在kubernetes集群中使用虚拟节点创建1万Pod-支持在线教育业务
使用虚拟节点提升k8s集群容量和弹性
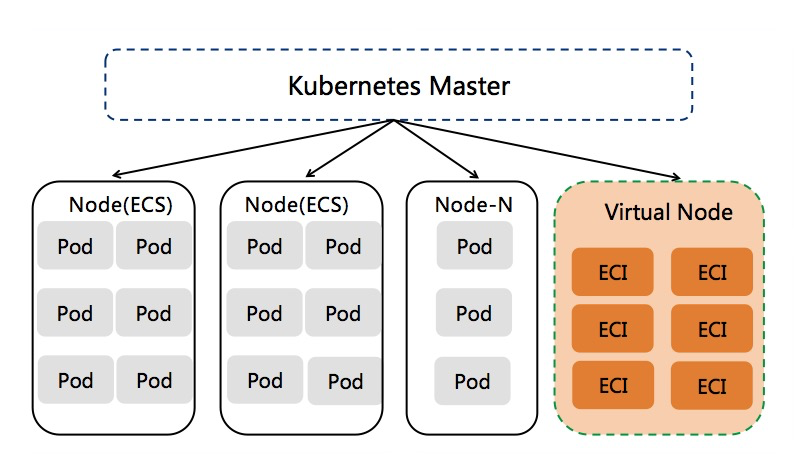
在kubernetes集群中添加虚拟节点的方式已被非常多的客户普遍使用,基于虚拟节点可以极大提升集群的Pod容量和弹性,灵活动态的按需创建ECI Pod,免去集群容量规划的麻烦。目前虚拟节点已广泛应用在如下场景。
- 在线业务的波峰波谷弹性需求:如在线教育、电商等行业有着明显的波峰波谷计算特征,使用虚拟节点可以显著减少固定资源池的维护,降低计算成本。
- 提升集群Pod容量:当传统的flannel网络模式集群因vpc路由表条目或者vswitch网络规划限制导致集群无法添加更多节点时,使用虚拟节点可以规避上述问题,简单而快速的提升集群Pod容量。
- 数据计算:使用虚拟节点承载Spark、Presto等计算场景,有效降低计算成本。
- CI/CD和其他Job类型任务
下面我们介绍如何使用虚拟节点快速创建1万个pod,这些eci pod按需计费,不会占用固定节点资源池的容量。
相比较而言,AWS EKS在一个集群中最多只能创建1000个 Fargate Pod。基于虚拟节点的方式可以轻松创建过万个ECI Pod。
创建多个虚拟节点
请先参考ACK产品文档部署虚拟节点:https://help.aliyun.com/document_detail/118970.html
因为使用多个虚拟虚拟节点往往用于部署大量ECI Pod,我们建议谨慎确认vpc/vswitch/安全组的配置,确保有足够的vswitch ip资源(虚拟节点支持配置多个vswitch解决ip容量问题),使用企业级安全组可以突破普通安全组的2000个实例限制。
通常而言,如果单个k8s集群内eci pod数量小于3000,我们推荐部署单个虚拟节点。如果希望在虚拟节点上部署更多的pod,我们建议在k8s集群中部署多个虚拟节点来对其进行水平扩展,多个虚拟节点的部署形态可以缓解单个虚拟节点的压力,支撑更大的eci pod容量。这样3个虚拟节点可以支撑9000个eci pod,10个虚拟节点可以支撑到30000个eci pod。
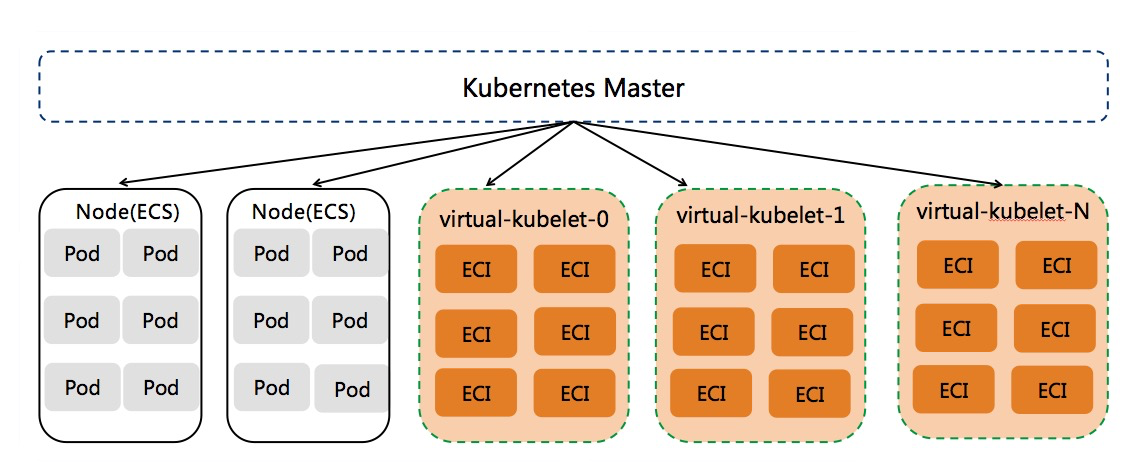
为了更简单的进行虚拟节点水平扩展,我们使用statefulset的方式部署vk controller,每个vk controller管理一个vk节点,statefulset的默认Pod副本数量是1。当需要更多的虚拟节点时,只需要修改statefulset的replicas即可。
# kubectl -n kube-system scale statefulset virtual-node-eci --replicas=4
statefulset.apps/virtual-node-eci scaled
# kubectl get no
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.1 Ready <none> 63d v1.12.6-aliyun.1
cn-hangzhou.192.168.1.2 Ready <none> 63d v1.12.6-aliyun.1
virtual-node-eci-0 Ready agent 1m v1.11.2-aliyun-1.0.207
virtual-node-eci-1 Ready agent 1m v1.11.2-aliyun-1.0.207
virtual-node-eci-2 Ready agent 1m v1.11.2-aliyun-1.0.207
virtual-node-eci-3 Ready agent 1m v1.11.2-aliyun-1.0.207
# kubectl -n kube-system get statefulset virtual-node-eci
NAME READY AGE
virtual-node-eci 4/4 1m
# kubectl -n kube-system get pod|grep virtual-node-eci
virtual-node-eci-0 1/1 Running 0 1m
virtual-node-eci-1 1/1 Running 0 1m
virtual-node-eci-2 1/1 Running 0 1m
virtual-node-eci-3 1/1 Running 0 1m
当我们在vk namespace中创建多个nginx pod时(将vk ns加上指定label,强制让ns中的pod调度到虚拟节点上),可以发现pod被调度到了多个vk节点上。
# kubectl create ns vk
# kubectl label namespace vk virtual-node-affinity-injection=enabled
# kubectl -n vk run nginx --image nginx:alpine --replicas=10
deployment.extensions/nginx scaled
# kubectl -n vk get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-546c47b569-blp88 1/1 Running 0 69s 192.168.1.26 virtual-node-eci-1 <none> <none>
nginx-546c47b569-c4qbw 1/1 Running 0 69s 192.168.1.76 virtual-node-eci-0 <none> <none>
nginx-546c47b569-dfr2v 1/1 Running 0 69s 192.168.1.27 virtual-node-eci-2 <none> <none>
nginx-546c47b569-jfzxl 1/1 Running 0 69s 192.168.1.68 virtual-node-eci-1 <none> <none>
nginx-546c47b569-mpmsv 1/1 Running 0 69s 192.168.1.66 virtual-node-eci-1 <none> <none>
nginx-546c47b569-p4qlz 1/1 Running 0 69s 192.168.1.67 virtual-node-eci-3 <none> <none>
nginx-546c47b569-x4vrn 1/1 Running 0 69s 192.168.1.65 virtual-node-eci-2 <none> <none>
nginx-546c47b569-xmxx9 1/1 Running 0 69s 192.168.1.30 virtual-node-eci-0 <none> <none>
nginx-546c47b569-xznd8 1/1 Running 0 69s 192.168.1.77 virtual-node-eci-3 <none> <none>
nginx-546c47b569-zk9zc 1/1 Running 0 69s 192.168.1.75 virtual-node-eci-2 <none> <none>
运行1万个ECI Pod
在上述步骤中我们已经创建了4个虚拟节点,能够支撑12000个ECI Pod,我们只需要将workload指定调度到虚拟节点即可。这里我们需要关注kube-proxy的可扩展性。
- 虚拟节点创建的ECI Pod默认支持访问集群中的ClusterIP Service,这样每个ECI Pod都需要watch apiserver保持一个连接以监听svc/endpoints变化。当大量pod同时Running时,apiserver和slb将维持Pod数量的并发连接,所以需要确保slb规格能否支撑期望的并发连接数。
- 如果ECI Pod无需访问ClusterIP Service,则可以将virtual-node-eci statefulset的ECI_KUBE_PROXY环境变量值设置为"false",这样就不会有大量slb并发连接的存在,也会减少apiserver的压力。
- 我么也可以选择将ECI Pod访问的ClusterIP Service暴露成内网slb类型,然后通过privatezone的方式让ECI Pod不必基于kube-proxy也能否访问到集群中的Service服务。
缩减vk虚拟节点数量
因为vk上的eci pod是按需创建,当没有eci pod时vk虚拟节点不会占用实际的资源,所以一般情况下我们不需要减少vk节点数。但用户如果确实希望减少vk节点数时,我们建议按照如下步骤操作。
假设当前集群中有4个虚拟节点,分别为virtual-node-eci-0/.../virtual-node-eci-3。我们希望缩减到1个虚拟节点,那么我们需要删除virtual-node-eci-1/../virtual-node-eci-3这3个节点。
- 先优雅下线vk节点,驱逐上面的pod到其他节点上,同时也禁止更多pod调度到待删除的vk节点上。
# kubectl drain virtual-node-eci-1 virtual-node-eci-2 virtual-node-eci-3
# kubectl get no
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.1 Ready <none> 66d v1.12.6-aliyun.1
cn-hangzhou.192.168.1.2 Ready <none> 66d v1.12.6-aliyun.1
virtual-node-eci-0 Ready agent 3d6h v1.11.2-aliyun-1.0.207
virtual-node-eci-1 Ready,SchedulingDisabled agent 3d6h v1.11.2-aliyun-1.0.207
virtual-node-eci-2 Ready,SchedulingDisabled agent 3d6h v1.11.2-aliyun-1.0.207
virtual-node-eci-3 Ready,SchedulingDisabled agent 66m v1.11.2-aliyun-1.0.207
之所以需要先优雅下线vk节点的原因是vk节点上的eci pod是被vk controller管理,如果vk节点上还存在eci pod时删除vk controller,那样将导致eci pod被残留,vk controller也无法继续管理那些pod。
- 待vk节点下线后,修改virtual-node-eci statefulset的副本数量,使其缩减到我们期望的vk节点数量。
# kubectl -n kube-system scale statefulset virtual-node-eci --replicas=1
statefulset.apps/virtual-node-eci scaled
# kubectl -n kube-system get pod|grep virtual-node-eci
virtual-node-eci-0 1/1 Running 0 3d6h
等待一段时间,我们会发现那些vk节点变成NotReady状态。
# kubectl get no
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.1 Ready <none> 66d v1.12.6-aliyun.1
cn-hangzhou.192.168.1.2 Ready <none> 66d v1.12.6-aliyun.1
virtual-node-eci-0 Ready agent 3d6h v1.11.2-aliyun-1.0.207
virtual-node-eci-1 NotReady,SchedulingDisabled agent 3d6h v1.11.2-aliyun-1.0.207
virtual-node-eci-2 NotReady,SchedulingDisabled agent 3d6h v1.11.2-aliyun-1.0.207
virtual-node-eci-3 NotReady,SchedulingDisabled agent 70m v1.11.2-aliyun-1.0.207
- 手动删除NotReady状态的虚拟节点
# kubelet delete no virtual-node-eci-1 virtual-node-eci-2 virtual-node-eci-3
node "virtual-node-eci-1" deleted
node "virtual-node-eci-2" deleted
node "virtual-node-eci-3" deleted
# kubectl get no
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.1 Ready <none> 66d v1.12.6-aliyun.1
cn-hangzhou.192.168.1.2 Ready <none> 66d v1.12.6-aliyun.1
virtual-node-eci-0 Ready agent 3d6h v1.11.2-aliyun-1.0.207
查看更多:https://yqh.aliyun.com/detail/6738?utm_content=g_1000106525
上云就看云栖号:更多云资讯,上云案例,最佳实践,产品入门,访问:https://yqh.aliyun.com/
在kubernetes集群中使用虚拟节点创建1万Pod-支持在线教育业务的更多相关文章
- Kubernetes集群部署之五node节点部署
Node节点是Kubernetes集群中的工作负载节点.每个node都会被master分配一些工作负载,每个node节点都运行以下关键服务进程.Kubelet :负责pod对应的容器的创建.启停等任务 ...
- ingress-nginx 的使用 =》 部署在 Kubernetes 集群中的应用暴露给外部的用户使用
文章转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247488189&idx=1&sn=8175f067 ...
- 初试 Kubernetes 集群中使用 Traefik 反向代理
初试 Kubernetes 集群中使用 Traefik 反向代理 2017年11月17日 09:47:20 哎_小羊_168 阅读数:12308 版权声明:本文为博主原创文章,未经博主允许不得转 ...
- 【转载】浅析从外部访问 Kubernetes 集群中应用的几种方式
一般情况下,Kubernetes 的 Cluster Network 是属于私有网络,只能在 Cluster Network 内部才能访问部署的应用.那么如何才能将 Kubernetes 集群中的应用 ...
- 在Kubernetes集群中使用calico做网络驱动的配置方法
参考calico官网:http://docs.projectcalico.org/v2.0/getting-started/kubernetes/installation/hosted/kubeadm ...
- 在kubernetes集群中创建redis主从多实例
分类 > 正文 在kubernetes集群中创建redis主从多实例 redis-slave镜像制作 redis-master镜像制作 创建kube的配置文件yaml 继续使用上次实验环境 ht ...
- Kubernetes集群中Jmeter对公司演示的压力测试
6分钟阅读 背景 压力测试是评估Web应用程序性能的有效方法.此外,越来越多的Web应用程序被分解为几个微服务,每个微服务的性能可能会有所不同,因为有些是计算密集型的,而有些是IO密集型的. 基于微服 ...
- (转)在Kubernetes集群中使用JMeter对Company示例进行压力测试
背景 压力测试是评估应用性能的一种有效手段.此外,越来越多的应用被拆分为多个微服务而每个微服务的性能不一,有的微服务是计算密集型,有的是IO密集型. 因此,压力测试在基于微服务架构的网络应用中扮演着越 ...
- 解决项目迁移至Kubernetes集群中的代理问题
解决项目迁移至Kubernetes集群中的代理问题 随着Kubernetes技术的日益成熟,越来越多的企业选择用Kubernetes集群来管理项目.新项目还好,可以选择合适的集群规模从零开始构建项目: ...
- 如何在 Kubernetes 集群中玩转 Fluid + JuiceFS
作者简介: 吕冬冬,云知声超算平台架构师, 负责大规模分布式机器学习平台架构设计与功能研发,负责深度学习算法应用的优化与 AI 模型加速.研究领域包括高性能计算.分布式文件存储.分布式缓存等. 朱唯唯 ...
随机推荐
- 【开源库推荐】#2 AndroidUtilCode Android常用工具类大全(附API使用说明)
Blankj/AndroidUtilCode: Android developers should collect the following utils(updating). Download Gr ...
- 使用zxing来生成二维码
使用zxing来生成二维码 二维码已经成为了现代生活中不可或缺的一部分,无论是商业还是个人使用,二维码都有着广泛的应用.而在二维码的生成过程中,zxing是一款非常优秀的开源库,它提供了一系列的API ...
- 新浪Linux 运维工程师面试真题
新浪Linux 运维工程师面试真题 首先我们来看下新浪 Linux 运维工程师招聘岗位要求: [岗位定义]运维工程师 [岗位薪资]10K-20K [基本要求]经验 1-3 年 / 本科及以上 / 全职 ...
- 引领汽车营销新趋势,3DCAT实时云渲染助力汽车三维可视化
当前,汽车产业发展正从电动化的上半场,向智能化的下半场迈进.除了车机技术体验的智能化之外,观车体验的智能化也不容忽视. 这是因为,随着数字化.智能化.个性化的趋势,消费者对汽车的需求和期待也越来越高, ...
- 专访惠众科技|元宇宙应用如何借助3DCAT实时云渲染实现流畅大并发呈现?
当前互联网流量红利已经逐渐消失,营销同质化愈发严重.在这样的背景下,催生了以元宇宙为焦点的虚拟产业经济.元宇宙在各行各业中以不同形式快速萌生.成长,呈现出多元化的应用场景.尤其是众多品牌,将元宇宙视为 ...
- ElasticSearch - 基础概念和映射
前言 写这篇东西,是因为官方文档看着太痛苦,于是乎想用大白话来聊聊 ElasticSearc (下面都简称ES).所以下文对于 ES 一些概念的表述可能会与官方有出入,所以需要准确的表述和详细定义的, ...
- 三维模型OBJ格式轻量化的跨平台兼容性问题分析
三维模型OBJ格式轻量化的跨平台兼容性问题分析 三维模型的OBJ格式轻量化在跨平台兼容性方面具有重要意义,可以确保模型在不同平台和设备上的正确加载和渲染.本文将分析OBJ格式轻量化的跨平台兼容性技术, ...
- 记录--用three.js渲染真实的下雨效果
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 建模 首先我们需要一些贴图素材 贴图素材一般可以在3dtextures网站上找到,这里我找了2份,包含了墙的法线贴图和潮湿地面的法线.透明 ...
- GO 协程【VS】C# 多线程【Go-C# Round 1】
〇.前言 最近接触到 Go 语言相关的内容,由于之前都是用的 C# 语言,然后就萌生了对这两种语言进行多方面比较. 本文将在 Go 的优势项目协程,来与 C# 的多线程操作进行比较,看下差距有多大. ...
- KingbaseES V8R6 集群运维系列 -- 命令行部署repmgr管理集群+switchover测试
本次部署未使用securecmd/kbha工具,无需普通用户到root用户的互信. 一.环境准备 1.创建OS用户 建立系统数据库安装用户组及用户,在所有的节点执行. root用户登陆服务器,创建用户 ...