006-Hadoop Hive sql语法详解1-数据结构和Hive表建立
1.认识hive:
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插件来支持Hive 做更复杂的数据分析。
它与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。HIVE不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合。
基础数据结构
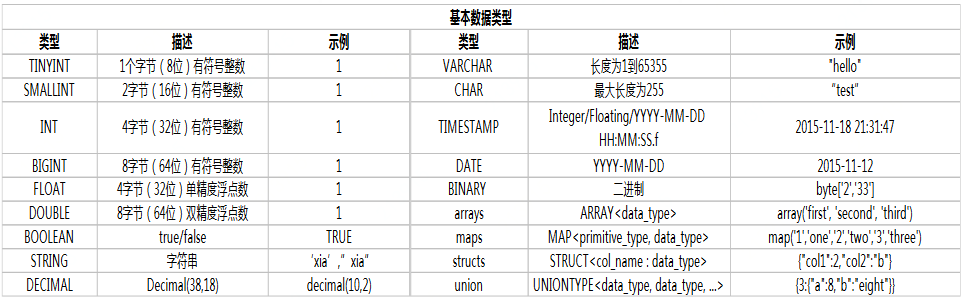
类型装换
cast(字段名or具体值 as 指定类型)
示例:select cast(1 as double) from table
2. DDL 操作
一个表可以拥有一个或多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
创建表,指定EXTERNAL就是外部表,没有指定就是内部表,内部表在drop的时候会从hdfs上删除数据,而外部表不会删除。
如果不指定数据库,hive会把表创建在default数据库下
创建简单表
hive> CREATE TABLE pokes (foo INT, bar STRING);
复杂一下如下:
创建外部表:
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';
建分区表:
CREATE TABLE par_table(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(date STRING, pos STRING)
ROW FORMAT DELIMITED ‘\t’
FIELDS TERMINATED BY '\n'
STORED AS SEQUENCEFILE;
建Bucket表
CREATE TABLE par_table(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(date STRING, pos STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED ‘\t’
FIELDS TERMINATED BY '\n'
STORED AS SEQUENCEFILE;
创建表并创建索引字段ds
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
复制一个空表
CREATE TABLE empty_key_value_store
LIKE key_value_store;
例子
create table user_info (user_id int, cid string, ckid string, username string)
row format delimited
fields terminated by '\t'
lines terminated by '\n';
导入数据表的数据格式是:字段之间是tab键分割,行之间是断行。
及要我们的文件内容格式:
100636 100890 c5c86f4cddc15eb7 yyyvybtvt
100612 100865 97cc70d411c18b6f gyvcycy
100078 100087 ecd6026a15ffddf5 qa000100
显示所有表
hive> SHOW TABLES;
按正条件(正则表达式)显示表,
hive> SHOW TABLES '.*s';
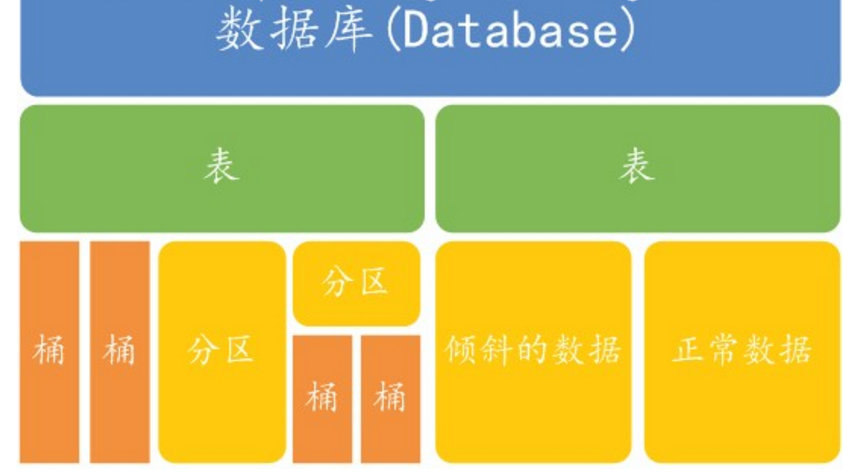
三、“外部表”、“分区表”、“Bucket表”
Bucket表和另外两个表不是同一个概念:
1、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
2、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
3、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user/hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
006-Hadoop Hive sql语法详解1-数据结构和Hive表建立的更多相关文章
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- [转]Hadoop Hive sql语法详解
转自 : http://blog.csdn.net/hguisu/article/details/7256833 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式 ...
- Hadoop Hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询 ...
- 【hive】——Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQ ...
- 009-Hadoop Hive sql语法详解4-DQL 操作:数据查询SQL-select、join、union、udtf
一.基本的Select 操作 语法SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE whe ...
- 010-Hadoop Hive sql语法详解5-HiveQL与SQL区别
1.Hive不支持等值连接 •SQL中对两表内联可以写成:•select * from dual a,dual b where a.key = b.key;•Hive中应为•select * from ...
- 008-Hadoop Hive sql语法详解3-DML 操作:元数据存储
一.概述 hive不支持用insert语句一条一条的进行插入操作,也不支持update操作.数据是以load的方式加载到建立好的表中.数据一旦导入就不可以修改. DML包括:INSERT插入.UPDA ...
随机推荐
- Hdu 2236 无题II 最大匹配+二分
题目链接: pid=2236">Hdu 2236 解题思路: 将行和列理解为二分图两边的端点,给出的矩阵即为二分图中的全部边, 假设二分图能全然匹配,则说明 不同行 不同列的n个元素 ...
- SQL Server 数据库同步,订阅、发布、复制、跨服务器
随便说两句 折腾了一周,也算把数据库同步弄好了.首先局域网内搭建好,进行各种测试,弄的时候各种问题,弄好以后感觉还是挺简单的.本地测试好了,又在服务器进行测试,主要的难点就是跨网段同步,最后也解决了, ...
- 在windows中将Tomcat作为服务启动
http://www.cnblogs.com/chuyuhuashi/archive/2012/04/28/2475315.html ————————————————————————————————— ...
- 如何解决PHP里大量数据循环时内存耗尽的问题
最近在开发一个PHP程序时遇到了下面的错误: PHP Fatal error: Allowed memory size of 268 435 456 bytes exhausted 错误信息显示允许的 ...
- div随页面滚动遇顶固定的两种方法(js&jQuery)
一.遇顶固定的例子 我一直以为是某个div或层随屏幕滚动,遇顶则固定,离开浏览器顶部又还原这样的例子其实不少,其实它的名字叫“层的智能浮动效果”.目前我们在国内的商业网站上就常常看到这样的效果了.例如 ...
- 关于Unity中调试C#的方法
1.断点输出语句 在感觉有问题的地方的上下文写一些输出语句,如果控制台只有输出上文,没有输出下文,那么可以知道,上下文之间的语句有问题,因为下文没执行到,没有输出语句. Debug.Log(" ...
- IIS状态码大全【转】
对于站长来说,经常分析下网站的IIS日志是有好处的,这样可以随时了解SE蜘蛛是否经常光顾自己的网站,都抓取了哪些页面,被抓取的页面哪些是被正常的,哪些是不正常的.而IIS日志有专门的返回状态码,为了方 ...
- 项目中遇到的direct3d问题,设备丢失
今天在调试项目的时候,遇到一个问题,之前在写代码的时候,调试都是在本地的电脑上进行调试,然而今天是通过远程登陆到电脑进行调试的,所以在调试的过程中遇到了一个问题. 其实开始的时候,有同事反应说,当远程 ...
- 第十篇:Linux中权限的再讨论( 上 )
前言 在Linux系统中,用户分为 个权限位.好了,很多朋友对于Linux权限的了解就仅限于此了.但,Linux目录权限和文件权限一样吗?内核对于权限的检查过程又是怎样的? 如果你不清楚,本文将为你解 ...
- map重写比较器
结构体作为map的key或放入set中,需要重载<运算符,如下: typedef struct tagRoadKey { int m_i32Type; int m_i32Scale; bool ...