linux磁盘分区笔记
磁盘基本概念:
硬盘结构:盘片+磁头(盘片可以有多个),工作时盘片高速运转,磁头读取数据
U盘、SSD固态硬盘是用闪存来制作的设备,没有盘片和磁头
Linux磁盘文件名:
Linux所有设备都抽象为文件保存在 /dev 目录下
早期的IDE接口的磁盘在linux中的文件名为 /dev/hd[a-z]
SATA/USB/SAS 等磁盘接口都是使用SCSI模块来驱动,因此这些接口的磁盘装置文件都为:/dev/sd[a-z],
不过近年来大部分linux发行版本已经将IDE界面的磁盘文件名也仿真成SATA一样了,所以不必再关心不同接口磁盘装置文件名问题了,不过还有虚拟磁盘;
虚拟磁盘的文件名为:/dev/vd[a-p]
如果你的电脑上插了多个磁盘,这时就要根据Linux核心侦测到磁盘的顺序来决定他的装置文件名了。(跟实际插槽代号无关)
磁盘分区机制:
主流的磁盘分区机制有两种:
MBR(Master Boot Record)格式和 GPT(GUID partition table)格式;
分区是软件概念;
MBR的分区格式:
早期的Linux系统为了兼容Windows的磁盘,使用的是支持Windows的MBR的方式来处理开机管理程序与分区表;
开机管理记录和分区表通通放在磁盘的第一个扇区,这个扇区通常是512bytes大小,里面保存了这两个数据:
1、主要启动记录区:可以安装开机管理程序的地方,有446bytes
2、分区表:记录整颗分区的状态,有64bytes
其实所谓的 分区 只是针对那个64bytes的分区表进行设定而已
MBR支持的分区数量有限:四个分区记录(主分区或扩展分区);
MBR分区机制大多使用在BIOS的PC设备;
MBR支持32bit和64bit;
MBR只能分区2.2T的硬盘,超过2T的硬盘将只能使用2.2T空间(有第三方工具可以解决);
将硬盘分区超过四个分区槽:
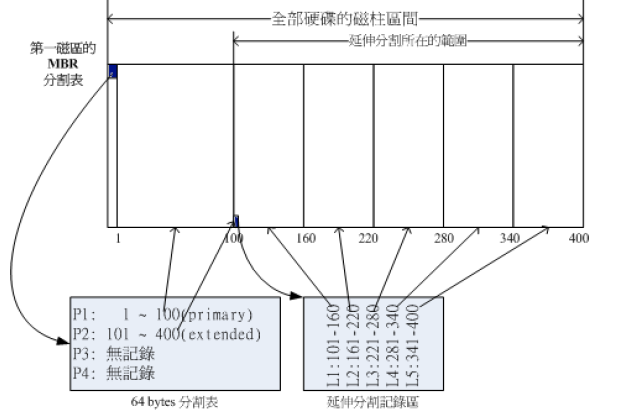
在上图中,硬盘的四个分区记录只适用了两个,P1为主分区(Primary),P2为扩展分区(Extended),然后在扩展分区内继续做分区的记录,
这五个由扩展分区继续切出来的分区,称为逻辑分区(Logical partition)
注意:
扩展分区是不能被格式化的(它是不能用的),它的作用就是占用一个主分区,然后区分成多个逻辑分区
上图的分区槽在linux系统中的装置文件名分别如下:
P1:/dev/sda1
P2:/dev/sda2
L1:/dev/sda5
L2:/dev/sda6
L3:/dev/sda7
L4:/dev/sda8
L5:/dev/sda9
为什么没有 /dev/sda3 和 /dev/sda4 呢?
因为前面四个号码都是保留给主分区或扩展分区用的!逻辑分区的装置名称号码都是由5号开始
由于硬盘的第一个扇区所记录的是分区表和MBR,而且只要读取硬盘都会先由这个扇区读起,所以如果硬盘的第一个扇区物理实体坏掉了,那这个硬盘就没用了
GPT分区格式:
过去一个扇区大小是512bytes,现在已经有4k的扇区设计出现。为了兼容所有的硬盘,在扇区的定义上,大多会使用逻辑区块地址(Logical Block Address,LBA)来处理,GPT将硬盘所有区块以此LBA来规划,第一个LBA称为LBA0(从0开始编号)
GPT使用了34个LBA区块来记录分区!同时与过去MBR仅有一的区块,被干掉就死光光的情况不同, GPT除了前面34个LBA之外,整个硬盘的最后33个LBA也拿来作为另一个备份
LBA0 (MBR 相容区块)
与MBR模式相似的,这个相容区块也分为两个部份,一个就是跟之前446 bytes相似的区块,储存了第一阶段的开机管理程式!而在原本的分区表的记录区内,这个相容模式仅放入一个特殊标志的分割,用来表示此硬盘为GPT格式之意。
LBA1 (GPT 表头纪录)
这个部份记录了分区表本身的位置与大小,同时纪录了备份用的GPT分割,, 同时放置了分区表的检验机制码(CRC32 ),作业系统可以根据这个检验码来判断GPT 是否正确。若有错误,还可以通过这个记录区来取得备份的GPT
LBA2-33 (实际记录分区数据处)
从LBA2区块开始,每个LBA都可以记录4笔分割记录,所以在预设的情况下,总共可以有4*32 = 128笔分割记录喔!因为每个LBA有512bytes,因此每笔记录用到128 bytes的空间,除了每笔记录所需要的识别码与相关的记录之外,GPT在每笔记录中分别提供了64bits来记载开始/结束的磁区号码,因此,GPT分割表对于单一分割槽来说,他的最大容量限制就会在『 2 64 * 512bytes = 2 63 * 1Kbytes = 2 33 *TB = 8 ZB 』,要注意1ZB = 2 30 TB
GPT 分区已经没有所谓的主分区、扩展分区、逻辑分区的概念,每一个分区都可以拿来格式化使用
GPT向后兼容MBR
必须使用64位
GPT必须在支持UEFI的硬盘上才能使用
FDISK分区工具:
fdisk是一个基于MBR的分区工具,它是无法使用GPT格式分区的
linux磁盘分区笔记的更多相关文章
- Linux磁盘分区(一)之fdisk命令
Linux磁盘分区(一)之fdisk命令转自:https://www.cnblogs.com/machangwei-8/p/10353683.html 一.fdisk 的介绍fdsik 能划分磁盘成为 ...
- linux磁盘分区模式
linux磁盘分区模式 模式一:MBR 1)主分区不超过四个 2)单个分区容量最大2TB 模式二:GPT 1)主分区个数"几乎"没有限制(原因:在GPT的分区表中最多可以支持128 ...
- <实训|第七天>横扫Linux磁盘分区、软件安装障碍附制作软件仓库
期待已久的linux运维.oracle"培训班"终于开班了,我从已经开始长期四个半月的linux运维.oracle培训,每天白天我会好好学习,晚上回来我会努力更新教程,包括今天学到 ...
- 调整Linux磁盘分区的大小的方法
昨天数据入库时,一直报错,说磁盘满了,,df -h 一看,发现/目录下只有50G空间,已使用49G:我的程序和dbss都安装在/目录下,ftp到的数据放在/data下的一个子目录下,分解完的 ...
- Linux磁盘分区与格式化
磁盘分区格式说明 linux分区不同于windows linux下分区标示: 例如:hda1 hd这两个字母表示分区所在的设备类型,hd标示IDE类型硬盘,sd表示SCSI类型硬盘 第三字母a标示硬盘 ...
- Linux fdisk命令参数及用法详解---Linux磁盘分区管理命令fdisk
fdisk 命令 linux磁盘分区管理 用途:观察硬盘之实体使用情形与分割硬盘用. 使用方法: 一.在 console 上输入 fdisk -l /dev/sda ,观察硬盘之实体使用情形. 二.在 ...
- Linux 磁盘分区修改与管理
--Linux 磁盘分区修改与管理 -----------------------------2014/03/05 1. 目的,将磁盘卷/dev/cciss/c0d0p8修改成新的用途. 原: /de ...
- Linux 磁盘分区方案简析
Linux 磁盘分区方案简析 by:授客 QQ:1033553122 磁盘分区 任何硬盘在使用前都要进行分区.硬盘的分区有两种类型:主分区和扩展分区.一个硬盘上最多只能有4个主分区,其中一个主分区 ...
- Linux磁盘分区与文件系统
一 Linux磁盘分区与文件系统 在Linux中常见的操作系统有:ext2 ext3 ext4 xfs btrfs reiserfs等文件系统的作用主要是明确磁盘或分区上的文件存储方法以及数据结构,L ...
随机推荐
- js dictionary
转载的 1.dictionary例子 <script type="text/javascript" language="javascript"> v ...
- 《用Python写爬虫》学习笔记(二)编写第一个网络爬虫
1.首先,下载网页使用Python的urllib2模块,或者Python HTTP模块request来实现 urllib2会出现问题,解决方法1.重试下载(设置下载次数) 2.设置用户代理 2.其次, ...
- linux创建虚拟环境
linux提供的虚拟环境工具: virtualenv pipenv 1.安装python的虚拟环境 pip3 install -i https://pypi.tuna.tsinghua.edu.c ...
- npx
npx 是什么? npm v5.2.0引入的一条命令(npx),引入这个命令的目的是为了提升开发者使用包内提供的命令行工具的体验. 举例:使用create-react-app创建一个react项目. ...
- java8中optional和.stream().map()
使用optional的好处:是一个可以包含或不可以包含非空值的容器对象,更加友好的处理程序中的空对象. Optional<T>有方法 isPresent() 和 get() 是用来检查其包 ...
- spring security 学习
1.默认登录 user /df1fc617-bb94-494e-8adb-0234046bf092 取消校验 在启动类上添加下面的注解 @EnableAutoConfiguration(excl ...
- 使用PuTTY软件远程登录root被拒:access denied
PuTTY是一个Telnet.SSH.rlogin.纯TCP以及串行接口连接软件. 使用PuTTY软件远程登录root时,提示:ACCESS DENIED,很有可能是由sshd的默认配置造成的. 可以 ...
- struts2之数据校验
概述 在提交表单数据时,如果数据需要保存到数据库,空输入等可能会引发一些异常,为了避免引起用户的输入引起底层异常,通常在进行业务逻辑操作之前,先执行基本的数据校验. 下面通过四种方式来阐述Struts ...
- windows上传文件到linux云服务器上
安装putty,将pscp.exe移到 C:\Windows\System32 目录下. 在cmd 中执行,pscp -l rot -pw [password] -ls [ip]:/opt 查看目录 ...
- linux之关于学习必备知识
文件列表的定义: 第一个字符表示文件类型 d为目录 -为普通 1为链接 b为可存储的设备接口 c为键盘鼠标等输入设备 2~4个字符表示所有者权限,5~7个字符表示所有者同组用户权限,8~10 ...