ASP.NET Core使用Jaeger实现分布式追踪
前言
最近我们公司的部分.NET Core的项目接入了Jaeger,也算是稍微完善了一下.NET团队的技术栈。
至于为什么选择Jaeger而不是Skywalking,这个问题我只能回答,大佬们说了算。
前段时间也在CSharpCorner写过一篇类似的介绍
Exploring Distributed Tracing Using ASP.NET Core And Jaeger。
下面回到正题,我们先看一下Jaeger的简介
Jaeger的简单介绍

Jaeger是Uber开源的一个分布式追踪的工具,主要为基于微服务的分布式系统提供监测和故障诊断。包含了下面的内容
- Distributed context propagation
- Distributed transaction monitoring
- Root cause analysis
- Service dependency analysis
- Performance / latency optimization
下面就通过一个简单的例子来体验一下。
示例
在这个示例的话,我们只用了jaegertracing/all-in-one这个docker的镜像来搭建,因为是本地的开发测试环境,不需要搭建额外的存储,这个感觉还是比较贴心的。
我们会用到两个主要的nuget包
Jaeger这个是官方的clientOpenTracing.Contrib.NetCore.Unofficial这个是对.NET Core探针的处理,从opentracing-contrib/csharp-netcore这个项目移植过来的(这个项目并不活跃,只能自己做扩展)
然后我们会建两个API的项目,一个是AService,一个是BService。
其中BService会提供一个接口,从缓存中读数据,如果读不到就通过EF Core去从sqlite中读,然后写入缓存,最后再返回结果。
AService 会通过HttpClient去调用BService的接口,从而会形成调用链。
开始之前,我们先把docker-compose.yml配置一下
version: '3.4'
services:
aservice:
image: ${DOCKER_REGISTRY-}aservice
build:
context: .
dockerfile: AService/Dockerfile
ports:
- "9898:80"
depends_on:
- jagerservice
- bservice
networks:
backend:
bservice:
image: ${DOCKER_REGISTRY-}bservice
build:
context: .
dockerfile: BService/Dockerfile
ports:
- "9899:80"
depends_on:
- jagerservice
networks:
backend:
jagerservice:
image: jaegertracing/all-in-one:latest
environment:
- COLLECTOR_ZIPKIN_HTTP_PORT=9411
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
- "16686:16686"
- "14268:14268"
- "9411:9411"
networks:
backend:
networks:
backend:
driver: bridge
然后就在两个项目的Startup加入下面的一些配置,主要是和Jaeger相关的。
public void ConfigureServices(IServiceCollection services)
{
// others ....
// Adds opentracing
services.AddOpenTracing();
// Adds the Jaeger Tracer.
services.AddSingleton<ITracer>(serviceProvider =>
{
string serviceName = serviceProvider.GetRequiredService<IHostingEnvironment>().ApplicationName;
var loggerFactory = serviceProvider.GetRequiredService<ILoggerFactory>();
var sampler = new ConstSampler(sample: true);
var reporter = new RemoteReporter.Builder()
.WithLoggerFactory(loggerFactory)
.WithSender(new UdpSender("jagerservice", 6831, 0))
.Build();
var tracer = new Tracer.Builder(serviceName)
.WithLoggerFactory(loggerFactory)
.WithSampler(sampler)
.WithReporter(reporter)
.Build();
GlobalTracer.Register(tracer);
return tracer;
});
}
这里需要注意的是我们要根据情况来选择sampler,演示这里用了最简单的ConstSampler。
回到BService这个项目,我们添加SQLite和EasyCaching的相关支持。
public void ConfigureServices(IServiceCollection services)
{
// Adds an InMemory-Sqlite DB to show EFCore traces.
services
.AddEntityFrameworkSqlite()
.AddDbContext<BDbContext>(options =>
{
var connectionStringBuilder = new SqliteConnectionStringBuilder
{
DataSource = ":memory:",
Mode = SqliteOpenMode.Memory,
Cache = SqliteCacheMode.Shared
};
var connection = new SqliteConnection(connectionStringBuilder.ConnectionString);
connection.Open();
connection.EnableExtensions(true);
options.UseSqlite(connection);
});
// Add EasyCaching Inmemory provider.
services.AddEasyCaching(options =>
{
options.UseInMemory("m1");
});
}
然后控制器上面就比较简单了。
// GET api/values
[HttpGet]
public async Task<IActionResult> GetAsync()
{
var provider = _providerFactory.GetCachingProvider("m1");
var obj = await provider.GetAsync("mykey", async () => await _dbContext.DemoObjs.ToListAsync(), TimeSpan.FromSeconds(30));
return Ok(obj);
}
AService就是通过HttpClient去调用上面的这个接口即可。
// GET api/values
[HttpGet]
public async Task<string> GetAsync()
{
var res = await GetDemoAsync();
return res;
}
private async Task<string> GetDemoAsync()
{
var client = _clientFactory.CreateClient();
var request = new HttpRequestMessage
{
Method = HttpMethod.Get,
RequestUri = new Uri($"http://bservice/api/values")
};
var response = await client.SendAsync(request);
response.EnsureSuccessStatusCode();
var body = await response.Content.ReadAsStringAsync();
return body;
}
到这里的话,代码这块是ok了,下面就来看看效果。
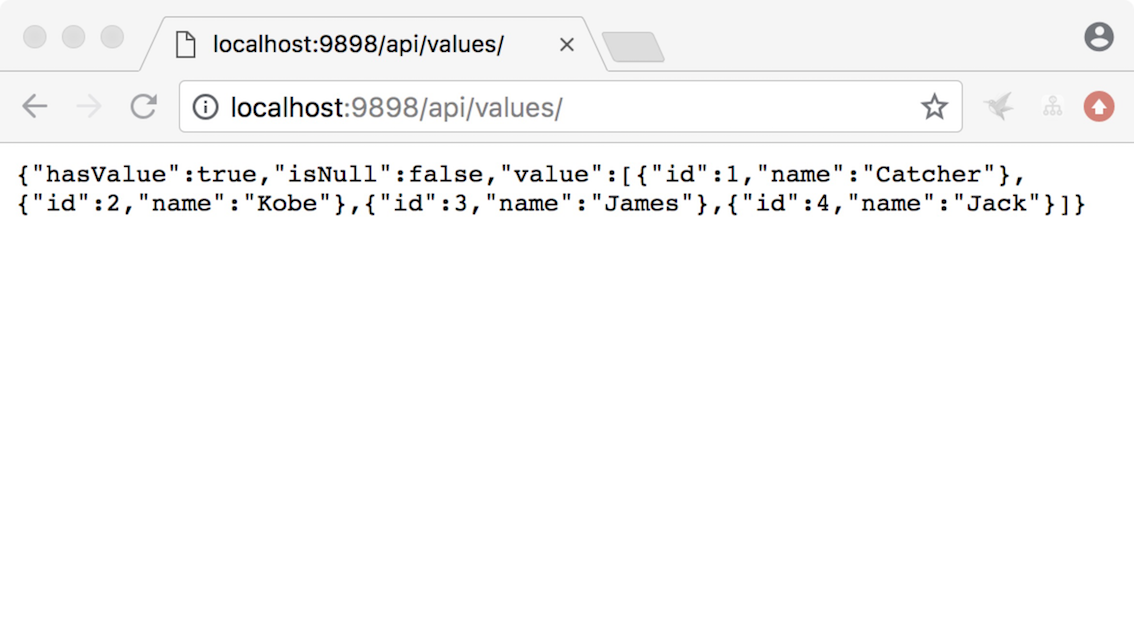
先通过http://localhost:9898/api/values/访问几次AService
大概能得到一个这样的结果
然后去Jaeger的界面上我们可以看到,两个服务已经注册上来了。
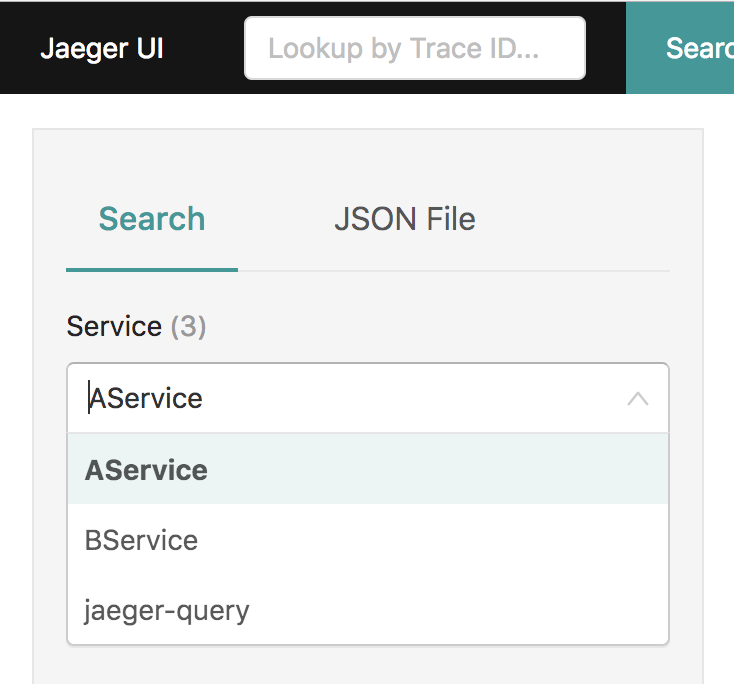
选A,B其中一个去搜索,就可以看到下面的结果
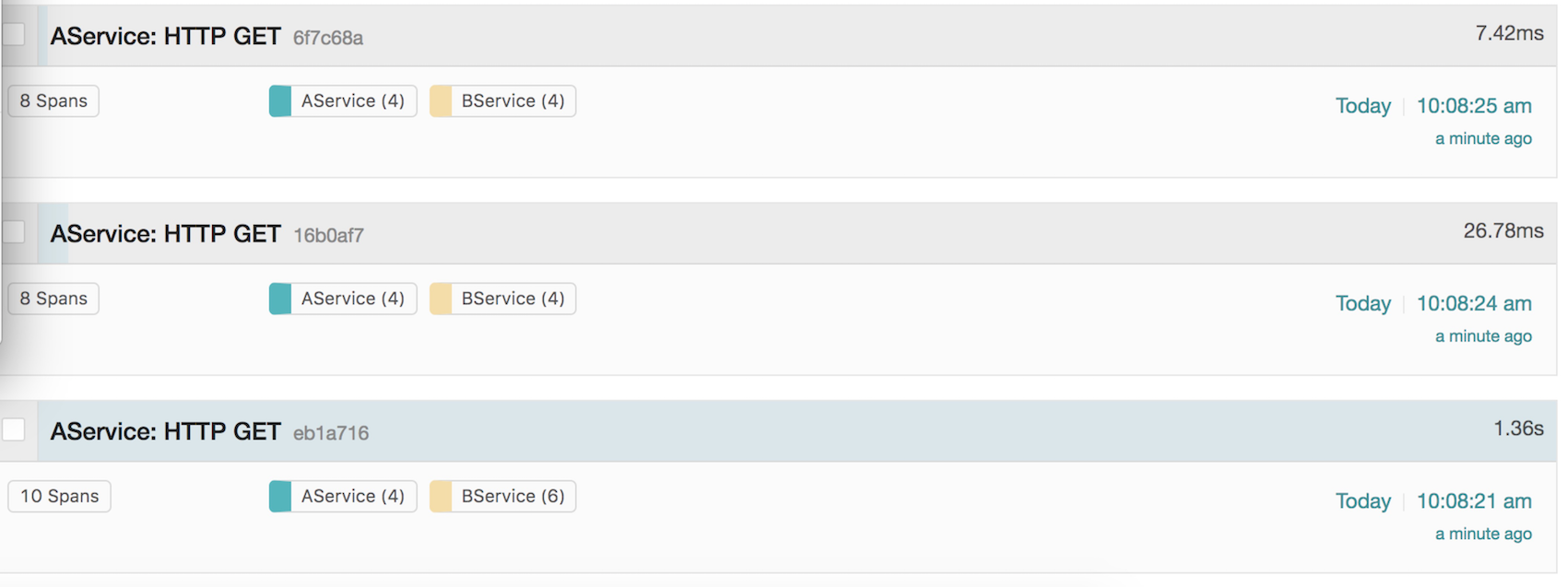
这个就最外层,能看到这些请求一些宏观的信息。
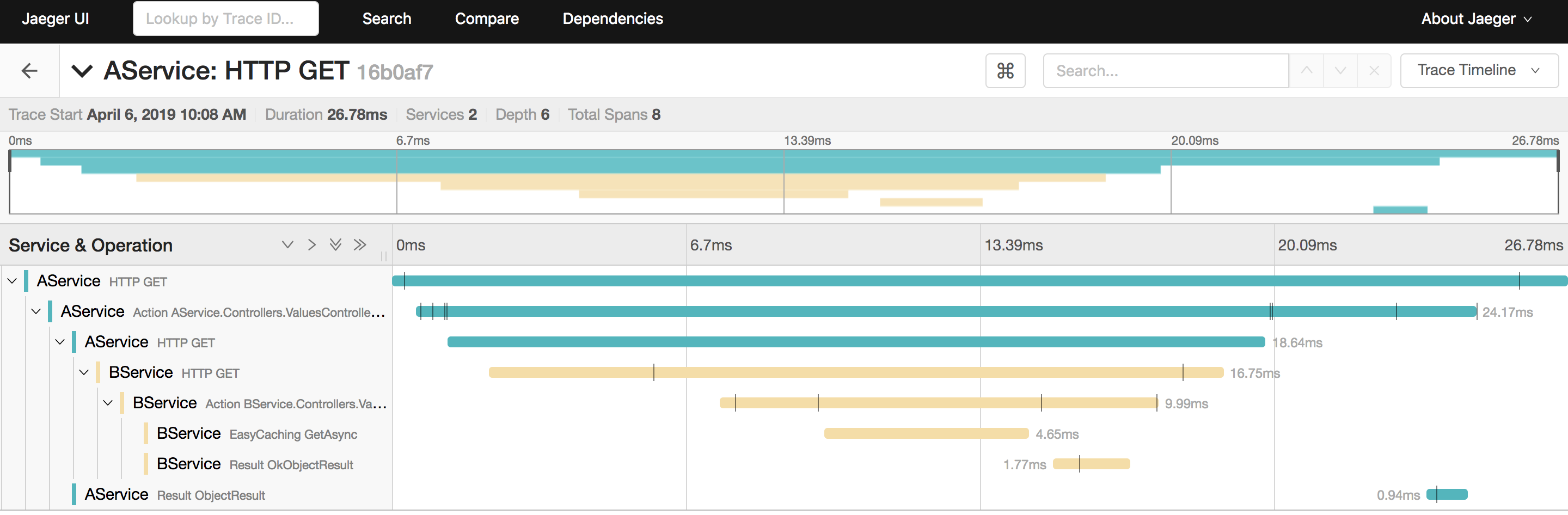
我们选界面上最后一个,也就是第一个请求,进去看看细节

从上面这个图大概也能看出来,做了一些什么操作,请求来到AService,它就发起了HTTP请求到BService,BService则是先通过EasyCaching去取缓存,显然缓存中没数据,它就去读数据库了。
和另外的请求对比一下,可以发现是少了查数据库这一步操作的。这也是为什么上面的是10个span,而下面的才8个。
再来看看两个请求的对比图。
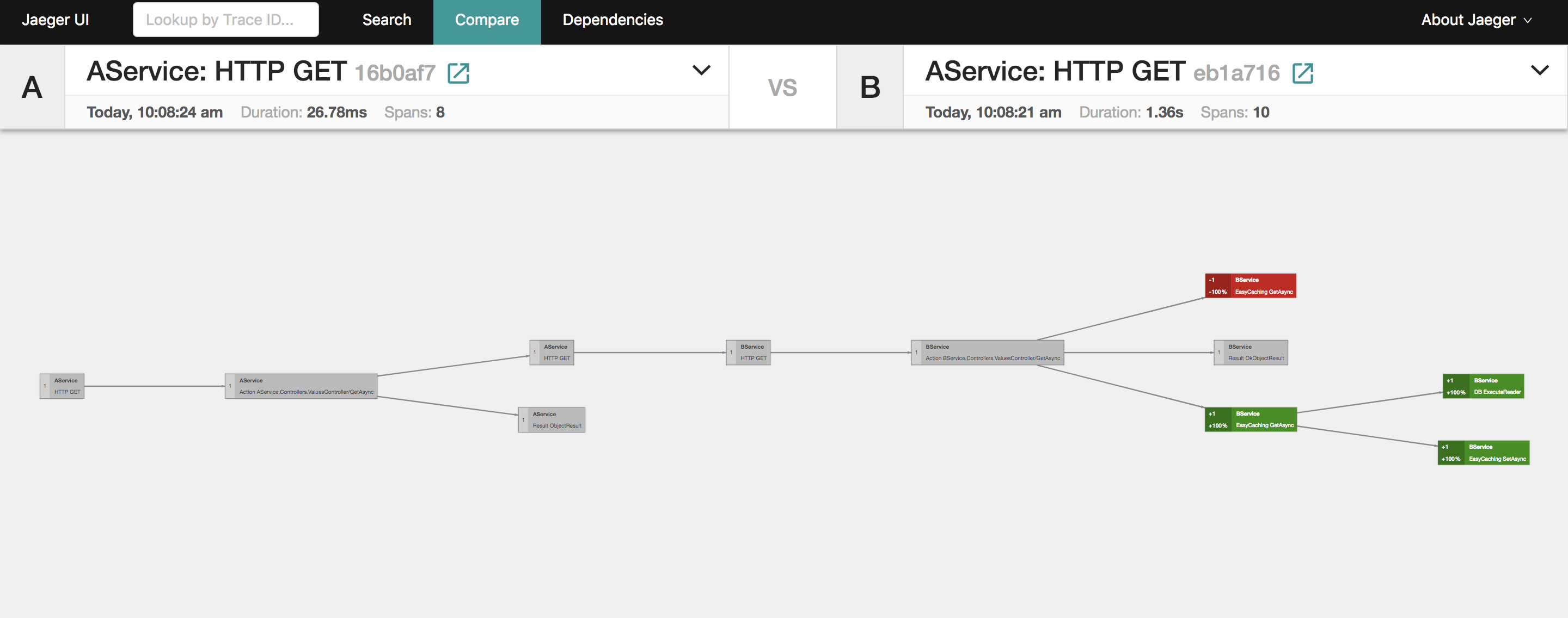
上图中那些红色和绿色的块就是两个请求的差异点了。
回去看看其他细节,可以发现类似下面的内容

有很多日志相关的东西,这些东西在这里可能没有太多实际的作用,我们可以通过调整日志的级别来不让它写入到Jaeger中。
或者是通过下面的方法来过滤
services.AddOpenTracing(new System.Collections.Generic.Dictionary<string,LogLevel>
{
{"AService", LogLevel.Information}
});
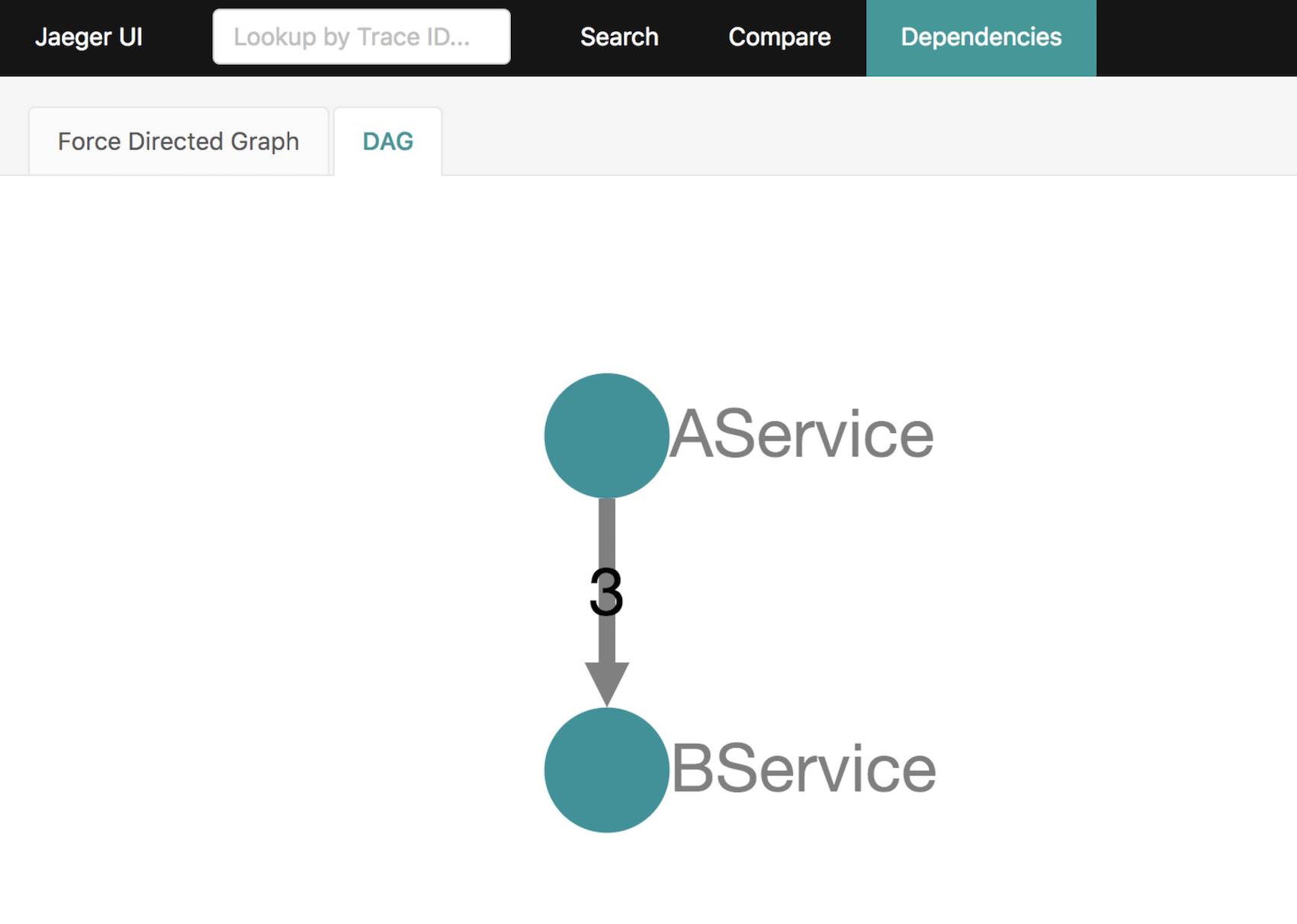
最后就是依赖图了。
写在最后
虽说Jaeger用起来挺简单的,但是也是有点美中不足的,不过这个锅不应该是Jaeger来背的,主要还是很多我们常用的库没有直接的支持Diagnostic,所以能监控到的东西还是略少。
不过在github发现了ClrProfiler.Trace这个项目,可以通过clrprofiler来解决上面的问题。
最后是本文的示例代码
ASP.NET Core使用Jaeger实现分布式追踪的更多相关文章
- ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IDistributedCache、StackExchangeRedis
ASP.NET Core 使用 Redis 实现分布式缓存:Docker.IDistributedCache.StackExchangeRedis 前提:一台 Linux 服务器.已安装 Docker ...
- ASP.NET Core 使用 JWT 搭建分布式无状态身份验证系统
为什么使用 Jwt 最近,移动开发的劲头越来越足,学校搞的各种比赛都需要用手机 APP 来撑场面,所以,作为写后端的,很有必要改进一下以往的基于 Session 的身份认证方式了,理由如下: 移动端经 ...
- 用asp.net core结合fastdfs打造分布式文件存储系统
最近被安排开发文件存储微服务,要求是能够通过配置来无缝切换我们公司内部研发的文件存储系统,FastDFS,MongDb GridFS,阿里云OSS,腾讯云OSS等.根据任务紧急度暂时先完成了通过配置来 ...
- asp.net core mcroservices 架构之 分布式日志(一)
一 简介 无论是微服务还是其他任何分布式系统,都需要一个统一处理日志的系统,这个系统 必须有收集,索引,分析查询的功能.asp .net core自己的日志是同步方式的,正如文档所言: 所以必须自己提 ...
- ASP.Net Core 使用Redis实现分布式缓存
本篇我们记录的内容是怎么在Core中使用Redis 和 SQL Server 实现分布式缓存. 一.文章概念描述 分布式缓存描述: 分布式缓存重点是在分布式上,相信大家接触过的分布式有很多中,像分 ...
- asp.net core microservices 架构之分布式自动计算(三)-kafka日志同步至elasticsearch和kibana展示
一 kafka consumer准备 前面的章节进行了分布式job的自动计算的概念讲解以及实践.上次分布式日志说过日志写进kafka,是需要进行处理,以便合理的进行展示,分布式日志的量和我们对日志的重 ...
- asp.net core microservices 架构之 分布式自动计算(一)
一:简介 自动计算都是常驻内存的,没有人机交互.我们经常用到的就是console job和sql job了.sqljob有自己的宿主,与数据库产品有很关联,暂时不提.console job使 ...
- asp.net core microservices 架构之 分布式自动计算(二)
一 简介 上一篇介绍了zookeeper如何进行分布式协调,这次主要讲解quartz使用zookeeper进行分布式计算,因为上一篇只是讲解原理,而这次实际使用, ...
- asp.net core mcroservices 架构之 分布式日志(三):集成kafka
一 kafka介绍 kafka是基于zookeeper的一个分布式流平台,既然是流,那么大家都能猜到它的存储结构基本上就是线性的了.硬盘大家都知道读写非常的慢,那是因为在随机情况下,线性下,硬盘的读写 ...
随机推荐
- 类型后面加问号 int?
类型后面加问号 int? 单问号---用于给变量设初值的时候,给变量(int类型)赋值为null,而不是0! 双问号---用于判断并赋值,先判断当前变量是否为null,如果是就可以赋一个新值,否则跳过 ...
- java课程之团队开发冲刺阶段1.6
一.总结昨天进度 1.依照视频学习了sqlite,但是由于视频的不完整性导致并不知道代码的实际效果怎么样. 二.遇到的问题 1.依据上一条,在date目录下date文件夹中,的确发现了数据库的文件,但 ...
- 关于分页器border重叠问题
.paging li { cursor: pointer; display: inline-block; float: left; box-sizing: border-box; margin-lef ...
- LoadRunner(一)——性能测试基础及性能指标概述
参考学习感谢:<精通软件性能测试与LoadRunner实战> 一.典型的性能测试场景 某个产品要发布了,需要对全市的用户做集中培训.通常在进行培训的时候,老师讲解完成一个业务以后,被培训用 ...
- Golang Go Go Go part3:数据类型及操作
五.Go 基本类型 1.基本类型种类 布尔值: bool 长度 1字节 取值范围 true, false注意事项:不可用数字代表 true 或 false 整型: int/uint 根据运行平台可能为 ...
- HBuilder git使用-环境配置
HBuilder中使用的是Egit插件,但提供的相关资料太少,这是目前遇到的一些问题的总结 1. 安装好egit插件后,本机需要安装Git windows的安装程序,并配置好相关的环境变量(理论上是自 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- FFmpeg命令行工具学习(一):查看媒体文件头信息工具ffprobe
一.简述 ffprobe是ffmpeg命令行工具中相对简单的,此命令是用来查看媒体文件格式的工具. 二.命令格式 在命令行中输入如下格式的命令: ffprobe [文件名] 三.使用ffprobe查看 ...
- [Swift]LeetCode47. 全排列 II | Permutations II
Given a collection of numbers that might contain duplicates, return all possible unique permutations ...
- [Swift]LeetCode1029. 两地调度 | Two City Scheduling
There are 2N people a company is planning to interview. The cost of flying the i-th person to city A ...