[转帖]LSM-Tree:从入门到放弃——入门:基本概念、操作和Trade-Off分析
https://zhuanlan.zhihu.com/p/428267241
LSM-Tree,全程为日志结构合并树,有趣的是,这个数据结构实际上重点在于日志结构合并,和 tree 本身的关系并不是特别大(除了各种可能的天外飞仙式的工程优化,一般来说只有 level0 采用了平衡树的结构)
LSM-Tree 通过“极端”的磁盘顺序写的方案,通常有极其离谱的写吞吐量,被大量应用于Cassandra、LevelDB、RocksDB、HBase等 NoSQL 数据库底层存储引擎中。
LSM-Tree 通常没有一种固定死的实现方式,更多的是一系列符合以下设计方法论的思想构成的实现:
- 多个横跨内存和磁盘的树状数据结构构成的森林
- 不同 level (一般来说也可以理解为新旧或冷热)数据分级,从 level-0 到 level-n ,一般只有 level-0 在内存中,其他的level通常落在磁盘上。
- level-0 通常采用平衡的排序树、跳表或 TreeMap 等有序的数据结构,方便从内存顺序写到磁盘中。磁盘中的 level 本质是排序好后 appendonly 写到磁盘上的文件(也可以认为是中序遍历后的“树”)。
- 定期归并,每层子树一般有一个阈值大小,达到阈值后会归并本 level 的块并到下一 level。
- 通常只允许内存中的 level (一般特指 level-0 )原地更新,磁盘上不允许数据变更,而是选择采用 appendonly 的方式写日志。
符合以上定义的实现构成了一般意义上我们理解的 LSM-Tree。构成如下图的结构(图片来自知乎用户康乐为撰写的文章):
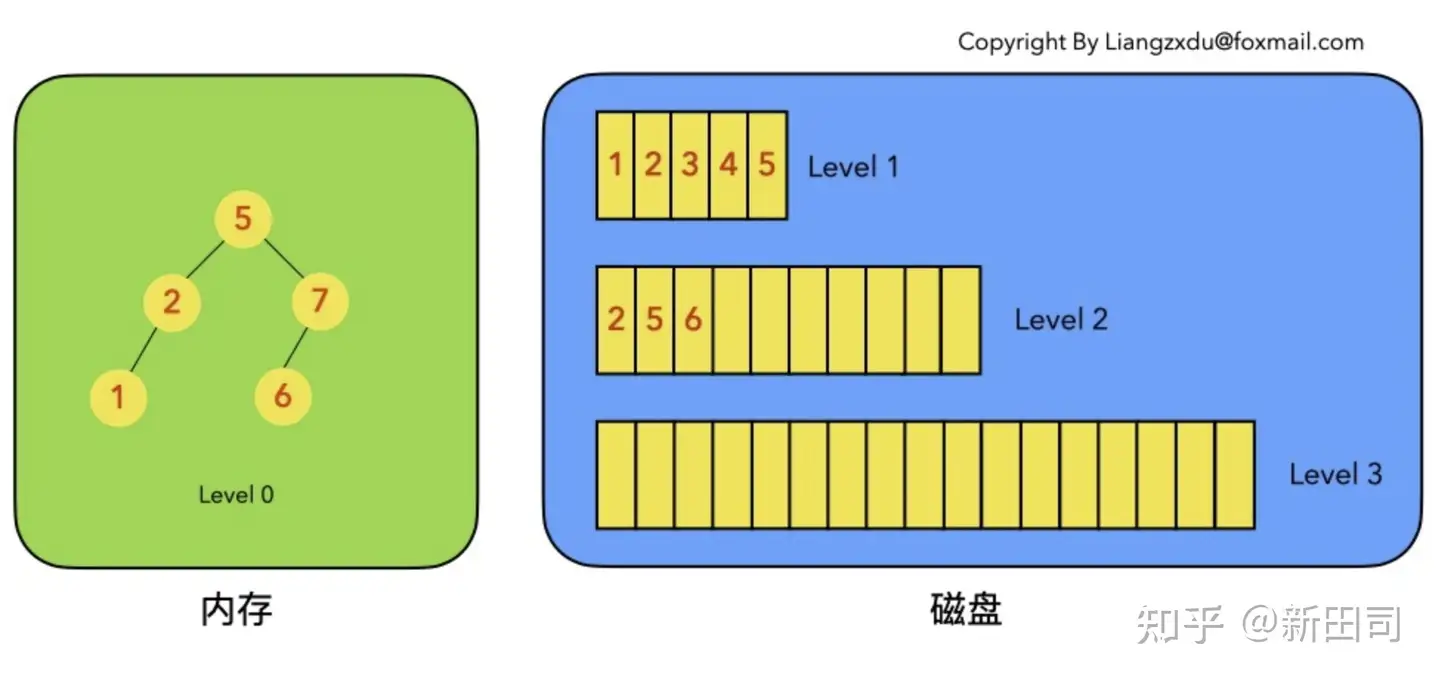
如图所示,左侧部分表示位于内存中的 level-0 结构(一个平衡的排序树),右侧表示落盘的其他 level。
注意到图中 level-0 到 level-2 中都包含 key 为 2 的数据节点,这是因为上述的性质 5 导致的。
下面开始介绍 LSM-Tree 的增删查改和归并操作:
- Insert:
LSM-Tree 的插入一般是直接写到内存中的 level-0 上,并不关心这个数据是否已经存在于磁盘上的 level(如果这个 key 已经存在于 level-0 ,此时的 insert 替换为 update 语义)
插入的时间复杂度一般来说是比较确定的,为 level-0 的树高 logn ,其中 n 为 level-0 的数据量。 - Delete
LSM-Tree 的删除一般不是直接删除数据,而是通过给对应节点打上标记来标识数据的删除。
根据场景不同,一般分为以下三种情况讨论:待删除数据在内存中、待删除数据在磁盘中,待删除数据不存在
如果待删除数据在内存中,那么用标记标识这个节点。
如果待删除数据不在内存中,说明要么处于磁盘文件中,要么根本不存在。此时我们也并不需要去磁盘中删除,直接在 level-0 中插入这个节点标识即可。
通过以上分类讨论,发现实际上删除操作都是等价于在 level-0 中写入一个标记,这个复杂度也是比较确定的,为 level-0 的树高 logn,其中 n 为 level-0 的数据量。 - Update
按照删除操作的讨论方式,我们将修改操作也分为三类情况讨论
如果待修改数据在内存中,那么直接在内存的数据结构上覆盖这个节点。
如果待修改的数据不在内存中,说明要么处于磁盘文件中,要么根本不存在。此时我们并不需要去磁盘中修改,直接在 level-0 中插入这条修改数据即可。
通过以上分类讨论,我们发现修改和删除其实有很多相似的地方,同时复杂度也相对比较容易确定,为 level-0 的树高 logn ,其中 n 为 level-0 的数据量。 - Get
LSM-Tree会按照 level-0 到 level-n 的顺序查找每一个 level ,一旦匹配到结果立即返回。这样的好处是保证了查询的结果一定是最新写入的结果,这个性质保障了前面几类写操作结果的正确性(即使多个 level 中存在不同的数据,也可以保证正确性,因为返回的数据可以看作是版本号最高的数据)。
查找的顺序一般是按照 level-0 采用的数据结构特性做一次遍历,如果不存在的话再去从低到高遍历磁盘上的其他 level 。直到匹配到结果(或者更糟糕的,遍历完所有的 level )。
可以看出,LSM-Tree虽然能提供非常强大的写吞吐,但是读的性能明显表现较差,虽然可以通过布隆/布谷鸟过滤器+建立索引来优化查询,但是代价明显是大于以 B/B+树为代表的传统存储引擎数据结构的。 - Compaction(这里以 Tiered Compaction 为例)
合并操作是 LSM-Tree 这个结构的核心。原因是因为以上一系列机制导致了整个数据结构中存在大量的冗余数据,并且作用于内存的 level-0 也不可能拥有无限的空间。
一般来说,合并操作可以分为两类情况来讨论:将 level-0 的数据从内存中刷到磁盘中,或是将磁盘中达到阈值的 level 归并到下一 level 中。
对于将内存数据刷到磁盘中的场景:
将内存中的数据结构有序排列后(例如对于平衡树,取其中序遍历的结果),顺序的写入 level1 即可,此时 level1 会新增一个 block 。这样能保证新增的 block 是有序的,同时也保证了查询和归并的高效。
对于磁盘中多个 block 的归并:
由于 block 都是有序的,此时工作类似归并多个有序链表,要注意的是,归并过程中如果遇到相同的 key ,需要保留相对更新的数据,放弃相对更旧的数据。
以上是 LSM-Tree 一般情况下的基本操作。
可以看到,LSM-Tree 的写操作基本都作用于内存上,不仅都拥有相对可靠的时间复杂度保障,且效率都很高,能提供极其优秀的写性能保障。
但是,优异的写表现的 trade-off 是相对更差的读操作,以及为了维护做出的牺牲——Compaction(相较于基于 B/B+树的传统存储引擎而言)
这些 trade-off 带来的问题包括:读放大、写放大、空间放大等,这些问题不仅会导致整个系统的吞吐能力下降,甚至写放大和空间放大这两个问题会明显的作用于硬件成本上,使我们不得不付出更多的机器预算。
对于读操作,我们可以采用布隆/布谷鸟过滤器+建立索引来优化查询。但很遗憾的是,目前针对 LSM-Tree 的研究中,并没有解决 Compaction 问题的完美答案,在单机中,这些代价可以说是不可避免的。不过自1996年 LSM-Tree 诞生以来,无论是工业界还是学术界都提供了很多 Compaction 的优化方向供我们参考。
在下一章《放弃:LSM Tree的Compaction机制探讨和分析》中,将详细分析业界较为流行的 Compaction 策略和一些相关学术研究的成果,并探讨这些成果最终可以带给我们什么。
参考:
[转帖]LSM-Tree:从入门到放弃——入门:基本概念、操作和Trade-Off分析的更多相关文章
- hive从入门到放弃(三)——DML数据操作
上一篇给大家介绍了 hive 的 DDL 数据定义语言,这篇来介绍一下 DML 数据操作语言. 没看过的可以点击跳转阅读: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--D ...
- Flink从入门到放弃(入门篇1)-Flink是什么
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Vue.js2.0从入门到放弃---入门实例
最近,vue.js越来越火.在这样的大浪潮下,我也开始进入vue的学习行列中,在网上也搜了很多教程,按着教程来做,也总会出现这样那样的问题(坑啊,由于网上那些教程都是Vue.js 1.x版本的,现在用 ...
- Flink从入门到放弃(入门篇2)-本地环境搭建&构建第一个Flink应用
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇3)-DataSetAPI
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇4) DataStreamAPI
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- 转-Vue.js2.0从入门到放弃---入门实例(一)
http://blog.csdn.net/u013182762/article/details/53021374 标签: Vue.jsVue.js 2.0Vue.js入门实例Vue.js 2.0教程 ...
- NodeJs 入门到放弃 — 入门基本介绍(一)
码文不易啊,转载请带上本文链接呀,感谢感谢 https://www.cnblogs.com/echoyya/p/14450905.html 目录 码文不易啊,转载请带上本文链接呀,感谢感谢 https ...
- JVM入门到放弃之基本概念
1. 基本概念 jvm 是可运行Java代码的假想计算机,包括一套字节码指令集.一组寄存器.一个栈.一个垃圾回收堆和一个存储方法域. jvm 是运行在操作系统之上的,屏蔽了与具体操作系统平台相关的信息 ...
- mysql从入门到放弃-入门知识介绍
数据库在互联网网站的重要性 简单地说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构来组织和存储的,我们可以通过数据库提供的多种方法来管理数据库里的数据.由于数据库不易扩展,所以,在一个互 ...
随机推荐
- 欧拉定理 & 扩展欧拉定理 笔记
欧拉函数 欧拉函数定义为:\(\varphi(n)\) 表示 \(1 \sim n\) 中所有与 \(n\) 互质的数的个数. 关于欧拉函数有下面的性质和用途: 欧拉函数是积性函数.可以通过这个性质求 ...
- shared_preferences缓存
封装 import 'dart:convert'; import 'package:shared_preferences/shared_preferences.dart'; class JSpUtil ...
- 24、去除右上方的debug图标
class MyApp extends StatelessWidget { const MyApp({super.key}); @override Widget build(BuildContext ...
- 超详细API插件使用教程,教你开发AI垃圾分类机器人
本文分享自华为云社区[案例教学]华为云API对话机器人的魅力-体验AI垃圾分类机器人,作者:华为云PaaS服务小智. 体验用Huawei Cloud API开发AI垃圾分类机器人,并学习AI自然语言的 ...
- 云图说 | 华为云GPU共享型AI容器,让你用得起,用得好,用的放心
摘要:容器以其独特的技术优势,已经成为业界主流的AI计算框架(如Tensorflow.Caffe)的核心引擎,为了进一步解决企业在AI计算性能与成本上面临的问题,华为云推出了AI容器产品. 容器以其独 ...
- 规模化敏捷框架何从入手?这篇文章把SAFe讲透了!
摘要:敏捷软件开发理念已渐渐被业界普遍接受,越来越多的公司和团队不得不面对一个新的问题,就是规模化敏捷的引入和实现.目前市场上规模化框架主要有SAFe,Less,Scrum of Scrums, Sp ...
- DTSE Tech Talk 第18期丨统计信息大揭秘,数仓SQL执行优化之密钥
摘要:华为云EI DTSE技术布道师王跃,针对统计信息对于查询优化器的重要性,GaussDB(DWS)最新版本的analyze当前能力,与开发者和伙伴朋友们展开交流互动,帮助开发者快速上手使用统计信息 ...
- 【“互联网+”大赛华为云赛道】CloudIDE命题攻略:明确业务场景,快速开发插件
摘要:基于华为云CloudIDE和插件开发框架自行设计并开发插件. IDE是每个开发人员必备的生产工具,一款好的IDE + 插件的组合,除了帮助开发者把编写代码.组织项目.编译运行放在一个环境中外,还 ...
- 当物联网遇上云原生:K8s向边缘计算渗透中
摘要:K8s正在向边缘计算渗透,它为边缘侧的应用部署提供了便利性,在一定程度上转变了边缘应用与硬件之间的关系,将两者的耦合度降低. 本文分享自华为云社区<云原生在物联网中的应用[拜托了,物联网! ...
- 5步带你掌握工作流Activiti框架的使用
摘要:本文通过一个工作流Activiti框架的具体使用示例,具体详尽的介绍了工作流Activiti框架的使用方式. 本文分享自华为云社区<一个使用示例,五个操作步骤!从此轻松掌握项目中工作流的开 ...