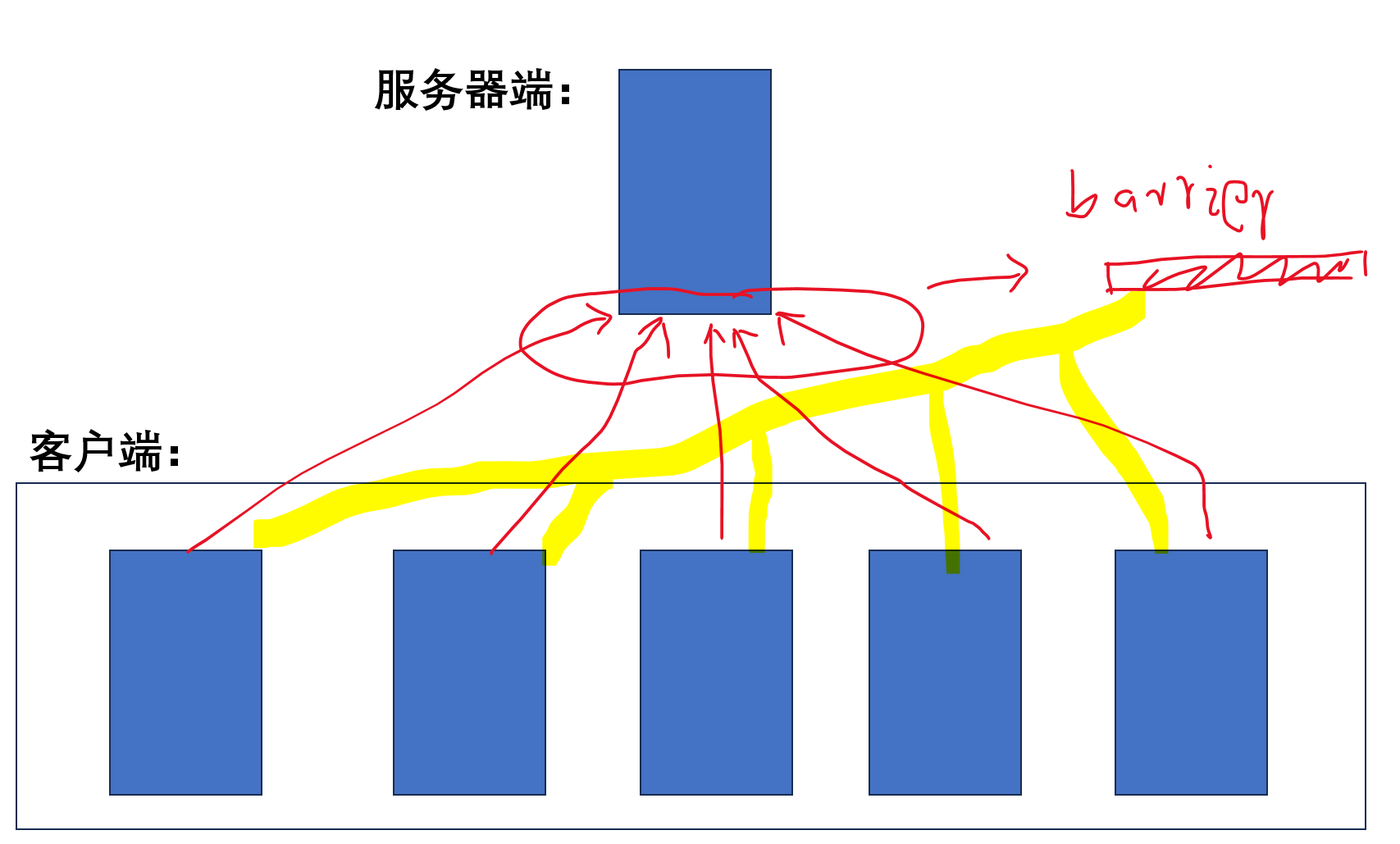
==========================================
异步:
各个客户端分别各自运行神经网络的前向和后向操作,计算出梯度;各个客户端把计算出的梯度发送给服务器端,并且进入阻塞状态,等待服务器发送回新的参数;服务器不需要进入阻塞以等待收到所有客户端的梯度参数而是每收到一个客户端发送的梯度参数就可以进入汇总计算并得出新的参数,然后再发送给当前的客户端,因此所有客户端在和服务器端同步的同时其实各个客户端是在异步运行的。
同步的更新方式:
优点:运行稳定,可复现性高;缺点:计算效率低,吞吐量低,大量时间都花费在了各个客户端的同步阻塞上了。
异步的更新方式:
优点:计算效率高,吞吐量高; 缺点:运行不稳定,可复现性不高,多次试验的结果往往有较大差异,各个客户端完全异步运行,硬件利用率更高。
个人观点:
由于同、异步更新方式的不同,应用场景也不同;对于性能比较稳定的算法,为了得到更快的运算,往往使用异步方式并行,但是对于一些本身运行效果不稳定(串行情况下)的算法就难以使用异步更新的方式,因为这样虽然可以提高计算吞吐量,但是由于加剧了算法的不稳定性,往往导致算法难以收敛,甚至会导致算法无法收敛;因此,在很多的并行软件中并没有支持异步更新方式,比如pytorch框架,在很长的时间里(7、8年)都是不支持异步更新的,而往往异步更新也更加的复杂,对工程技术方面要求的也更加高,比如深度学习框架中也只有Google推出的TensorFlow才原生支持异步更新。
对于监督学习这类比较稳定的算法,我们在并行时往往可以采用异步更新的方式,但是由于其复现性较差,因此在学术界往往也不太会使用,而使用的一般也都是工业界。
对于强化学习算法这样往往本身就不稳定,收敛困难的算法,使用异步的方式虽然增加了计算吞吐量但是会导致算法难以收敛,甚至训练失败,这也是经典的强化学习算法A3C由异步改为同步的A2C后就获得了几倍运行速度的提升,虽然单位时间的计算吞吐量变小了,但是收敛更快了,反而使同步的强化学习算法表现远远高于异步情况。
------------------------------------------------
Our proposed algorithm:
半异步更新
这里依旧以神经网络举例,我们可以在异步更新的方式上进行改进。以往的异步更新都是收到一个客户端的参数梯度后并和服务器上的参数进行合并然后得到新的参数更新给客户端和自身,但是这种方式在提高计算效率的同时造成了收敛性受损的问题,因此我们可以设置某个数值n,假设共有100个客户端,我们可以设置n=20,也就是说服务器在收到20个客户端的梯度后才进行合并和更新;更加详细的说,就是第0-18号客户端的参数发送给服务器端后并不进入阻塞,而是直接使用现有参数进行后续的计算,只有当第20个客户端,也即19号客户端发送给服务器梯度后服务器才进行汇总计算,此时第19号客户端也进入阻塞并等待服务器更新后的参数;此后的所有客户端发送给服务器梯度后都会比较下自己的参数是否比服务器上的参数落后,如果落后则进入阻塞等待服务器发送给自己更新的参数,而服务器的参数更新都是需要等待n=20个客户端参数后才进行更新。
该种算法设计必然会导致各别客户端参数远远落后于服务器端参数,我们假设服务器端现有的参数更新次数为C,客户端持有的参数为X,X<=C,如果C-X<=3,那么服务器上记录收到的参数副本个数的参数R则自加1,即R++;如果C-X<=5,那么已然对收到的参数进行合并操作,但是此时不对R值进行操作,依然需要等待R==20时才汇总计算并更新服务器参数;当C-X>5时,则意味着该客户端的参数已远远落后于服务器端,因此只返回给该客户端最新参数,但是不对R值进行任何操作,并且将该客户端发送的梯度弃用。这个算法就是本文所提的半异步更新方式,在使并行算法具备异步更新的高吞吐量的同时也使算法具备一定同步更新算法的稳定性。
----------------------------------------------------------
--------------------------------------------------
parameter:客户端数量N=100,服务器端进行梯度合并和更新参数时接收客户端参数数量n=20,客户端参数更新的计数值X,服务器端参数更新的计数值C,服务器端已接受的客户端参数副本数量值R;
----------------------------------------
服务器端:
while True:
receive (客户端id,客户端梯度,客户端参数的更新计数X);客户端进入阻塞状态;
if C-X<=3: 接收客户端梯度,R++;
elif C-X<=5: 接收客户端梯度;
elif C-X>5: 拒绝接收客户端梯度;
if R==20: 将收集到的客户端梯度汇总并计算,更新服务器端参数;C++;R重新赋值为0;
if X<C:将服务器端参数更新给客户端;
结束客户端的阻塞状态;
----------------------------------------
客户端:
while True:
send (客户端id,客户端梯度,客户端参数的更新计数X);客户端进入阻塞状态;
接收服务器端指令,如果结束阻塞继续计算;如果接收服务器参数,则X++,更新参数,然后继续计算;
继续计算任务,得到新的梯度值;
----------------------------------------
==========================================
强化学习:一种新的并行算法下的参数同步更新方式——半异步更新方式——( 同步、异步 -> 半异步 )的更多相关文章
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- WPF学习开发客户端软件-任务助手(下 2015年2月4日代码更新)
时光如梭,距离第一次写的 WPF学习开发客户端软件-任务助手(已上传源码) 已有三个多月,期间我断断续续地对该项目做了优化.完善等等工作,现在重新向大家介绍一下,希望各位可以使用,本软件以实用性为主 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 强化学习 平台 openAI 的 gym 安装 (Ubuntu环境下如何安装Python的gym模块)
openAI 公司给出了一个集成较多环境的强化学习平台 gym , 本篇博客主要是讲它怎么安装. openAI公司的主页: https://www.openai.com/systems/ 从主页上我 ...
- Ubuntu下常用强化学习实验环境搭建(MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
http://lib.csdn.net/article/aimachinelearning/68113 原文地址:http://blog.csdn.net/jinzhuojun/article/det ...
- 【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法
原文地址: baijiahao.baidu.com/s?id=1600509777750939986&wfr=spider&for=pc 机器之心 18-05-15 14:26 - ...
- ReLeQ:一种自动强化学习的神经网络深度量化方法
ReLeQ:一种自动强化学习的神经网络深度量化方法 ReLeQ:一种自动强化学习的神经网络深度量化方法ReLeQ: An Automatic Reinforcement Learning Ap ...
- 今天在研究jquery用ajax提交form表单中得数据时,学习到了一种新的提交方式
今天在研究jquery用ajax提交form表单中得数据时,学习到了一种新的提交方式 jquery中的serialize() 方法 该方法通过序列化表单值,创建 URL 编码文本字符串 序列化的值可在 ...
- 深度学习实战-强化学习-九宫格 当前奖励值 = max(及时奖励 + 下一个位置的奖励值 * 奖励衰减)
强化学习使用的是bellmen方程,即当前奖励值 = max(当前位置的及时奖励 + discout_factor * 下一个方向的奖励值) discount_factor表示奖励的衰减因子 使用 ...
随机推荐
- 记一次 React context 使用
学习 React 之 Context 使用 记录一次React context 使用 React.createContext Api 新建文件 contexts.js 文件用来存放 context 对 ...
- json LocalDateTime转对象
json LocalDateTime转对象 feign.codec.DecodeException: JSON parse error: Can not deserialize instance of ...
- Thread交互及interrupt示例
package com.test.docxml; /** Thread交互及interrupt示例 * 线程模拟:一个在睡觉,一个在敲墙,敲墙完成之后,把睡觉的吵醒了. */ public class ...
- MySQL where 操作符
MySql WHERE 操作符号 前言 在 WHERE 子句中,你可以使用任何条件对记录进行过滤. 准备工作 准备 users 表,并插入数据 # 创建用户表 users create table u ...
- SpringCloud开发之OpenFeign timeout和压缩等问题
在某些时候,我们希望某个同步调用执行更长的时间(异步暂时不考虑),这个时候,首先就是要设置OpenFeign的timeout设定. 下面我们举例来说明,可以如何设定TimeOut参数. 一.环境 脱离 ...
- Pytorch复制现有环境
一,在本机上,打开anaconda Prompt直接使用 conda create -n 新环境名 --clone 旧环境名
- k8s健康检查(探针Probe)之LivenessProbe、ReadinessProbe和StartupProbe
背景 集群正常服务时,会出现容器死掉问题,如宿主机故障.资源不足.下游故障等.这个时候容器需要从endpoints摘除(容器挂了就不能接流了),并执行它的restart策略. LivenessProb ...
- 开启PHP-GD库
话不多说,上教程 环境 CentOS7 1. 安装php-gd yum install php-gd 2. 定位gd.so位置 rpm -qal | grep gd.so #第一行即是 3. 定位配置 ...
- 带有ttl的Lru在Rust中的实现及源码解析
TTL是Time To Live的缩写,通常意味着元素的生存时间是多长. 应用场景 数据库:在redis中我们最常见的就是缓存我们的数据元素,但是我们又不想其保留太长的时间,因为数据时间越长污染的可能 ...
- CLR via C# 笔记 -- 线程基础(26)
1. Microsoft 设计这个OS内核时,决定在一个进程中运行应用程序的每个实例.进程实际是应用程序的实例要使用的资源的集合.每个进程都被赋予了一个虚拟地址空间,确保在一个进程中使用的代码和数据无 ...