从分治算法到 Hadoop MapReduce
从分治算法说起
要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 。其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再分。直到最后的子问题可以简单得求解。
要具体介绍分治算法,那就不得不说一个很经典的排序算法 -- 归并排序。这里不说它的具体算法代码,只说明它的主要思想。而归并排序的思想正是分治思想。
归并排序采用递归的方式,每次都将一个数组分解成更小的两个数组,再对这两个数组进行排序,不断递归下去。直到分解成最简单形式的两个数组的时候,再将这一个个分解后的数组进行合并。这就是归并排序。
下面有一个取自百度百科的具体例子可以看看:
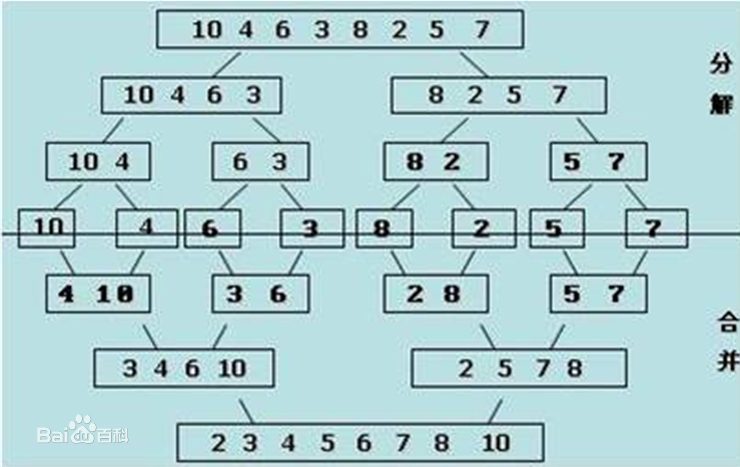
我们可以看到,初始的数组是:{10,4,6,3,8,2,5,7}
第一次分解后,变成两个数组:{10,4,6,3},{8,2,5,7}
分解到最后为 5 个数组:{10},{4,6},{3,8},{2,5},{7}
然后分别合并并排序,最后排序完成:{2,3,4,5,6,7,8,10}
上述的例子这是比较简单的情况,那么我们想想看,当这个数组很大的时候又该怎么办呢?比如这个数组达到 100 GB大小,那么在一台机器上肯定是无法实现或是效率较为低下的。
那一台机器不行,那我们可以拆分到多台机器中去嘛。刚好使用分治算法将一个任务可以拆分成多个小任务,并且这多个小任务间不会相互干扰,可以独立计算。那么我们可以拆分这个数组,将这个数组拆分成 20 个块,每个的大小为 5 GB。然后将这每个 5 GB的块分散到各个不同的机器中去运行,最后再将处理的结果返回,让中央机器再进行一次完整的排序,这样无疑速度上会提升很多。
上述这个过程就是 Hadoop MapReduce 的大致原理了。
函数式的 MapReduce
Map 和 Reduce 其实是函数式编程中的两个语义。Map 和循环 for 类似,只不过它有返回值。比如对一个 List 进行 Map 操作,它就会遍历 List 中的所有元素,然后根据每个元素处理后的结果返回一个新的值。下面这个例子就是利用 map 函数,将 List 中每个元素从 Int 类型 转换为 String 类型。
val a:List[Int] = List(1,2,3,4)
val b:List[String] = a.map(num => (num.toString))
而 Reduce 在函数式编程的作用则是进行数据归约。Reduce 方法需要传入两个参数,然后会递归得对每一个参数执行运算。还是用一个例子来说明:
val list:List[Int] = List(1,2,3,4,5)
//运算顺序是:1-2 = -1; -1-3 = -4; -4-4 = -8; -8-5 = -13;
//所以结果等于 -13
list.reduce(_ - _)
谈谈 Hadoop 的 MapReduce
Hadoop MapReduce 和函数式中的 Map Reduce 还是比较类似的,只是它是一种编程模型。我们来看看 WordCount 的例子就明白了。
在这个 wordcount 程序中,Hadoop MapReduce 会对输入先进行切分,这一步其实就是分治中分的过程。切分后不同部分就会让不同的机器去执行 Map 操作。而后便是 Shuffle,这一阶段会将不相同的单词加到一起,最后再进行 Reduce 。
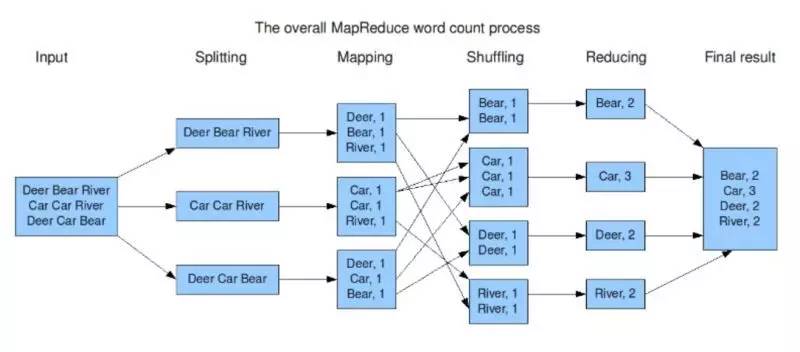
这个 WordCount 程序是官方提供的一个简易的 Demo,更复杂的任务需要自己分解成 Hadoop MapReduce 模型的代码然后执行。
所谓 MapReduce 的意思是任何的事情只要都严格遵循 Map Shuffle Reduce 三个阶段就好。其中Shuffle是系统自己提供的而Map和Reduce则用户需要写代码。
当碰到一个任务的时候,我们需要将它解析成 Map Reduce 的处理方式然后编写 Hadoop MapReduce 代码来实现。我看过一个比喻很贴切,Hadoop MapReduce 这个东西这就像是说我们有一把大砍刀,一个锤子。世界上的万事万物都可以先砍几刀再锤几下,就能搞定。至于刀怎么砍,锤子怎么锤,那就算个人的手艺了。
从模型的角度来看,Hadoop MapReduce 是比较粗糙的,无论什么方法都只能用 Map Reduce 的方式来运行,而这种方式无疑不是万能的,很多应用场景都很难解决。而从做数据库的角度来看,这无非也就是一个 select + groupBy() 。这也就是为什么有了后面 Spark 基于 DAG 的 RDD 概念的崛起。
这里不得不多说一句,Hadoop 的文件系统 Hadoop Hdfs 才是 Hadoop MapReduce 的基础,因为 Map Reduce 最实质的支撑其实就是这个 Hadoop Hdfs 。没有它, Map Reduce 不过是空中阁楼。你看,在 Hadoop MapReduce 式微的今天,Hadoop Hdfs 还不是活得好好的,Spark 或是 Hive 这些工具也都是以它为基础。不得不说,Hadoop Hdfs 才牛逼啊。
为什么会出现 Hadoop MapReduce
好了,接下来我们来探究一下为什么会出现 Hadoop MapReduce 这个东西。
MapReduce 在 Google 最大的应用是做网页的索引。大家都知道 Google 是做搜索引擎起家的,而搜索引擎的基本原理就是索引,就是爬去互联网上的网页,然后对建立 单词->文档 的索引。这样什么搜索关键字,才能找出对应网页。这也是为什么 Google 会以 WordCount 作为 MapReduce 的例子。
既然明白搜索引擎的原理,那应该就明白自 2000 年来互联网爆发的年代,单台机器肯定是不够存储大量的索引的,所以就有了分布式存储,Google 内部用的叫 Gfs,Hadoop Hdfs 其实可以说是山寨 Gfs 来的。而在 Gfs 的基础上,Hadoop MapReduce 的出现也就自然而然了。
推荐阅读:
从分治算法到 Hadoop MapReduce的更多相关文章
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- [转] DAG算法在hadoop中的应用
http://jiezhu2007.iteye.com/blog/2041422 大学里面数据结构里面有专门的一章图论,可惜当年没有认真学习,现在不得不再次捡 起来.真是少壮不努力,老大徒伤悲呀!什么 ...
- Hadoop MapReduce开发最佳实践(上篇)
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- Hadoop mapreduce自定义分组RawComparator
本文发表于本人博客. 今天接着上次[Hadoop mapreduce自定义排序WritableComparable]文章写,按照顺序那么这次应该是讲解自定义分组如何实现,关于操作顺序在这里不多说了,需 ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- MapReduce 示例:减少 Hadoop MapReduce 中的侧连接
摘要:在排序和reducer 阶段,reduce 侧连接过程会产生巨大的网络I/O 流量,在这个阶段,相同键的值被聚集在一起. 本文分享自华为云社区<MapReduce 示例:减少 Hadoop ...
- Hadoop - MapReduce 过程
Hadoop - MapReduce 一.MapReduce设计理念 map--->映射 reduce--->归纳 mapreduce必须构建在hdfs之上的一种大数据离线计算框架 在线: ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
随机推荐
- [Swift]LeetCode127. 单词接龙 | Word Ladder
Given two words (beginWord and endWord), and a dictionary's word list, find the length of shortest t ...
- [Swift]LeetCode664. 奇怪的打印机 | Strange Printer
There is a strange printer with the following two special requirements: The printer can only print a ...
- [Swift]LeetCode884. 两句话中的不常见单词 | Uncommon Words from Two Sentences
We are given two sentences A and B. (A sentence is a string of space separated words. Each word co ...
- [Swift]LeetCode920. 播放列表的数量 | Number of Music Playlists
Your music player contains N different songs and she wants to listen to L (not necessarily different ...
- VMware虚拟机安装Linux系统
许多新手连 Windows 的安装都不太熟悉,更别提 Linux 的安装了:即使安装成功了,也有可能破坏现有的 Windows 系统,比如导致硬盘数据丢失.Windows 无法开机等.所以一直以来,安 ...
- Django+Bootstrap+Mysql 搭建个人博客(三)
3.1.分页功能 (1)views.py from django.core.paginator import Paginator,EmptyPage,PageNotAnInteger def make ...
- 什么是SOAP,有哪些应用
SOAP 是一种轻量级协议,用于在分散型.分布式环境中交换结构化信息. SOAP 利用 XML 技术定义一种可扩展的消息处理框架,它提供了一种可通过多种底层协议进行交换的消息结构. 这种框架的设计思想 ...
- 查找占用资源高的JAVA代码
1. /tmp/hsperfdata_$USER目录 $USER是启动JAVA进程的用户,这里保存的所有用户启动的JAVA进程. 这些都JAVA进程的PID,里面存放的是JVM进程信息.你所用的jsp ...
- 【转载】asp.net core 2.0的认证和授权
在asp.net core中,微软提供了基于认证(Authentication)和授权(Authorization)的方式,来实现权限管理的,本篇博文,介绍基于固定角色的权限管理和自定义角色权限管理, ...
- RabbitMQ消息队列(十三)-VirtualHost与权限管理
像mysql有数据库的概念并且可以指定用户对库和表等操作的权限.那RabbitMQ呢?RabbitMQ也有类似的权限管理.在RabbitMQ中可以虚拟消息服务器VirtualHost,每个Virtua ...