【BOOK】Ajax数据爬取
Requests获取原始HTML文档,Ajax加载和JavaScript处理的数据无法获得
一、Ajax
Ajax—异步的JavaScript和XML
Ajax请求页面更新:
1、 发送请求
2、 解析内容
3、 渲染网页
JavaScript向服务器发送了一个Ajax请求
二、Ajax分析方法
查看Ajax请求
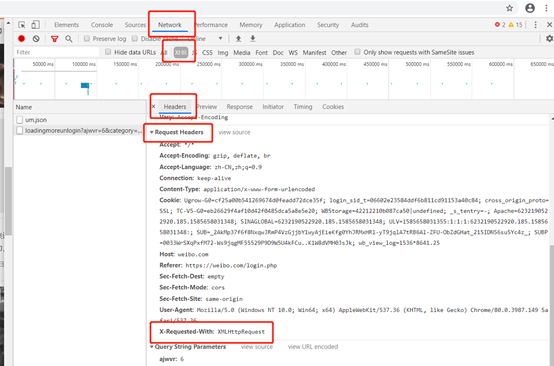
微博(未登录):https://weibo.com/login.php
下图为Ajax加载的过程

※Chrome浏览器—右键—检查—Network—刷新页面—XHR(筛选出Ajax请求)—Request Headers-- X-Requested-With: XMLHttpRequest(标记Ajax请求)
※Preview选项:可以看到响应的内容,JSON格式
※Response选项:返回的数据
三、 Ajax结果提取
用Python模拟Ajax请求
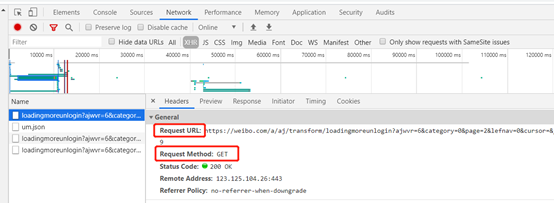
1、 分析请求
GET类型
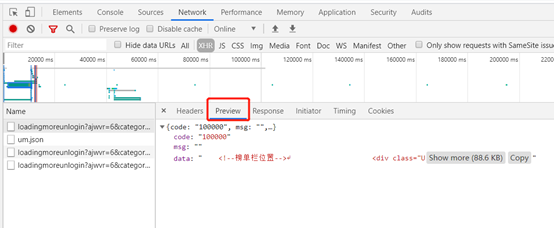
2、 分析响应
Preview:请求的响应内容(JSON格式)
四、 实例【分析Ajax爬取今日头条街拍美图】
1、 确定为Ajax渲染
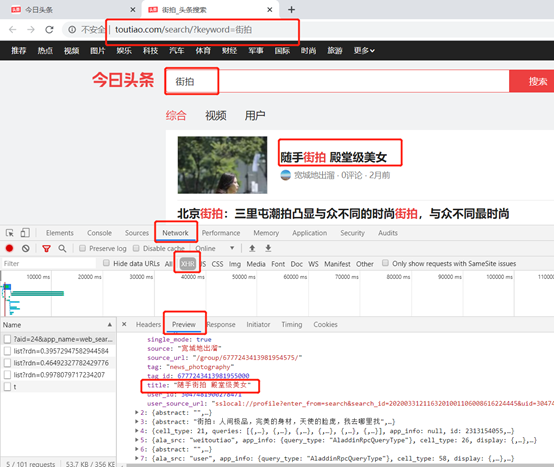
2、 爬取图片分析:data—image_list是图片的列表
用Python模拟Ajax请求,提取图片链接并下载
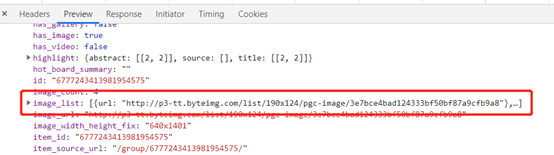
3、 分析URL
下滑,加载,查看多个Ajax请求的URL,发现规律
只有offset参数每次增加20,控制分页
4、实现
## Ajax
## 分析Ajax爬取今日头条街拍美图
## https://www.toutiao.com/search/?keyword=街拍 import requests
from urllib.parse import urlencode
import os
from hashlib import md5
from multiprocessing.pool import Pool
import re ## get_page(offset)加载单个Ajax请求的结果
def get_page(offset):
## https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1585660596769&_signature=wUHhuAAgEBAHFlg1-6xHd8FAoKAAJ.MtGLLCexBTF5ih1sbSlwZ6e6O7mqf0TYciKVg6zRGWz5yYRSmYSappEBMXSgxH6j9KQ1s8n4Qe3bCaaCn8.WylEGW8dlfapG8Y460
## 根据Ajax请求的url构造GET参数
params = {
'aid':'24',
'app_name':'web_search',
'offset':offset,
'format':'json',
'keyword':'动漫',
'autoload':'true',
'count':'20',
'en_qc':'1',
'cur_tab':'1',
'from':'search_tab',
'pd':'synthesis'
}
# urlencode()构造请求的GET参数
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params)
headers = {
'cookie': 'tt_webid=6810359770231817736; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6810359770231817736; ttcid=0f11652ca96f4a1a8249ea9bdbeb09f966; SLARDAR_WEB_ID=09143091-be35-48e5-92cf-4b7becffd8e2; csrftoken=b991c8d1b8be5a8d3cf5d728b03eb114; s_v_web_id=verify_k8julwio_iBgoIo8r_pGRP_4qox_AXgR_SvNnatEkPaJK; tt_scid=ePFuQLeJD7KoPt53REkDvgczszTB-q1riJi0iZFd3tjgLyXBkW5z2FVlX8RWhzvadc7b',
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"
}
try:
response = requests.get(url, headers=headers, timeout=30)
if response.status_code == 200:
return response.json()
except :
print('爬取失败!') ## 提取标题和图片
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_list')
if images:
for image in images:
## 构造生成器
yield {
'image':image.get('url'),
'title':title
} ## 保存图片
## item是get_images()返回的一个字典
def save_image(item):
## 根据 item 的 title 来创建文件
title = re.sub('[/:*?"<>|\\\]', '', item.get('title'))
if not os.path.exists(title):
os.mkdir(title)
try:
## 请求图片链接
response = requests.get(item.get('image'))
file_path = '{0}/{1}.{2}'.format(title, md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
## 将图片以二进制格式写入文件
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('已经下载', file_path)
except:
print('图片保存失败!') def main(offset):
json = get_page(offset)
if get_images(json):
for item in get_images(json):
print(item)
save_image(item) ## 分页的起始页和终止页数
GROUP_START = 1
GROUP_END = 20 ## pool多线程池
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END+1)])
## map()实现多线程下载
pool.map(main, groups)
pool.close()
pool.join()
运行结果:
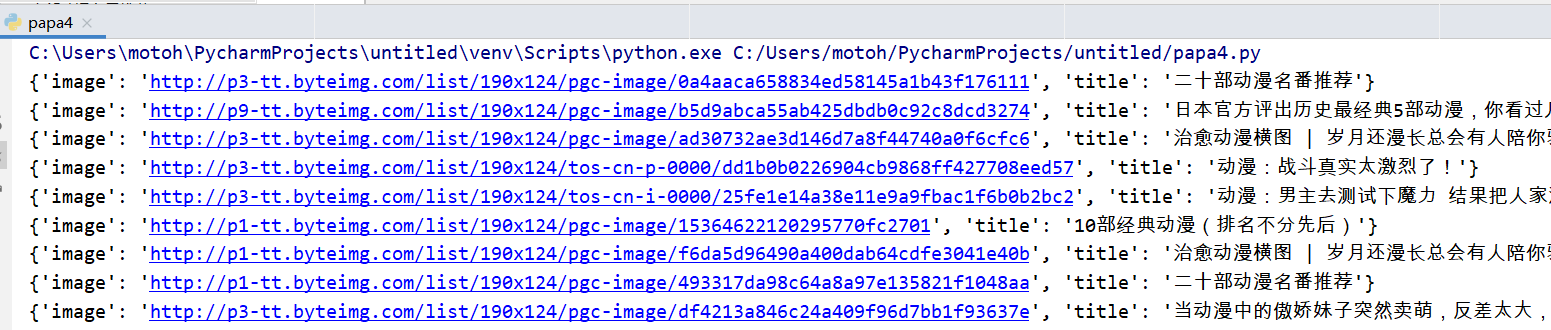

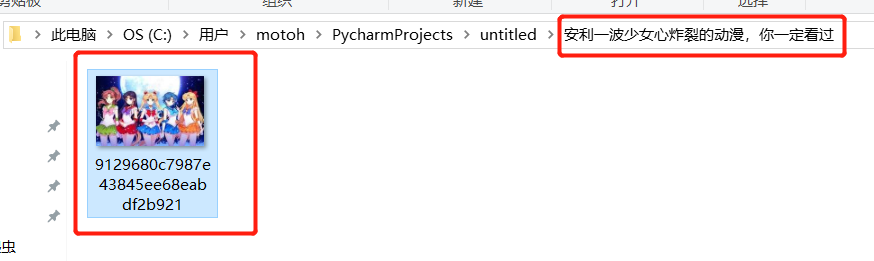
两个报错点!!
1、TypeError:‘NoneType’ object is not iterable(类型错误:'NoneType’对象不是可迭代的)
迭代对象的值可能是None,无法迭代,需要在迭代之前进行判断!!
## 加 if 判断,若 get_images(json) 不为 None 就进行遍历
if get_images(json):
for item in get_images(json):
print(item)
save_image(item)
2、OSError: [Errno 22] 文件名、目录名或卷标语法不正确。: '最近刚完结的一部高分动漫,你有看过吗?'
爬取的标题直接作为文件夹名,可能会包含一些文件名不能包含的字符,需要把这些字符去掉
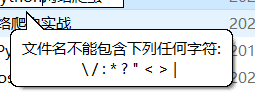
import re s = '最近:刚/完\结***的一部高|||分动???漫,你有看过吗?'
title = re.sub('[/:*?"<>|\\\]', '', s)
print(title) ## 最近刚完结的一部高分动漫,你有看过吗
【BOOK】Ajax数据爬取的更多相关文章
- Ajax数据爬取
Ajax的基本原理 以菜鸟教程的代码为例: XMLHTTPRequest对象是JS对Ajax的底层实现: var xmlhttp; if (window.XMLHttpRequest) { // IE ...
- 第十四节:Web爬虫之Ajax数据爬取
有时候在爬取数据的时候我们需要手动向上滑一下,网页才加载一定量的数据,但是网页的url并没有发生变化,这时我们就要考虑使用ajax进行数据爬取了...
- 爬虫—Ajax数据爬取
一.什么是Ajax 有时候我们使用浏览器查看页面正常显示的数据与使用requests抓取页面得到的数据不一致,这是因为requests获取的是原始的HTML文档,而浏览器中的页面是经过JavaScri ...
- Ajax数据爬取--爬取微博
Ajax Ajax,即异步的JaveScript和XML.它不是一门编程语言,而是利用JaveScript在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术. 对于传统的网 ...
- python-day7爬虫基础之Ajax数据爬取
前几天一直在忙老师的项目,就没有继续学python,也没有写什么收获,今天晚上有空看看书,边看边理解着写吧: 首先说一下,我对Ajax的理解,就是有时候我们在浏览某个网页的时候,只要我们鼠标一直往下滑 ...
- 第7章 Ajax数据爬取
Ajax 简介 Ajax 分析方法 Ajax 结果提取
- 爬虫(十):AJAX、爬取AJAX数据
1. AJAX 1.1 什么是AJAX AJAX即“Asynchronous JavaScript And XML”(异步JavaScript和XML)可以使网页实现异步更新,就是不重新加载整个网页的 ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
- 爬虫1.5-ajax数据爬取
目录 爬虫-ajax数据爬取 1. ajax数据 2. selenium+chromedriver知识准备 3. selenium+chromedriver实战拉勾网爬虫代码 爬虫-ajax数据爬取 ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
随机推荐
- .NET Core基础:白话管道中间件
在Asp.Net Core中,管道往往伴随着请求一起出现.客户端发起Http请求,服务端去响应这个请求,之间的过程都在管道内进行. 举一个生活中比较常见的例子:旅游景区. 我们都知道,有些景区大门离景 ...
- ssh远程执行命令无法使用awk的问题
ssh执行远程命令,当使用到awk的时候总是报错,而sed和grep都没有问题 awk不支持远程执行.最近经过测试找到了解决此问题的方法. 举例:ssh 目标IP " awk '{print ...
- PHY6230 高性价比低功耗高性能 集成32-bit MCU BLE5.2+2.4G芯片
PHY6230 是一款高性价比低功耗高性能Bluetooth LE 5.2系统级芯片,集成32-bit高性能低功耗MCU,16KB OTP,8KB Retention SRAM和64KB ROM,可选 ...
- QTcpSocket 设置接收数据延时等待时间
/* 客户端接入槽函数 */ void TcpServer::slotNewConnect(void) {/* 获取连接的客户端句柄 这里设置刷新数据时间 1ms */ QTcpSocket *pSo ...
- 3DMAX安装失败怎么办?安装3DMAX失败提示错误怎么解决?
3DMAX安装失败怎么办?安装3DMAX失败提示错误怎么解决?有很多同学想把3DMAX卸载后重新安装,但是发现3DMAX安装到一半就失败了或者显示3DMAX已安装或者安装未完成,大多数情况下其实是3D ...
- 检测到远端rexec服务正在运行中
0.系统 AIX7 1.先备份 /etc/inetd.conf文件 2.vi /etc/inetd.conf vi /etc/inetd.conf ##给原来的行加上注释# # exec .... / ...
- 【未完】【DDR系列文章收集】
资料来源 1.https://zhuanlan.zhihu.com/p/343262874 (1)主要讲DRAM刷新的内容: 为什么需要刷新(漏电流导致电容电荷的流失)? 刷新的本质(对存储数据的电容 ...
- HttpClient常用的一些常识
HttpClient是目前我们通讯组件中最常见的一个Api了吧.至少从我目前接触到与外部系统通讯的话是这样的.下面我将我自己常用的一些知识总结一下. 因为本猿也是边写边总结,有啥不对的还望多多指出. ...
- IIS添加MIME类型实现未知文件下载
application/octet-stream 无需重启
- C# DateTime转换为字符串
12小时制:DateTime.Now.ToString("yyyy-MM-dd hh:mm:ss") 24小时制:DateTime.Now.ToString("yyyy- ...