Nebula Graph 源码解读系列 | Vol.06 MATCH 中变长 Pattern 的实现

目录
- 问题分析
- 定长 Pattern
- 变长 Pattern 与变长 Pattern 的组合
- 执行计划
- 拓展一步
- 拓展多步
- 保存路径
- 变长拼接
- 总结
MATCH 作为 openCypher 语言的核心,通过简洁的 Pattern 形式,可以让用户方便地表达图库中的关联关系。变长模式又是 Pattern 中用来描述路径的一种常用形式,对变长模式的支持是 Nebula 兼容 openCypher MATCH 功能的第一步。
由之前的系列文章可以了解到,Nebula 的执行计划是由许多的物理算子组成,每个算子都负责执行特有的计算逻辑,在 MATCH 的实现中也会涉及前述文章中的这些算子,比如 GetNeighbors、GetVertices、Join、Project、Filter、Loop 等等。因为 Nebula 的执行计划不同于关系数据库中的树状结构,在执行的流程上其实是一个有环的图。如何把 MATCH 中的变长 Pattern 变成 Nebula 的物理计划是 Planner 要解决的问题的重点。以下便简单介绍一下在 Nebula 中解决变长 Pattern 问题的思路。
问题分析
定长 Pattern
在使用 MATCH 语句时,定长 Pattern 也是比较常用的查询形式。如果把定长 Pattern 理解成向外拓展 X 步的变长 Pattern,认为其是后者的一种特例,那么定长和变长 Pattern 的实现便可以统一起来,如下所示:
// 定长 Pattern MATCH (v)-[e]-(v2)
// 变长 Pattern MATCH (v)-[e*1..1]-(v2)
上述示例中的区别就是变量 e 的类型,定长时 e 表示的是一条边,而变长时 e 表示的是长度为 1 的边列表。
变长 Pattern 与变长 Pattern 的组合
在 openCypher 的 MATCH 语法里,Pattern 可以灵活的组合以表达复杂路径。如下所示,变长 Pattern 再接变长 Pattern:
MATCH (v)-[e*1..3]-(v2)-[ee*2..4]-(v3)
上述的过程可以是个不断延伸的过程,通过变长定长模式的不同排列,可以组合出非常复杂的路径。所以我们必须找到一种生成 plan 的模式才能方便的递归迭代整个过程。其中需要考虑如下的因素:
- 后面变长 Pattern 的路径依赖前面所有变长路径;
- 变长 Pattern 后面的所有的符号(或者变量)表示的结果是“变化”的;
- 每一步在往外拓展之前需要对起点进行去重;
我们可以注意到,如果可以生成 Pattern 中 ()-[:like*m..n]- 的部分的执行计划,那么后面继续进行组合迭代就变得有迹可循,如下所示:
()-[:like*m..n]- ()-[:like*k..l]- ()
\____________/ \____________/ \_/
Pattern1 Pattern2 Pattern3
执行计划
下面便分析模式中 ()-[:like*m..n]- 的部分,查看其如何转换成 Nebula 的物理执行计划的。上面模式描述的意思是向外拓展 m 到 n 步,在 Nebula 中向外拓展一步是通过 GetNeighbors 算子完成的。如果要向外拓展多步,需要不断在上一步拓展的基础上再调用 GetNeighbors 算子,将每次获取的点边数据首尾连接就会拼接成一个路径(path)。虽然用户最后需要的只是 m 到 n 步的路径,但是在执行的过程中依然需要从第 1 步开始拓展直到第 n 步。并且每步拓展过程中的路径结果都需要保存下来,以便输出或者给下一步使用。最后只要拿出长度在区间 m 到 n 步之间的路径即可。
拓展一步
先来看看走一步的计划是什么样子,因为 Nebula 数据存储的方式为起点和出边放置在一起,所以获取起点和出边的数据是不需要跨 partition 的。但是边的终点数据一般是跨 partition 的,需要单独通过 GetVertices 接口来获取点的属性。除此之外,在向外拓展之前,最好要把拓展的起点数据进行去重,避免 storage 重复扫描。所以走一步的执行计划如下图所示:
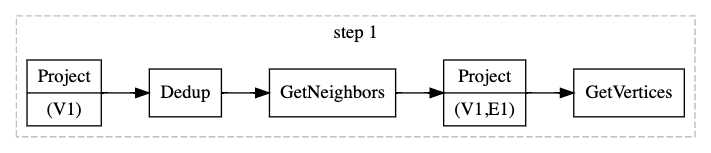
拓展多步
拓展多步的过程其实就是将上述的过程重复,但是我们会注意到 GetNeighbors 可以获取起点的属性,所以在拓展下一步时,是可以省掉一步 GetVertices 操作。拓展两步的执行计划就变为:

保存路径
由于最后可能需要返回每一步拓展的路径,所以在上述拓展过程中,还需要将所有的路径进行保存。连接两步之间的路径可以通过 join 算子完成。同时因为模式 ()-[e:like*m..n]- 的返回结果中 e 表示的是一列数据(边的 list),所以上面每步拓展路径需要通过 union 的方式进行结果集的合并。执行计划进一步演变为:

变长拼接
由上面的过程便可以生成模式 ()-[e:like*m..n]- 的物理计划,当多个类似模式做拼接时,就是再把上述的过程进行迭代。不过在进行模式迭代之前,还需要对上面计划得到的结果进行过滤,因为我们期望是得到 m 到 n 步的结果,上面的数据集中包含了从第 1 步到第 n 步的所有结果,通过对路径的长度做个简单的筛选即可。变长模式拼接之后的计划变为:

通过上述一步步的分解,我们终于得到了最初 MATCH 语句期望的执行计划,可以看到在把一个复杂模式转换成底层的拓展接口时还是颇费功夫。当然上面的计划可以做些优化,比如把多步拓展的过程使用 Loop 算子进行封装,复用一步拓展的 sub-plan,这里不再详细展开。感兴趣的用户可以参考 nebula 源码实现。
总结
上述过程演示了一个变长 Pattern 的 MATCH 语句的执行计划生成过程,相信大家这时会有这样一个疑惑,为什么基本的一些路径拓展在 Nebula 中会生成这么复杂的执行计划?对比 Neo4j 的实现,几个算子即可完成相同的工作,在这里会变成繁琐的 DAG 呢?
这个问题的本质原因是 Nebula 的算子更接近底层的接口,缺少一些更上层的图操作语义上的抽象。算子力度太细,就会导致上层的优化等实现需要考虑太多的细节。后面会对执行算子进一步的梳理,来逐步的完善 MATCH 功能和提升性能。
《开源分布式图数据库Nebula Graph完全指南》,又名:Nebula 小书,里面详细记录了图数据库以及图数据库 Nebula Graph 的知识点以及具体的用法,阅读传送门:https://docs.nebula-graph.com.cn/site/pdf/NebulaGraph-book.pdf
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
Nebula Graph 源码解读系列 | Vol.06 MATCH 中变长 Pattern 的实现的更多相关文章
- 新手阅读 Nebula Graph 源码的姿势
摘要:在本文中,我们将通过数据流快速学习 Nebula Graph,以用户在客户端输入一条 nGQL 语句 SHOW SPACES 为例,使用 GDB 追踪语句输入时 Nebula Graph 是怎么 ...
- Alamofire源码解读系列(二)之错误处理(AFError)
本篇主要讲解Alamofire中错误的处理机制 前言 在开发中,往往最容易被忽略的内容就是对错误的处理.有经验的开发者,能够对自己写的每行代码负责,而且非常清楚自己写的代码在什么时候会出现异常,这样就 ...
- Alamofire源码解读系列(四)之参数编码(ParameterEncoding)
本篇讲解参数编码的内容 前言 我们在开发中发的每一个请求都是通过URLRequest来进行封装的,可以通过一个URL生成URLRequest.那么如果我有一个参数字典,这个参数字典又是如何从客户端传递 ...
- Alamofire源码解读系列(三)之通知处理(Notification)
本篇讲解swift中通知的用法 前言 通知作为传递事件和数据的载体,在使用中是不受限制的.由于忘记移除某个通知的监听,会造成很多潜在的问题,这些问题在测试中是很难被发现的.但这不是我们这篇文章探讨的主 ...
- Alamofire源码解读系列(五)之结果封装(Result)
本篇讲解Result的封装 前言 有时候,我们会根据现实中的事物来对程序中的某个业务关系进行抽象,这句话很难理解.在Alamofire中,使用Response来描述请求后的结果.我们都知道Alamof ...
- Alamofire源码解读系列(六)之Task代理(TaskDelegate)
本篇介绍Task代理(TaskDelegate.swift) 前言 我相信可能有80%的同学使用AFNetworking或者Alamofire处理网络事件,并且这两个框架都提供了丰富的功能,我也相信很 ...
- Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager)
Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager) 本篇主要讲解iOS开发中的网络监控 前言 在开发中,有时候我们需要获取这些信息: 手机是否联网 ...
- Alamofire源码解读系列(八)之安全策略(ServerTrustPolicy)
本篇主要讲解Alamofire中安全验证代码 前言 作为开发人员,理解HTTPS的原理和应用算是一项基本技能.HTTPS目前来说是非常安全的,但仍然有大量的公司还在使用HTTP.其实HTTPS也并不是 ...
- Alamofire源码解读系列(九)之响应封装(Response)
本篇主要带来Alamofire中Response的解读 前言 在每篇文章的前言部分,我都会把我认为的本篇最重要的内容提前讲一下.我更想同大家分享这些顶级框架在设计和编码层次究竟有哪些过人的地方?当然, ...
- Alamofire源码解读系列(十)之序列化(ResponseSerialization)
本篇主要讲解Alamofire中如何把服务器返回的数据序列化 前言 和前边的文章不同, 在这一篇中,我想从程序的设计层次上解读ResponseSerialization这个文件.更直观的去探讨该功能是 ...
随机推荐
- pytest.ini配置文件
pytest.ini文件是pytest框架独有的配置文件,主要作用就是在运行pytest.main时可指定运行顺序,也 就相当于在Terminal输入pytest+参数+路径效果一致,下面介绍几种简单 ...
- 最新 Hugging Face 强化学习课程(中文版)来啦!
人工智能中最引人入胜的话题莫过于深度强化学习 (Deep Reinforcement Learning) 了,我们在 2022 年 12 月 5 日开启了<深度强化学习课程 v2.0>的课 ...
- pycharm的docstring多了一行type
注释中多了一行:type 设置为Epytext PyCharm 2020.3.5 (Community Edition) def test(param1,param2,param3): "& ...
- MeshFilter mesh vs sharedMesh
MeshFilter有两个属性mesh和sharedMesh,从官方文档和实际使用来说说这两者的区别 MeshFilter文档 Unity的MeshFilter文档:https://docs.unit ...
- 飞桨paddle遇到bug调试修正【迁移工具、版本兼容性】
PaddlePaddlle强化学习及PARL框架{飞桨} [一]-环境配置+python入门教学 [二]-Parl基础命令 [三]-Notebook.&pdb.ipdb 调试 [四]-强化学习 ...
- “I/O多路复用”和“异步I/O”的前世今生
曾经的VIP服务在网络的初期,网民很少,服务器完全无压力,那时的技术也没有现在先进,通常用一个线程来全程跟踪处理一个请求.因为这样最简单.其实代码实现大家都知道,就是服务器上有个ServerSocke ...
- vue-cli3创建多页面应用
首先用vue-cli3创建工程,我的全局安装了vue-cli2,又不想卸载掉:所以新建了一个文件夹安装vue-cli3:然后在该文件夹下创建工程: 同时安装vue-cli2和vue-cli3参考:ht ...
- ElasticSearch7.3学习(十八)----多索引搜索
1.multi-index 多索引搜索 多索引搜索就是一次性搜索多个index下的数据 /_search:所有索引下的所有数据都搜索出来 /index1/_search:指定一个index,搜索其下所 ...
- 2.3 实验:用linxerUnpack进行通用脱壳--《恶意代码分析实战》
Lab01-03.exe 实验内容: 1.将文件上传到http://www.VirusTotal.com 进行分析并查看报告.文件匹配到了已有的反病毒软件特征吗? 2.是否有这个文件被 ...
- MySQL优化技术系列-谓词下推(pushdown)
谓词下推 将外层查询块的 WHERE 子句中的谓词移入所包含的较低层查询块(例如视图),从而能够提早进行数据过滤以及有可能更好地利用索引. 这在分区数据库环境中甚至更为重要,其原因在于,提早进行过滤有 ...