Python开发基础-Day33 IO模型
IO模型分类
五种IO Model
blocking IO 阻塞IO
nonblocking IO 非阻塞IO
IO multiplexing IO多路复用
signal driven IO 信号驱动IO
asynchronous IO 异步IO
signal driven IO(信号驱动IO)在实际中并不常用,所以只剩下四种IO Model。
网络IO的两个过程
对于一个network IO ,会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
- 等待数据准备 (Waiting for the data to be ready):等待系统接收数据
- 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process):进程从系统缓存中拿到数据
同步IO:在这两个过程中有任意阶段出现阻塞状态。
阻塞IO、非阻塞IO、IO多路复用都是同步IO
异步IO:全程无阻塞的IO
异步IO属于异步IO(真的没毛病)
阻塞IO(Blocking IO)
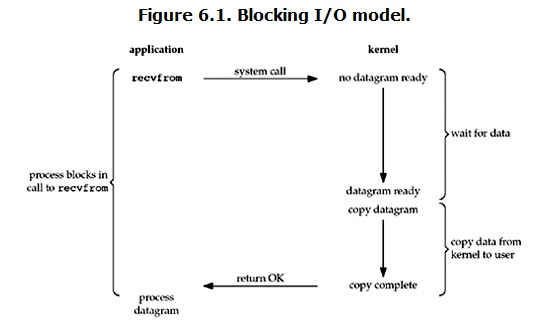
UDP包:当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
blocking IO的特点就是在IO执行的两个阶段都被block了。
示例:
#服务端
import socket
sock=socket.socket() #默认是TCP
sock.bind(("127.0.0.1",8088)) sock.listen(5)
while True:
conn,addr=sock.accept() #默认是就是阻塞的方式,监听等待客户端连接(阶段一):等待中的阻塞
#客户端连接后接收数据(阶段二):socket对象和客户端地址,虽然接收数据的过程很快但是实际上也是阻塞
while True:
data=conn.recv(1024) #也是两个阶段的阻塞
print(data.decode('utf8'))
if data.decode('utf8') =='q':
break
respnse=input('>>>>')
conn.send(respnse.encode('utf8')) #客户端
import socket
sock=socket.socket()
sock.connect(("127.0.0.1",8088)) while True:
data=input('>>>').strip()
sock.send(data.encode('utf8'))
s_data = sock.recv(1024) #两个阶段的阻塞
print(s_data.decode('utf8'))
非阻塞IO(Non-blocking IO)
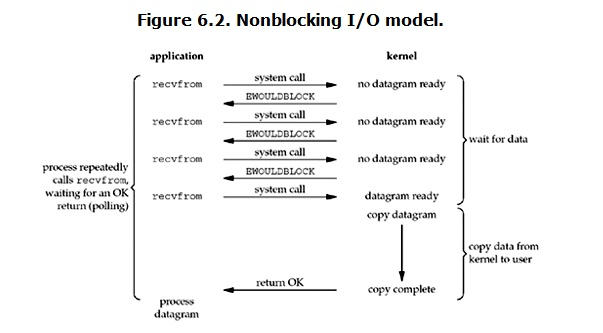
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。所以用户进程不需要等待,而是马上就得到了一个结果,用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。这个过程中,用户进程是需要不断的主动询问kernel数据好了没有。
非阻塞实际上是将大的整片时间的阻塞分成N多的小的阻塞,每次recvform系统调用之间,可以干点别的事情,然后再发起recvform系统调用,重复的过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
#服务端 import socket
import time
sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #默认是TCP
sock.bind(("127.0.0.1",8088))
sock.listen(5)
sock.setblocking(False) while True:
try:
print('server waiting')
conn, addr = sock.accept() # 默认是个阻塞的方式,等待客户端连接
while True:
data = conn.recv(1024) #这边也是阻塞的IO
print(data.decode('utf8'))
if data.decode('utf8') == 'q':
break
respnse = input('>>>>')
conn.send(respnse.encode('utf8'))
except Exception as e:
print (e)
time.sleep(4) #客户端
import socket
sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #默认是TCP while True:
sock.connect(("127.0.0.1", 8088)) #因为服务端recv也是非阻塞,所以要不断重新连接
data=input('>>>').strip()
sock.send(data.encode('utf8'))
s_data = sock.recv(1024)
print(s_data.decode('utf8'))
IO多路复用(IO multiplexing)
IO多路复用,也叫做event driven IO,实现方式:select,poll或epoll
IO多路复用的好处就在于单个process就可以同时处理多个网络连接的IO
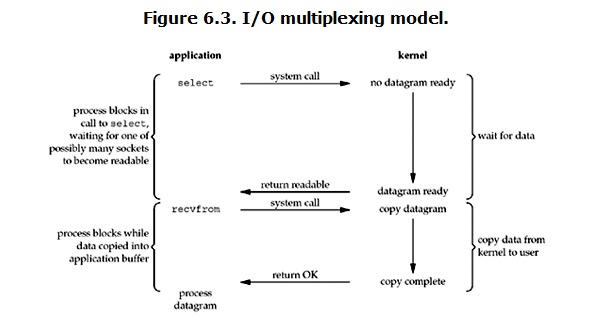
用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。这个过程中有两次system call(系统调用) select阻塞时候 和 recvfrom阻塞时候。用多路复用的的优势在于它可以同时处理大批量的connection,不适用单个或少量,少量还不如multi-threading + blocking IO。
select示例:
#服务端
import socket
import select
sock=socket.socket()
sock.bind(("127.0.0.1",8088))
sock.listen(5) inp=[sock,] #定义监听的套接字对象列表,列表列表里可以有多个对象 while True:
#字段顺序:input list 、output list、error list、date(可以不写)
r=select.select(inp,[],[],None) #对比的是sock.accept(),这一步只做了监听的事情,监听哪个socket对象活动,当没有客户端连接时候会阻塞
# 当监听到有活动的socket对象时候,将返回值给r
print('r',r)
print('r',r[0])
#r接收的返回是一个元组,r[0]是活动的对象列表 for obj in r[0]:
if obj == sock: #如果活动的对象是sock,那么将客户端对象加入监听列表,客户端再发数据时候,触发客户端的对象活动
conn,addr=obj.accept() #accept只做第二个阶段的事情,取回数据:client的socket对象和地址
print(conn,addr)
inp.append(conn)
else:
data=obj.recv(1024)
print(data.decode('utf8'))
resp=input('>>>')
obj.send(resp.encode('utf8')) #客户端
import socket
sock=socket.socket()
sock.connect(("127.0.0.1", 8088))
while True:
data=input('>>>').strip()
sock.send(data.encode('utf8'))
s_data = sock.recv(1024)
print(s_data.decode('utf8'))
因为使用的是for循环,当多个客户端发消息给服务端,只能一个个顺序处理。
在windows下只能用select实现多路复用
在Linux可以使用select、poll、epoll实现,推荐使用epoll,对比:
select和poll的监听方式为轮询方式,即每次都要循环一遍监听列表,效率低,另外select有连接数限制,poll无限
epoll连接数无限,区别在于监听方式不同,每个socket对象绑定一个回调函数,当socket对象活动了就触发回调函数,把自己写到活动列表中,epoll直接调用活动列表
信号驱动IO(signal driven IO)
不常用,不做说明
异步IO(Asynchronous I/O)
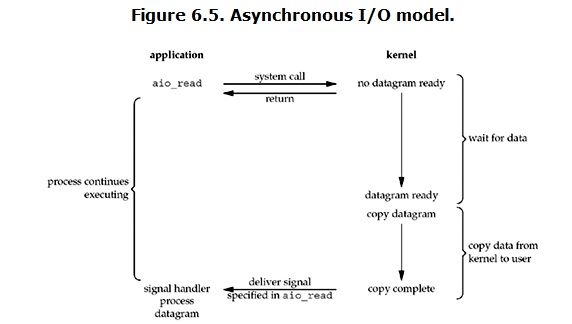
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
IO模型区别
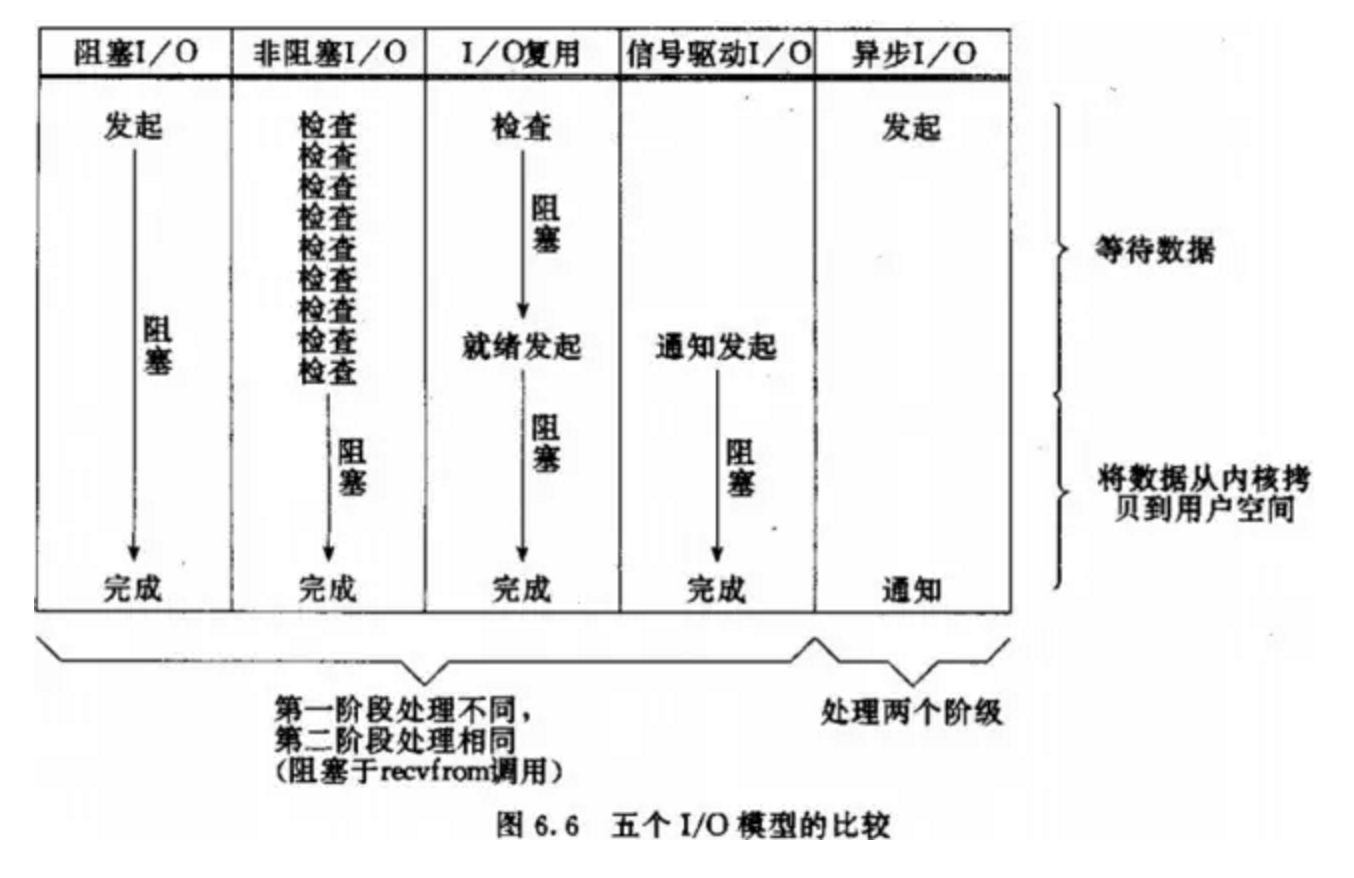
selectors模块
该模块能够按照系统平台,自动选择多路复用的方式。
#服务端
import selectors
import socket sel=selectors.DefaultSelector() def accept(sock,mask):
conn,addr=sock.accept() #4、获取客户端的conn对象和地址
print('accetped',conn,'from',addr)
conn.setblocking(False)
sel.register(conn,selectors.EVENT_READ,read) #5、注册conn对象,将conn对象和函数read绑定 def read(conn,mask):
data=conn.recv(1024) #9、服务端通过conn对象接收消息,进行下面的逻辑处理
if data:
print('echoing',repr(data),'to',conn)
conn.send(data)
else:
print('closing',conn)
sel.unregister(conn)
conn.close() sock=socket.socket()
sock.bind(('127.0.0.1',8088))
sock.listen(100)
sock.setblocking(False)
sel.register(sock,selectors.EVENT_READ,accept) #sock对象注册绑定accept函数 while True:
#不管是哪个方式,都是使用select方法监听活动的socket对象
events=sel.select() #1、执行sel阻塞监听,当有客户端连接,激活sock对象,返回一个存放活动sock对象相关信息的列表
#6、客户端通过conn对象发送消息,激活sel监听列表中的的conn对象,返回一个存放活动conn对象相关信息的列表
print(events,type(events))
for key,mask in events:
print(mask)
print(key.data) #socket对象注册绑定的accept函数
print(key.fileobj)
callback=key.data #2、取得返回的sock绑定的函数
#7、取得返回conn绑定的函数
callback(key.fileobj,mask) #3、key.fileobj是sock对象,执行函数
#8、执行函数read,并传入conn对象 #客户端
import socket
sock=socket.socket()
sock.connect(("127.0.0.1", 8088))
while True:
data=input('>>>').strip()
sock.send(data.encode('utf8'))
s_data = sock.recv(1024)
print(s_data.decode('utf8'))
Python开发基础-Day33 IO模型的更多相关文章
- Python文件基础操作(IO入门1)
转载请标明出处: http://www.cnblogs.com/why168888/p/6422270.html 本文出自:[Edwin博客园] Python文件基础操作(IO入门1) 1. pyth ...
- python 全栈开发,Day44(IO模型介绍,阻塞IO,非阻塞IO,多路复用IO,异步IO,IO模型比较分析,selectors模块,垃圾回收机制)
昨日内容回顾 协程实际上是一个线程,执行了多个任务,遇到IO就切换 切换,可以使用yield,greenlet 遇到IO gevent: 检测到IO,能够使用greenlet实现自动切换,规避了IO阻 ...
- python基础27 -----python进程终结篇-----IO模型
一.IO模型 1.IO模型分类 1.阻塞IO--------blocking IO 2.非阻塞IO------nonblocking IO 3. 多路复用IO------- multiplexing ...
- python基础(17)-IO模型&selector模块
先说一下IO发生时涉及的对象和步骤.对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(k ...
- python基础之IO模型
IO模型分类 五种IO Model blocking IO 阻塞IO nonblocking IO 非阻塞IO IO multiplexing IO多路复用 signal driven IO 信号驱动 ...
- python网络编程——网络IO模型
1 网络IO模型介绍 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-bl ...
- Python socket编程之IO模型介绍(多路复用*)
1.I/O基础知识 1.1 什么是文件描述符? 在网络中,一个socket对象就是1个文件描述符,在文件中,1个文件句柄(即file对象)就是1个文件描述符.其实可以理解为就是一个“指针”或“句柄”, ...
- 还在用Alpine作为你Docker的Python开发基础镜像?其实Ubuntu更好一点
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_173 一般情况下,当你想为你的Python开发环境选择一个基础镜像时,大多数人都会选择Alpine,为什么?因为它太小了,仅仅只有 ...
- Python并发编程之IO模型
目录 IO模型介绍 阻塞IO(blocking IO) 非阻塞IO(non-blocking IO) IO多路复用 异步IO IO模型比较分析 selectors模块 一.IO模型介绍 Stevens ...
随机推荐
- 【BZOJ】2440: [中山市选2011]完全平方数
[题意]T次询问第k小的非完全平方数倍数的数.T<=50,k<=10^9.(即无平方因子数——素因数指数皆为0或1的数) [算法]数论(莫比乌斯函数) [题解]考虑二分,转化为询问[1,x ...
- 【CodeForces】576 C. Points on Plane
[题目]C. Points on Plane [题意]给定坐标系中n个点的坐标(范围[0,10^6]),求一种 [ 连边形成链后总长度<=2.5*10^9 ] 的方案.n<=10^6. [ ...
- 20155117王震宇 2006-2007-2 《Java程序设计》第一周学习总结
20155117王震宇 2006-2007-2 <Java程序设计>第一周学习总结 教材学习内容总结 尽量简单的总结一下本周学习内容 尽量不要抄书,浪费时间 看懂就过,看不懂,学习有心得的 ...
- # 2018高考&自主招生 - 游记
准备了一整个学期的高考和自主招生终于结束了....从育英出来, 以一个失败者的身份来写游记, 权当为明年的决战提供经验与总结. Day -1, June 5th 下午同学收拾考场, 自己在那里看书.. ...
- C# 动态调取 soap 接口
调用示例 string url = "http://localhost:8080/server/PatientService.asmx"; Hashtable ht = new H ...
- Linux内核同步原语之原子操作
避免对同一数据的并发访问(通常由中断.对称多处理器.内核抢占等引起)称为同步. ——题记 内核源码:Linux-2.6.38.8.tar.bz2 目标平台:ARM体系结构 原子操作确保对同一数据的“读 ...
- HTTP 请求 的方法Util
HTTP请求 的一系列方法总结 /** * *******************************传统请求--开始************************************** ...
- 《深入理解Java虚拟机》笔记--第二章、Java内存区域与内存溢出异常
Java程序员把内存的控制权交给了Java虚拟机.在Java虚拟机内存管理机制的帮助下,程序员不再需要为每一个new操作写对应的delete/free代码,而且不容易出现内存泄露和溢出. 虚拟机在执行 ...
- 批量生成AWR报告(转载总结)
[前提] 对Oracle进行性能分析其中一个“帮手”就是Oracle的AWR报告 PS:Oracle的企业版才有AWR报告,标准版是没有的{可以导出来,但是没有数据显示} [需求] 当需要针对某个月的 ...
- 欧拉回路&欧拉通路判断
欧拉回路:图G,若存在一条路,经过G中每条边有且仅有一次,称这条路为欧拉路,如果存在一条回路经过G每条边有且仅有一次, 称这条回路为欧拉回路.具有欧拉回路的图成为欧拉图. 判断欧拉通路是否存在的方法 ...