python之正则表达式和re模块一
摘要:正则表达式 re模块 一、正则表达式:只和字符串打交道,是一种用来约束字符串的规则
1、应用场景:
1,判断某一个字符串是否符合规则:注册页-判断手机号、身份证号 是否合法
注册某个账号的时候,需要验证你填写的手机号码是否正确、
邮箱地址是否正确、身份证号是否正确等 2,将符合规则的内容从一个庞大的字符串体系当中提取出来:爬虫、日志分析
访问一个网页,这个网页的源代码对于pyhon来说是一串字符串,
使用正则表达式可以从一大段的文字(字符串)当中提取你想要的数据 2、字符组
字符组 :是元字符中的一个 使用方式:[字符组]
在字符组中所有的字符都可以匹配任意一个字符位置上能出现的内容
如果在字符串中有任意一个字符是字符组中的内容,那么就是匹配上的项
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字、字母、标点等等。
正则 |
待匹配字符 |
匹配结果 |
说明 |
[0123456789] |
8 | 8 |
在一个字符组里枚举合法的所有字符, 字符组里的任意一个字符和"待匹配字符"相同都视为可以匹配 |
[0123456789] |
a | False | 由于字符组中没有"a"字符,所以不能匹配 |
| [0-9] | 7 | 7 | 也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
| [a-z] | s | s | 同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
| [A-Z] | B | B | [A-Z]就表示所有的大写字母 |
| [0-9a-fA-F] | e | e |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
注意:如果使用[x-y]这种形式,它默认是按照ASCII的编码去查找的,只能由ascii编码小的值指向一个大的值
比如:在ASCII中,A:65 Z:90 a:97 z:122
[A-Z]:正确,值可以是A到Z大写的26个字母
[a-z]:正确,值可以是a到z小写的26个字母
[a-Z]:不正确,因为a的ASCII编码是97,Z的编码是90,不能由大的值指向小的值
[A-z]:正确,由ASCII的65到122都可以,但是有些特殊字符也在这个范围,这个表示的并不是纯字母,例如 \ 编码是92,在这个正则表达式中也是正确的 3、元字符(\w:word \d:digit \s:space \n:next \t:tab)
元字符 匹配内容 . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线
\d 匹配数字
\s 匹配任意的空白符 \W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符 \n 匹配一个换行符
\t 匹配一个制表符(Tab) \b 匹配一个边界(其前后必须是不同类型的字符,
可以组成单词的字符为一种类型,
不可组成单词的字符(包括字符串的开始和结束)为另一种类型) ^ 匹配字符串的开始
$ 匹配字符串的结尾 a|b 匹配字符a或字符b () 匹配括号内的表达式,一个组表示一个整体 [...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符 例子:
正则表达式: \babc\b
待测试字符串:abcsdsadas abc asdsadasdabcasdsabc
结果:abc(前后有空格的那个abc,但是结果只是abc没有带空格,即只是3个字符) 正则表达式: \babc\b
待测试字符串:abcsdsadas@abc@asdsadasdabcasdsabc
结果:abc(前后有@的那个abc,但是结果只是abc没有带@,即只是3个字符) 正则表达式: \babc\b
待测试字符串:abcsdsadas abc@asdsadasdabcasdsabc
结果:abc(前有空格后有@的那个abc,但是结果只是abc没有带空格和@,即只是3个字符) 正则表达式: \sabc\s
待测试字符串:abcsdsadas abc asdsadasdabcasdsabc
结果: abc (前后有空格的那个abc,结果是 abc 带有空格,即5个字符) 正则表达式: ^abc
待测试字符串:abcsdsadas abc asdsadasdabcasdsabc
结果: abc (以abc开头:最开始的三个字符) 正则表达式: abc$
待测试字符串:abcsdsadas abc asdsadasdabcasdsabc
结果: abc (以abc结尾:最后的三个字符) 4、量词:解决想要匹配的字符串的长度问题
量词 用法说明
? 重复零次或一次
+ 重复一次或更多次
* 重复零次或更多次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
5、例题:
5-1、. ^ $
正则 |
待匹配字符 |
匹配结果 |
说明 |
张. |
张三张四张五 |
张三 |
匹配所有"张."的字符 |
^张. |
张三张四张五 |
张三 |
只从开头匹配"张." |
张.$ |
张三张四张五 |
张五 |
只匹配结尾的"张.$" |
5-2、? + * { }
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| 张.? | 张三和张无忌和张四无敌 |
张三 张无 张四 |
?表示重复零次或一次,即只匹配"张"后面一个任意字符 |
| 张.+ | 张三和张无忌和张四无敌 | 张三和张无忌和张四无敌 | +表示重复一次或多次,即匹配"张"后面1个或多个任意字符 |
| 张.* | 张三和张无忌和张四无敌 | 张三和张无忌和张四无敌 | *表示重复零次或多次,即匹配"张"后面0或多个任意字符 |
| 张.{1,2} | 张三和张无忌和张四无敌 |
张三和 张无忌 张四无 |
{1,2}匹配1到2次任意字符 |
注意:为什么 ? 表示零次或一次,上面的例子是匹配一次,+ 表示重复一次或多次,上面匹配的是多次等等呢?
这是因为,默认的情况下这样的匹配都是贪婪匹配,也就是尽可能多的匹配。
想要执行尽可能少的匹配,在后面加?号就可以使其变成惰性匹配。
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| 张.*?或者张.?? | 张三和张无忌和张四无敌 |
张 张 张 |
惰性匹配 |
贪婪匹配 : 正则会尽量多的帮我们匹配
默认贪婪-回溯算法
非贪婪匹配 :在量词的范围内尽量少的匹配这个元字符
量词?表示非贪婪-惰性匹配
.*?x 表示匹配任意长度任意字符遇到一个x就立即停止
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
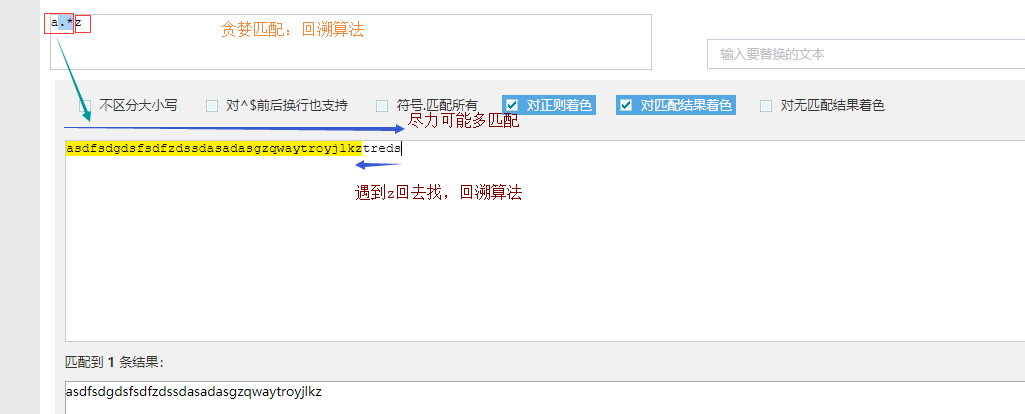
| a.*z | asdfsdgdsfsdfzdssdasadasgzqwaytroyjlkztreds | asdfsdgdsfsdfzdssdasadasgzqwaytroyjlkz | 默认贪婪匹配,匹配尽可能多的值 |
| a.*?z | asdfsdgdsfsdfzdssdasadasgzqwaytroyjlkztreds |
asdfsdgdsfsdfz asadasgz aytroyjlkz |
非贪婪匹配,匹配尽可能少的值 |
5-3、分组 () 与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,
如果是15位则全部都是数字组成,首位不能为0;
如果是18位,首位不能为0,前17位全部是数字,末位可能是数字或x
方法一:或(把长的放前面,谁在前面先匹配谁)
^[1-9]\d{16}[\dx]$|^[1-9]\d{14}$:
[1-9] \d{16} [\dx] | [1-9] \d{14}
数字1到9中取一个 任意数字取16次 从任意数字和字母x中取一个 或 数字1到9中取一个 任意数字取14次 方法二:
^[1-9]\d{14}(\d{2}[\dx])?$:
[1-9] \d{14} (\d{2}[\dx])?
数字1到9中取一个 任意数字取14次 (任意数字取2次,从任意数字和字母x中取一个)整体取零次或一次 5-4、匹配网址
值匹配百度、qq的网址
正则:www\.(baidu|qq)\.com
待匹配字符:qwwww.baidu.comasdaswww.qq.comsaxwq
结果:
www.baidu.com
www.qq.com 6、转义符\
在正则表达式中,有很多有特殊意义的元字符,比如\n和\s等,如果要在正则表达式中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。
而在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。
所以如果要匹配得到"\n",待匹配的字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。
正则 |
待匹配字符 |
匹配结果 |
说明 |
\n |
\n |
无结果 |
因为正则的\n有它的特殊意思,它代表要匹配的是换行符 |
\\n |
\n |
\n |
转义后\\n表示要匹配的内容就是\n(此时无特殊意义) |
"\\\\n" |
'\\n' |
\n |
在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
r'\\n' |
r'\n' |
\n |
在字符串之前加r,让整个字符串没有转义 |
二、re模块
1、findall:
参数:正则表达式 待匹配的字符串
返回值:是一个列表-所有匹配到的项 import re
ret = re.findall('\d+','as12XCV4SA6A89')
print(ret) # ['12', '4', '6', '89'] 2、search:(常在计算器中使用)
参数:正则表达式 待匹配的字符串
返回值:返回一个SRE_Match对象,通过group去取值,且只包含第一个匹配到的值 import re
ret = re.search('\d+','as12XCV4SA6A89')
print(ret) # 对象<_sre.SRE_Match object; span=(2, 4), match='12'>
print(ret.group()) # # 一般search如果找不到相匹配的值,会报错,所以用search之前应该进行判断
不判断:
import re
ret = re.search('\d+','ASXCFG')
print(ret) # None
print(ret.group()) # 报错 判断:
import re
ret = re.search('\d+','ASXCFG')
print(ret) # None
if ret:
print(ret.group()) # 无结果,但是不会报错 3、findall与search中关于元组的问题
3-1、findall 有一个特点,会优先显示分组中的内容
import re
ret = re.findall('www\.(baidu|qq)\.com','www.baidu.com')
print(ret) # ['baidu'] ret = re.findall('(www)\.(baidu|qq)\.(com)','www.baidu.com')
print(ret) # [('www', 'baidu', 'com')] 若想取消分组优先,则在元组开头加上 ?:
ret = re.findall('www\.(?:baidu|qq)\.com','www.baidu.com')
print(ret) # ['www.baidu.com'] 3-2、search:有分组的情况下,用索引取值,0代表整个匹配到的值,1代表第一个元组的内容...
ret = re.search('www\.(baidu|qq)\.(com)', 'www.baidu.com')
print(ret) # <_sre.SRE_Match object; span=(0, 13), match='www.baidu.com'>
print(ret.group()) # www.baidu.com
print(ret.group(0)) # www.baidu.com
print(ret.group(1)) # baidu
print(ret.group(2)) # com 3-3、常用的提取整数的正则表达式
# finall正则表达式中被 | 或分开的两个条件,若一边有元组,则只会显示元组的内容,另外一边满足条件但没有用元组括起来的值会以空字符串的形式存在列表中
# 提取字符串中的整数:\d+\.\d 小数 (\d+) 整数 ,且小数必须写在或 | 前面,如果先写整数,那么小数就会被拆分成两个整数
# 如 40.35 会被拆分成40 35
ret = re.findall(r"\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) # ['1', '2', '60', '', '5', '4', '3']
ret.remove('')
print(ret) # ['1', '2', '60', '5', '4', '3']
python之正则表达式和re模块一的更多相关文章
- 【转】Python之正则表达式(re模块)
[转]Python之正则表达式(re模块) 本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 参考文档 提示: ...
- Python之正则表达式(re模块)
本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 正则表达式(Regluar Expressions)又称规则 ...
- Python与正则表达式[0] -> re 模块的正则表达式匹配
正则表达式 / Regular Expression 目录 正则表达式模式 re 模块简介 使用正则表达式进行匹配 正则表达式RE(Regular Expression, Regexp, Regex) ...
- python与正则表达式:re模块详解
re模块是python中处理正在表达式的一个模块 正则表达式知识储备:http://www.cnblogs.com/huamingao/p/6031411.html 1. match(pattern, ...
- python之正则表达式及RE模块
正则表达式(匹配字符串)web界面正则匹配工具:http://tool.chinaz.com/regex/ 元字符 1 . 匹配除换行符之外的任意字符 2 \w 匹配数字字母下划线 3 \d 匹配数字 ...
- Python之正则表达式与常用模块(Day19)
一.正则表达式:匹配字符串的一种规则 正则表达式的在线测试工具: http://tool.chinaz.com/regex/ 字符组: 正则 待匹配字符 匹配结果 说明 [0123456789] 8 ...
- python之正则表达式(re模块)用法总结
用一句表示正则表达式,就是 字符串的模糊 匹配
- Python的正则表达式re模块
Python的正则表达式(re模块) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Python使用re模块提供了正则表达式处理的能力.如果对正则表达式忘记的一干二净的话,可以花费 ...
- python的正则表达式 re
python的正则表达式 re 本模块提供了和Perl里的正则表达式类似的功能,不关是正则表达式本身还是被搜索的字符串,都可以是Unicode字符,这点不用担心,python会处理地和Ascii字符一 ...
随机推荐
- 使用vue-cli 初始化 vue 项目
1. 安装nodejs 2. 安装 vue-cli npm install -g vue-cli 安装前可以通过设置代理为淘宝仓库地址,以加快下载速度. npm config set registry ...
- Dynamics 365创建用户提示:您正在尝试使用已由其他用户使用的域登录来创建用户。如何解决。
摘要: 本人微信公众号:微软动态CRM专家罗勇 ,回复287或者20181128可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me ...
- 关于ArcMap中打开ArcToolbox导致闪退的解决办法
最近好久不用ArcGis的小编要用到ArcMap去发送一个GP服务,发现按照套路打开ArcMap点击ArcToolbox时,发生了ArcMap的闪退现象,几经周折终于解决了问题. 希望也遇到这类问题的 ...
- IBGP默认的TTL值为255
结论: 1.IBGP默认的TTL值为255 组网图: 抓包内容: 1.在AR1和AR2之间抓包,只显示BGP包,显示内容如下:
- 红米手机4A怎么样刷入开发版获得ROOT权限
小米的手机或平板不同手机型号一般情况官方都提供两个不同系统,可分为稳定版和开发版,稳定版没有提供root权限管理,开发版中就支持了root权限,在很多工作的时候我们需要使用的一些功能强大的app,都需 ...
- 缓存ABC
缓存ABC Intro 缓存是一种比较常见的用来将提高系统性能的方式.从线程缓存.进程缓存.到内存缓存再到分布式缓存再到CDN,都是属于缓存的范畴. 缓存的本质是空间换时间以提高读的效率,牺牲一些内存 ...
- 中文乱码之《字符编码:ASCII,Unicode 和 UTF-8》
参考文献:字符编码笔记:ASCII,Unicode 和 UTF-8 一.ASCII 码 我们知道,计算机内部,所有信息最终都是一个二进制值.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就 ...
- centos7中/tmp文件保存天数
不要在/tmp目录下保存文件,该目录会定期清理文件 /tmp默认保存10天 /var/tmp默认保存30天 配置文件:/usr/lib/tmpfiles.d/tmp.conf 默认配置文件:# Thi ...
- Swift NSAttributedString的使用
NSMutableAttributedString let testAttributes = [NSAttributedStringKey.foregroundColor: UIColor.blue, ...
- SQLServer之触发器简介
触发器定义 触发器是数据库服务器中发生事件时自动执行的一种特殊存储过程.SQLServer允许为任何特定语句创建多个触发器.它的执行不是由程序调用,也不是手工启动,而是由事件来触发,当对数据库进行操作 ...