python2编码问题
前言:python3解决了编码的问题,但python2还存在很多编码问题,用P2写爬虫爬了网页,解析时常有不同字符混着编码,导致解码问题成为爬虫程序员的噩梦。。。
但咱们要用robot framework,本身这个支持python3,但ride不支持,为了用那个图形界面,我们还是得回去用跑还是得回去用P2,导致我们后面会遇到很多编码问题。正面面对!
如图:不同的编码环境,字符的长度存在差异,cmd下 “中国”长度为4,pycharm下“中国”长度为6,为何如此???
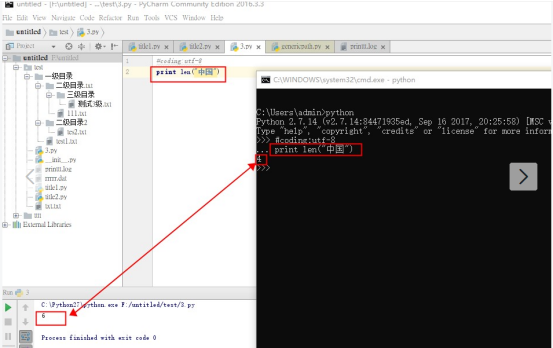
一:编码的种类
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
- Unicode 就跟英语是全球统一语言一样
二:Unicode
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系,
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
Unicode 起到了2个作用:
1、直接支持全球所有语言,每个国家都可以不用再使用自己之前的旧编码了,用unicode就可以了。(就跟英语是全球统一语言一样)
2、unicode包含了跟全球所有国家编码的映射关系。
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。。
三:使用Unicode
1、你可以用如下两种方式定义一个unicode:
s1 = u"人生苦短"
s2 = unicode("人生苦短", "utf-8")
2、编码的转换
中国的windows,默认编码依然是gbk,而不是utf-8
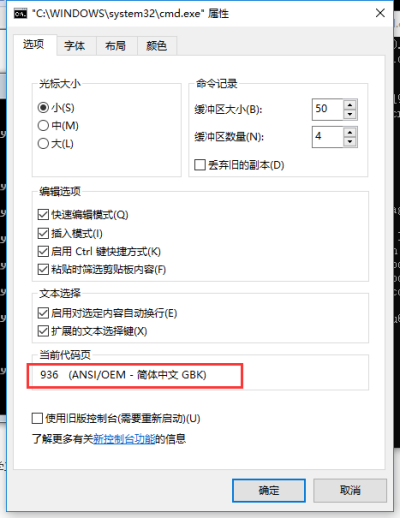
实例:
Pycharm
Windows cmd

s是个字符串,它本身存储的就是字节码。那么这个字节码是什么格式的?
如果这段代码是在解释器上输入的,那么这个s的格式就是解释器的编码格式,对于windows的cmd而言,就是gbk。
如果将段代码是保存后才执行的,比如存储为utf-8,那么在解释器载入这段程序的时候,就会将s初始化为utf-8编码。
转换规则
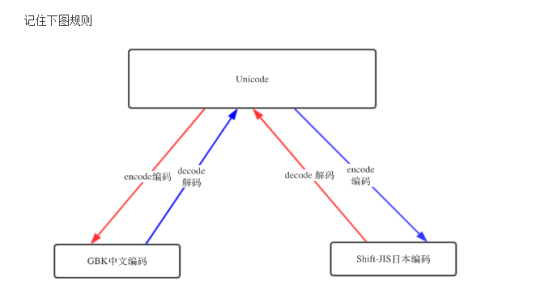
四:Python bytes类型
Python 2 将 strings 处理为原生的 bytes 类型

虽说打印的是中国,但直接调用变量s,看到的却是一个个的16进制表示的二进制字节,我们怎么称呼这样的数据呢?直接叫二进制么?也可以, 但相比于010101,这个数据串在表示形式上又把2进制转成了16进制来表示,这是为什么呢? 哈,为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型, 它把8个二进制一组称为一个byte,用16进制来表示。
python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其实就是一回事,除此之外呢, python2里还有个单独的类型unicode , 把字符串解码后,就会变成unicode。
五:Robot Framework 字符码转换
使用关键字 Evaluate
示例:
unicode 码通过编码码转换为gbk
${utf8} set variable u'\\u4e2d\\u6587'
${utf8_2} evaluate ${utf8}.encode("gbk")
Unicode 通过 evaluate后显示中文
${utf8} set variable u'\\u4e2d\\u6587'
${uft8cn} evaluate ${utf8}
gbk码通过解码转换为unicode
${gbk} set variable \\xd6\\xd0\\xce\\xc4
${gbkcn} evaluate '${gbk}'.decode('gbk')
utf-8解码
${a} set variable 中文
${utf8_1} evaluate '${a}'.decode('utf-8')
若使用gbk解码
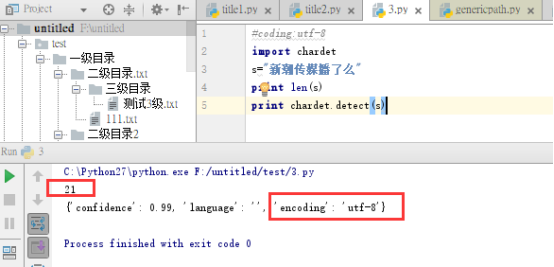
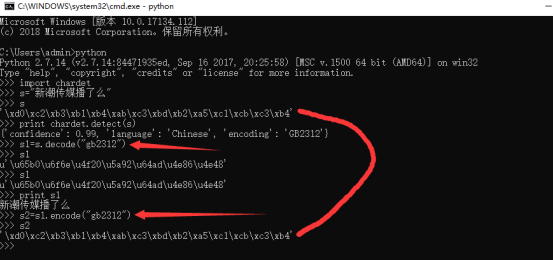
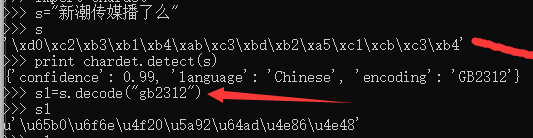
${s} set variable 新潮传媒播了么
${s1} evaluate ${s}.decode(“gbk”)
该方法会报错,原因:decode是解码,encode是编码。解码的参数就是当前字符编码类型,rf 这里的${s}是utf8编码,所以decode(utf8)可以,decode(“gbk”)会报错。上文中cmd能使用,是因为cmd下编码格式是gbk
import chardet
print chardet.detect(s)
调用此方法可查看s的字符编码类型,
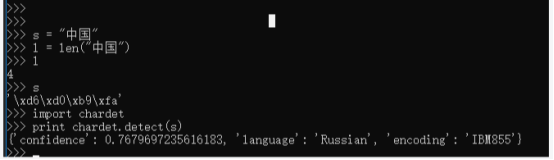
使用chardet.detect(s)编码可能会识别错误,这里错误的识别为encoding:IBM855
结论:当字节包的长度不够长时,chardet给出的结论是很不可靠的,因为它可能在调用一个不相干的探测器时,该探测器给出了一个超过阈值的可信度,或者两个编码格式刚好有共通的字符,增加字符长度可以极大增加识别率
Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有:
Python解释器的默认编码
Python源文件文件编码
Terminal使用的编码
操作系统的语言设置
六:后续
Python创始人在开发初期认知的局限性,其并未预料到python能发展成一个全球流行的语言,导致其开发初期并没有把支持全球各国语言当做重要的事情来做,所以就轻佻的把ASCII当做了默认编码。 当后来大家对支持汉字、日文、法语等语言的呼声越来越高时,Python于是准备引入unicode,但若直接把默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2 就直接 搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型
时间来到2008年,python发展已近20年,创始人龟叔越来越觉得python里的好多东西已发展的不像他的初衷那样,开始变得臃肿、不简洁、且有些设计让人摸不到头脑,比如unicode 与str类型,str 与bytes类型的关系,这给很多python程序员造成了困扰。
龟叔再也忍不了,像之前一样的修修补补已不能让Python变的更好,于是来了个大变革,Python3横空出世,不兼容python2,python3比python2做了非常多的改进,其中一个就是终于把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
参考链接:http://www.cnblogs.com/alex3714/articles/7550940.html
参考链接:http://python.jobbole.com/81244/
python2编码问题的更多相关文章
- python2编码总结(转)
以下依次列出python2常遇到的几个问题及讲解. # -*- coding:utf-8 -*- python2默认以ASCII编码,但是在实际编码过程中,我们会用到很多中文,为了不使包含中文的程序报 ...
- [python]Python2编码问题
以下内容说的都是 python 2.x 版本 简介 基本概念 Python "帮"你做的事情 推荐姿势 基本概念 我们看到的输入输出都是'字符'(characters),计算机(程 ...
- Python2 编码问题分析
本文浅显易懂,绿色纯天然,手工制作,请放心阅读. 编码问题是一个很大很杂的话题,要向彻底的讲明白可以写一本书了.导致乱码的原因很多,系统平台.编程语言.多国语言.软件程序支持.用户选择等都可能导致无法 ...
- python2编码的问题
1,python2的默认编码是ascii码. 2,python2中有2中数据模型来支持字符串这种数据类型,分别为str和unicode. 3,uncode转换为其他编码是encode,其他编码转换成u ...
- python3和python2编码拾遗
py2编码 tr和unicode str和unicode都是basestring的子类.严格意义上说,str其实是字节串,它是unicode经过编码后的字节组成的序列.对UTF-8编码的str'苑'使 ...
- python2 编码问题详解
实例对比 定义 type str unicode print encode('utf8') decode('utf8') encode('unicode-escape') encode('string ...
- python2 编码与解码
#!coding: utf-8 s = "特斯拉" s_to_unicode = s.decode("utf-8") unicode_to_gbk = s_to ...
- 转 PYTHON2 编码处理-str与Unicode的区别
https://www.cnblogs.com/long2015/p/4090824.html
- 从python2,python3编码问题引伸出的通用编码原理解释
今天使用python2编码时遇到这样一条异常UnicodeDecodeError: ‘ascii’ code can’t decode byte 0xef 发现是编码问题,但是平常在python3中几 ...
随机推荐
- Spring Boot与缓存
---恢复内容开始--- JSR-107.Spring缓存抽象.整合Redis 一.JSR107 Java Caching定义了5个核心接口,分别是CachingProvider, CacheMana ...
- antd form 自定义验证表单使用方法
import React from 'react'; import classNames from 'classnames'; export default class FormClass exten ...
- React Native & app demos
React Native & app demos https://github.com/ReactNativeNews/React-Native-Apps https://github.com ...
- 基于Redis实现分布式锁
分布式锁具有的特性: 1.排他性: 文件系统: 数据库:主键 唯一约束 for update 性能较差,容易出现单点故障 锁没有失效时间,容易死锁 缓存Redis:setnx 实现复杂: 存在死锁(或 ...
- python3的字符串和字节
Python3中内置类型bytes和str用法及byte和string之间各种编码转换 Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分.文本总是Unicode(16进制) ...
- Flask 构建微电影视频网站(六)
会员模块实现 会员注册 class RegistForm(FlaskForm): name = StringField( label="昵称", validators=[ Data ...
- 特殊计数序列——第一类斯特林(stirling)数
第一类斯特林数 在这里我因为懒所以还是用\(S(n,m)\)表示第一类斯特林数,但一定要和第二类斯特林数区分开来 递推式 \(S(n,m)=S(n-1.m-1)+S(n-1,m)*(n-1)\) 其中 ...
- Re.多项式求逆
前言 emmm暂无 多项式求逆目的 顾名思义 就是求出一个多项式的摸xn时的逆 给定一个多项式F(x),请求出一个多项式G(x),满足F(x)∗G(x)≡1(modxn),系数对998244353取模 ...
- loadrunner断言多结果返回
有这么一个场景,接口返回的多个状态都是正常的,那么在压测的时候,断言就需要多 init里面执行登录,根据返回获取到tokenId action中,执行登录后的操作,获取响应返回的状态,把正确的状态个数 ...
- [SDOI2017]苹果树
题目描述 https://www.luogu.org/problemnew/show/P3780 题解 一道思路巧妙的背包题. 对于那个奇怪的限制,我们对此稍加分析就可以发现它最后选择的区域是一个包含 ...