R语言、02 案例2-1 Pelican商店、《商务与经济统计》案例题
编程教材 《R语言实战·第2版》Robert I. Kabacoff
课程教材《商务与经济统计·原书第13版》 (安德森)
P48、案例2-1 Pelican 商店
PS C:\Users\小能喵喵喵\Desktop\R\homework\1_Pelican> tree /f
C:.
│ pelican.r
│
├───.vscode
│ launch.json
│
└───data
PelicanStores.csv
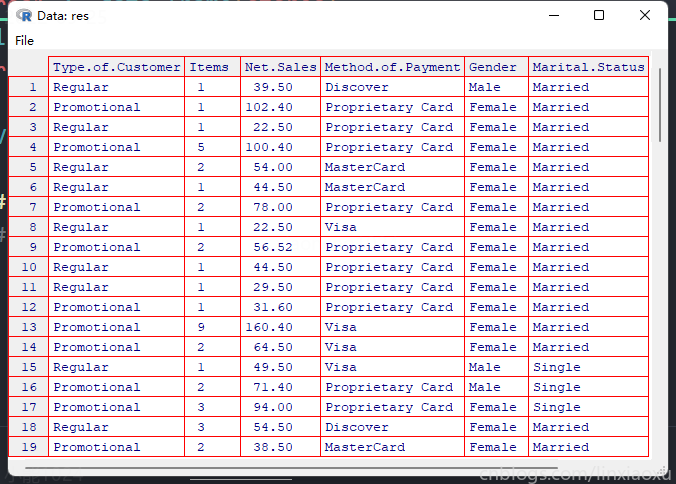
加载数据
编程教材p32 2.3.2
已知数据集为csv文件,所以要按间隔符形式导入。并删除带缺省值的列。
stores <- read.table("./data/PelicanStores.csv",
header = TRUE, row.names = "Customer", sep = ","
)
res1 <- data.frame(stores)
library(dplyr)
res <- res1 %>% select_if(~ !any(is.na(.)))
print(summary(res))
View(res)
主要变量的百分数频数分布
编程教材 p21~30 、p137~143
顾客类型、支付类型
# ^ 百分数频数分布
# @ 客户类型
typeTable1 <- table(res$Type.of.Customer)
typeTable1 <- prop.table(typeTable1) * 100
print(typeTable1)
# @ 支付方法
typeTable2 <- table(res$Method.of.Payment)
typeTable2 <- prop.table(typeTable2) * 100
print(typeTable2)

销售额类型
课程教材 p25 2.2.1
首先我们要确定组宽,公式为 \(近似组宽=\frac{数据最大值-数据最小值}{组数}\)
Max. :287.59 Min. : 13.23。数据项较少的情况下给定5组互不重叠的组数。组宽约等于 55
# @ 销售额频率分组
typeTable3 <- within(res, {
group1 <- NA
group1[Net.Sales >= 13 & Net.Sales < 68] <- "13.0~67.9"
group1[Net.Sales >= 68 & Net.Sales < 123] <- "68.0~122.9"
group1[Net.Sales >= 123 & Net.Sales < 178] <- "123~177.9"
group1[Net.Sales >= 178 & Net.Sales < 233] <- "178~222.9"
group1[Net.Sales >= 233 & Net.Sales < 288] <- "223~287.9"
})
# print(head(sales))
typeTable3 <- table(typeTable3$group1)
typeTable3 <- prop.table(typeTable3) * 100
print(typeTable3)

条形图或圆饼图显示顾客付款方法数量
编程教材 p110~117
条形图
# ^ 支付方式条形图
png(file = "typeTable2_barplot.png")
par(mar = c(10, 4, 4, 0))
barplot(typeTable2,
main = "100个顾客付款方法数量条形图",
xlab = "", ylab = "频数", las = 2
)
dev.off()
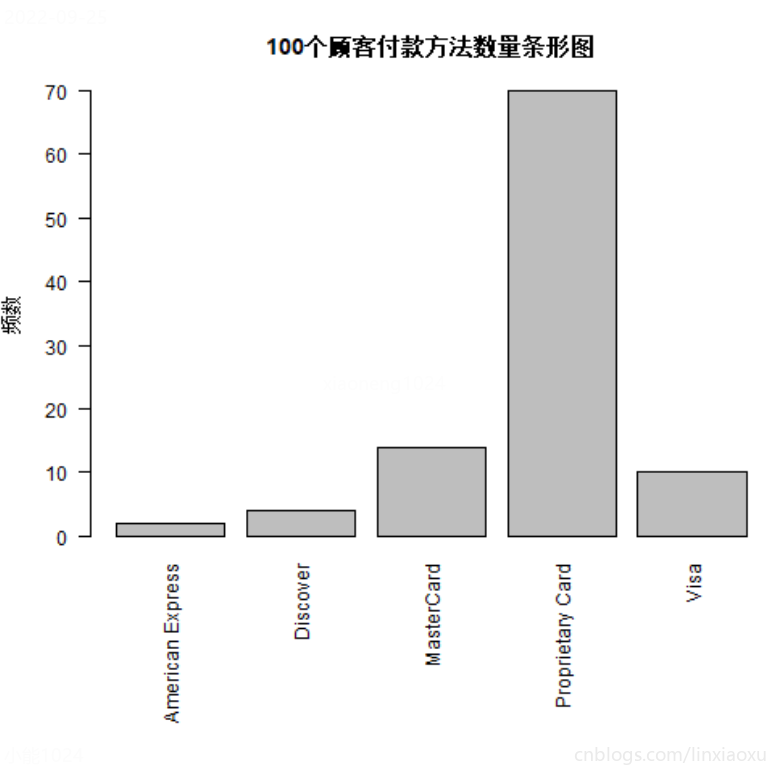
圆饼图
# ^ 支付方式圆饼图
png(file = "typeTable2_pie.png")
colors <- c("#4286f4", "#bb3af2", "#ed2f52", "#efc023", "#ea7441")
pie(typeTable2,
main = "Daily Diet Plan",
col = colors, init.angle = 180, clockwise = TRUE
)
dev.off()
顾客类型与净销售额的交叉分组表
编程教材 p137~143 课程教材 p34
# ^ 顾客类型与净销售额的交叉分组表
crossTable <- with(typeTable3, table(Type.of.Customer, group1))
View(addmargins(crossTable))

把交叉分组表中的项目转换成行百分比数或者列百分比数。上面的表格两个类型频数差别太大
# ^ 顾客类型与净销售额的交叉分组表
crossTable <- with(typeTable3, table(Type.of.Customer, group1))
View(crossTable)
# @ 每个顾客类型的行百分比
crossTable <- round(prop.table(crossTable, 1) * 100, 2)
crossTable <- cbind(crossTable, sum = rowSums(crossTable[, 1:5]))
View(crossTable)
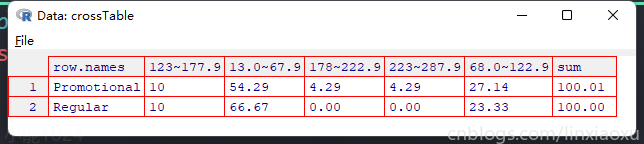
普通顾客和促销顾客的净销售额并没有明显区别,但促销顾客出现部分大额净销售额178~287.9,是因为促销活动发的优惠卷促进了消费者的消费欲望,利用消费者的投机心理来促进多买行为。
净销售额与顾客年龄关系的散点图
# ^净销售额与顾客年龄关系的散点图
png(file = "res_scatterplot.png")
plot(
x = res$Net.Sales, y = res$Age,
xlab = "净销售额",
ylab = "年龄",
xlim = c(10, 300),
ylim = c(20, 80),
main = "净销售额与顾客年龄关系的散点图"
)
dev.off()
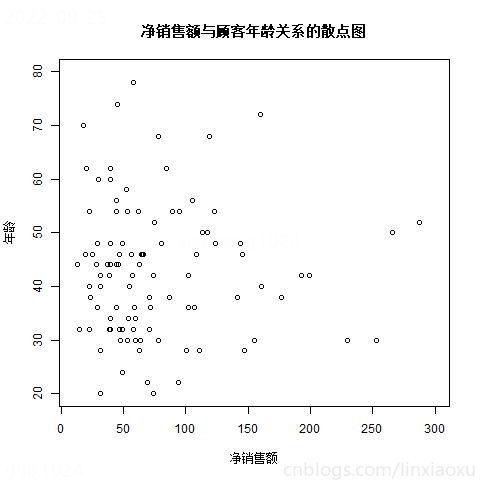
两个变量之间没有明显相关。但可以发现无论顾客年龄多少,净销售额大多都在0~150区间。
资料
每一行数据求和
cbind(crossTable, sum = rowSums(crossTable[, 1:5]))
使用函数添加的另外一种方式
addmargins(prop.table(mytable, 1), 2) # 加在列
addmargins(prop.table(mytable, 2), 1) # 加在行
RStudio table描述性统计,频数,频率,总和,百分比 - 知乎 (zhihu.com)
cbind函数给列命名
Set Column Names when Using cbind Function in R | Rename Variables (statisticsglobe.com)
scatterplots
R - Scatterplots (tutorialspoint.com)
piechart
R Tutorials (tutorialkart.com)
How to draw Pie Chart in R programming language (tutorialkart.com)
barplot 显示问题
graph - How to display all x labels in R barplot? - Stack Overflow
关于warning问题
带中文字符 R 语言经常会发出警告
options(warn=-1) #忽视任何警告
options(warn=1) #不放过任何警告
options(digits = 2) #将有效输出变为2
prop.table()
How to Use prop.table() Function in R (With Examples) - Statology
prop table in R: How Does the prop.table()
变量分组的三种方法
完整代码
alicepolice/R01_Pelican (github.com)
R语言、02 案例2-1 Pelican商店、《商务与经济统计》案例题的更多相关文章
- 分类算法的R语言实现案例
最近在读<R语言与网站分析>,书中对分类.聚类算法的讲解通俗易懂,和数据挖掘理论一起看的话,有很好的参照效果. 然而,这么好的讲解,作者居然没提供对应的数据集.手痒之余,我自己动手整理了一 ...
- 92、R语言分析案例
1.读取数据 > bank=read.table("bank-full.csv",header=TRUE,sep=";") > 2.查看数据结构 & ...
- R语言︱贝叶斯网络语言实现及与朴素贝叶斯区别(笔记)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 一.贝叶斯网络与朴素贝叶斯的区别 朴素贝叶斯的 ...
- R语言︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
XGBoost不仅仅可以用来做分类还可以做时间序列方面的预测,而且已经有人做的很好,可以见最后的案例. 应用一:XGBoost用来做预测 ------------------------------- ...
- R语言︱线性混合模型理论与案例探究(固定效应&随机效应)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 线性混合模型与普通的线性模型不同的地方是除了有 ...
- R语言:recommenderlab包的总结与应用案例
R语言:recommenderlab包的总结与应用案例 1. 推荐系统:recommenderlab包整体思路 recommenderlab包提供了一个可以用评分数据和0-1数据来发展和测试推荐算 ...
- R语言编程艺术#02#矩阵(matrix)和数组(array)
矩阵(matrix)是一种特殊的向量,包含两个附加的属性:行数和列数.所以矩阵也是和向量一样,有模式(数据类型)的概念.(但反过来,向量却不能看作是只有一列或一行的矩阵. 数组(array)是R里更一 ...
- 机器学习实用案例解析(1) 使用R语言
简介 统计学一直在研究如何从数据中得到可解释的东西,而机器学习则关注如何将数据变成一些实用的东西.对两者做出如下对比更有助于理解“机器学习”这个术语:机器学习研究的内容是教给计算机一些知识,再让计算机 ...
- R语言解读多元线性回归模型
转载:http://blog.fens.me/r-multi-linear-regression/ 前言 本文接上一篇R语言解读一元线性回归模型.在许多生活和工作的实际问题中,影响因变量的因素可能不止 ...
随机推荐
- Eslint 项目笔记
1.代码下一行不要验证报错 代码的上一行打上注释 <--eslint-disable-next-line-->
- NOI / 1.4编程基础之逻辑表达式与条件分支讲解-02:输出绝对值
02:输出绝对值 总时间限制: 1000ms 内存限制: 65536kB 题目: 描述 输入一个浮点数,输出这个浮点数的绝对值. 输入 输入一个浮点数,其绝对值不超过10000. 输出 输出这个浮点数 ...
- python jinjia2 使用语法
简介 对于jinjia2来说,模板仅仅是文本文件,可以生成任何基于文本的文件格式,例如HTML.XML.CSV.LaTex 等等,以下是基础的模板内容: <!DOCTYPE html> & ...
- BACnet MS/TP转MQTT网关金鸽BL103
BACnet MS/TP转MQTT网关金鸽BL103BL103是一款BACnet路由器,实现 BACnet MS/TP 总线和以太网 BACnetIP 之间通信路由功能,同时也是一款Modbus RT ...
- LeetCode题解-20.有效的括号
题目 给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效. 有效字符串需满足: 左括号必须用相同类型的右括号闭合. 左括号必须以正确的顺序闭合. 示例 ...
- PLC中增益和偏移
y=kx+b这个直线方程,那么增益就是指k这个斜率,而偏移就是指b. 模拟量转换时一般是不需要设置这两个参数的,只有当外部信号与模块接收的信号在值上有偏差的情况下才会去调整这个参数. 如果的模块信号是 ...
- Rider调试ASP.NET Core时报thread not gc-safe的解决方法
新建了一个ASP.NET Core 5.0的Web API项目,当使用断点调试Host.CreateDefaultBuilder(args)时,进入该函数后查看中间变量的值,报错Evaluatio ...
- Linux 06 用户组管理
参考源 https://www.bilibili.com/video/BV187411y7hF?spm_id_from=333.999.0.0 版本 本文章基于 CentOS 7.6 概述 每个用户都 ...
- Spring源码 01 概述
参考源 https://www.bilibili.com/video/BV1tR4y1F75R?spm_id_from=333.337.search-card.all.click https://ww ...
- TDM 三部曲 (与 Deep Retrieval)
推荐系统的主要目的是从海量物品库中高效检索用户最感兴趣的物品,既然是"海量",意味着用户基本不可能浏览完所有的物品,所以才需要推荐系统来辅助用户高效获取感兴趣的信息.同样也正是因为 ...