Hadoop集群简单入门
Hadoop集群搭建
自己配置Hadoop的话太过复杂了,因为自己着急学习,就使用了黑马的快照。如果小伙伴们也想的话可以直接看黑马的课程,快照的话关注黑马程序员公众号,输入Hadoop就能获取资料,到时候直接看课程P9就可以了。
Hadoop集群启停命令和Web UI
手动逐个启停
优点:准确的启动或关闭进程,避免群起群停。
缺点:多个进程同时操作麻烦
shell脚本一键启停
前提:配置好SSH免密登录和workers文件。
HDFS集群:start-dfs.sh/stop-dfs.sh
YARN集群:start-yarn.sh/stop-yarn.sh
Hadoop集群:start-all.sh/start-all.sh
启停结果查看
1. jps命令查看进程
2. 或者在下载路径下logs文件查看
启动结果:
node1: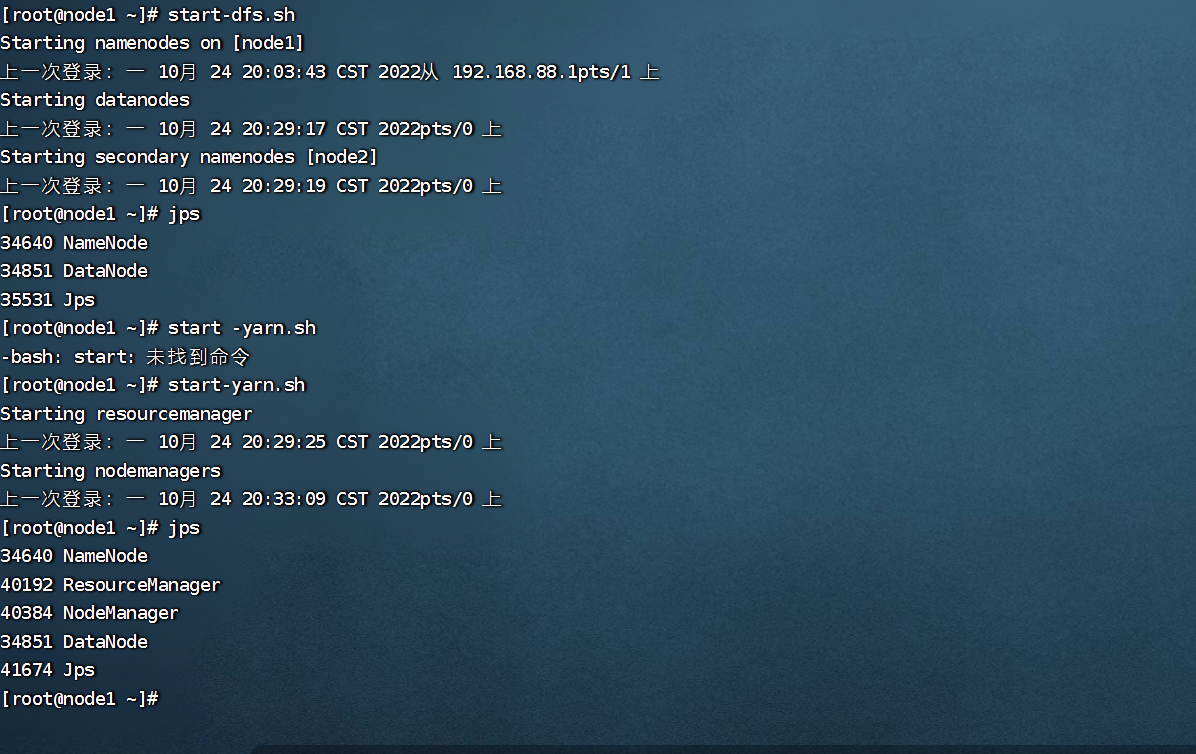
node2: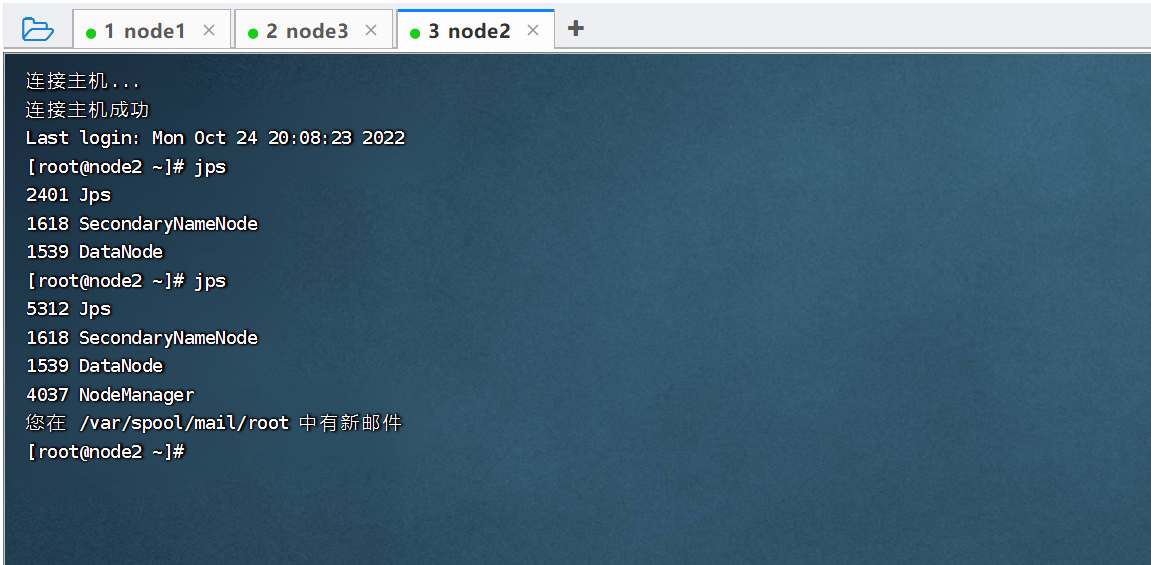
4. Web UI
HDFS Web界面:NameNode所在机器,端口是9870
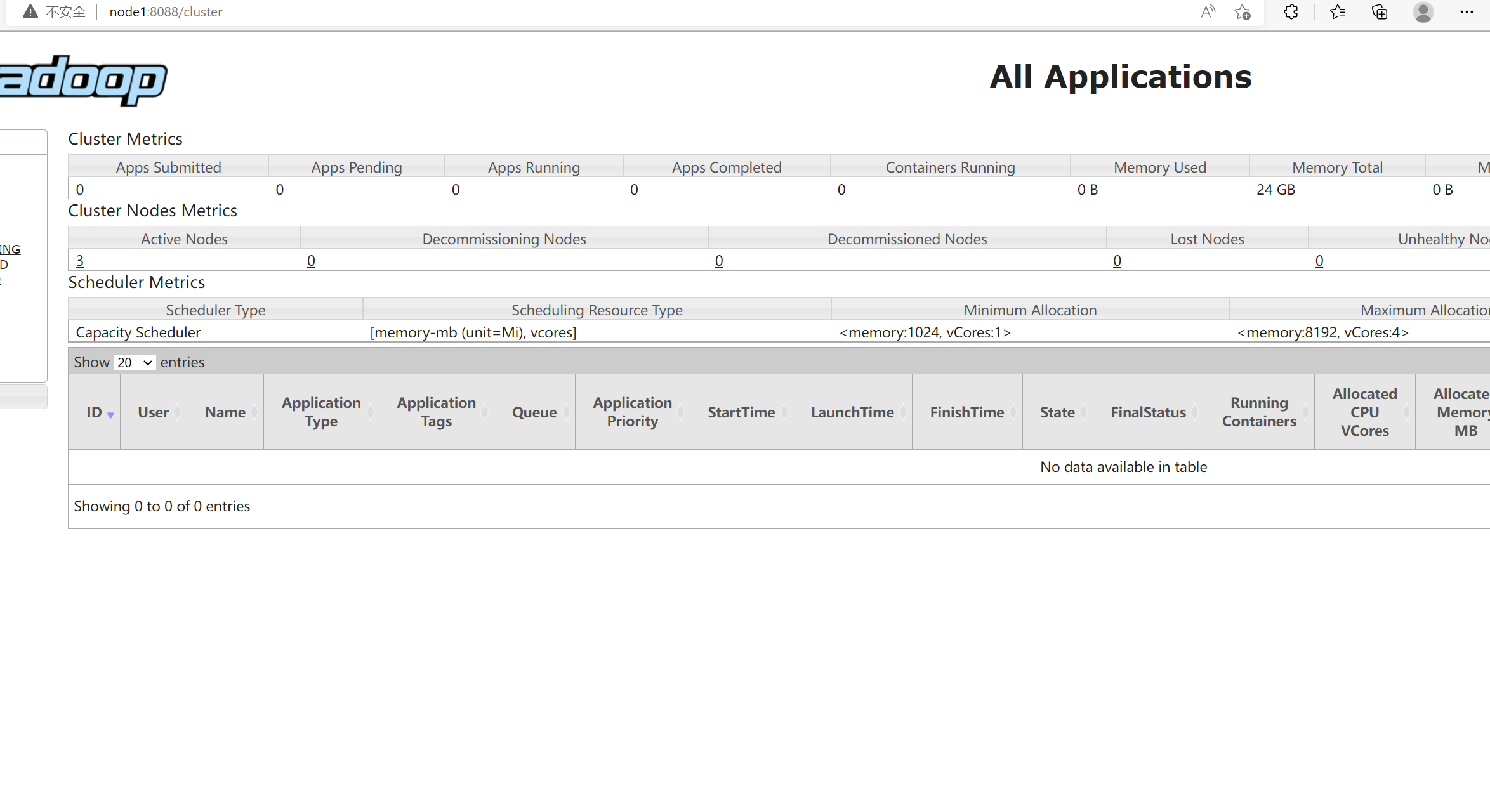
YARN Web界面:ResourceManager所在机器,端口号是8088
结果如下:
HDFS:
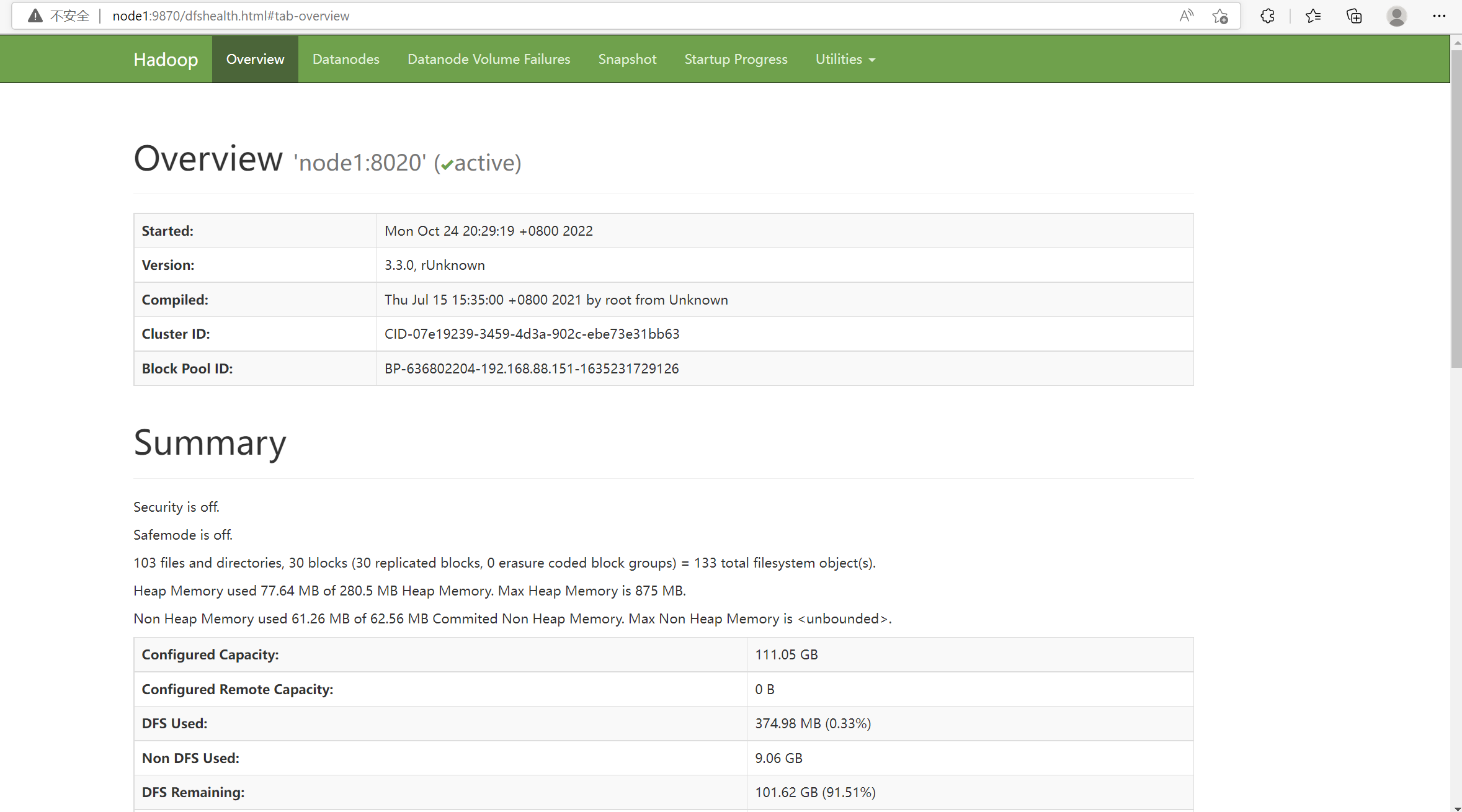
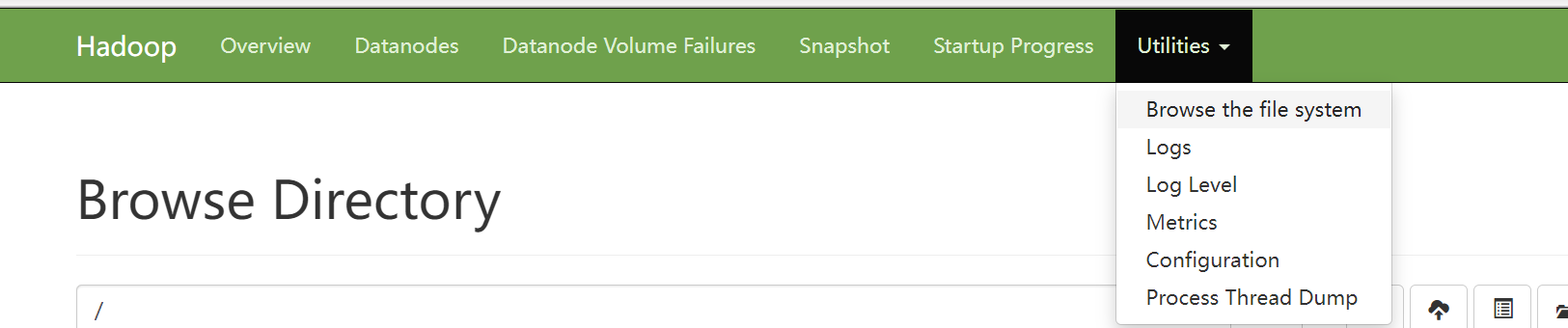
其中在这个界面,我们主要是浏览文件系统,即下图:
YARN:
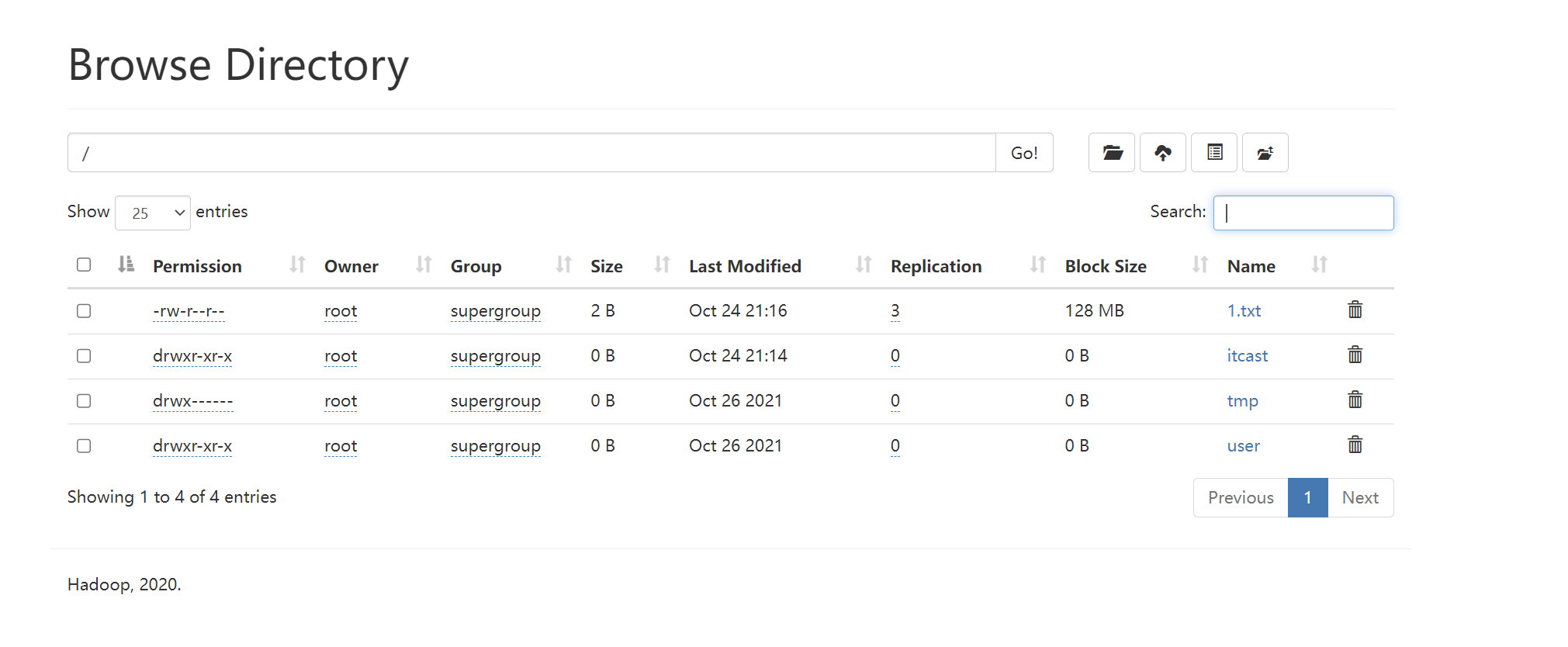
HDFS初体验
[root@node1 ~]# hadoop fs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /itcast
drwx------ - root supergroup 0 2021-10-26 15:20 /tmp
drwxr-xr-x - root supergroup 0 2021-10-26 15:23 /user
[root@node1 ~]# hadoop fs -mkdir itcast
[root@node1 ~]# hadoop fs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2021-10-26 15:04 /itcast
drwx------ - root supergroup 0 2021-10-26 15:20 /tmp
drwxr-xr-x - root supergroup 0 2021-10-26 15:23 /user
[root@node1 ~]# hadoop fs -put anaconda-ks.cfg /itcast
[root@node1 ~]# echo 1 > 1.txt
[root@node1 ~]# ll
总用量 32
-rw-r--r-- 1 root root 2 10月 24 21:15 1.txt
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
drwxr-xr-x 2 root root 55 10月 5 00:08 hivedata
-rw------- 1 root root 23341 10月 5 00:11 nohup.out
[root@node1 ~]# hadoop fs -put 1.txt /
运行结果:
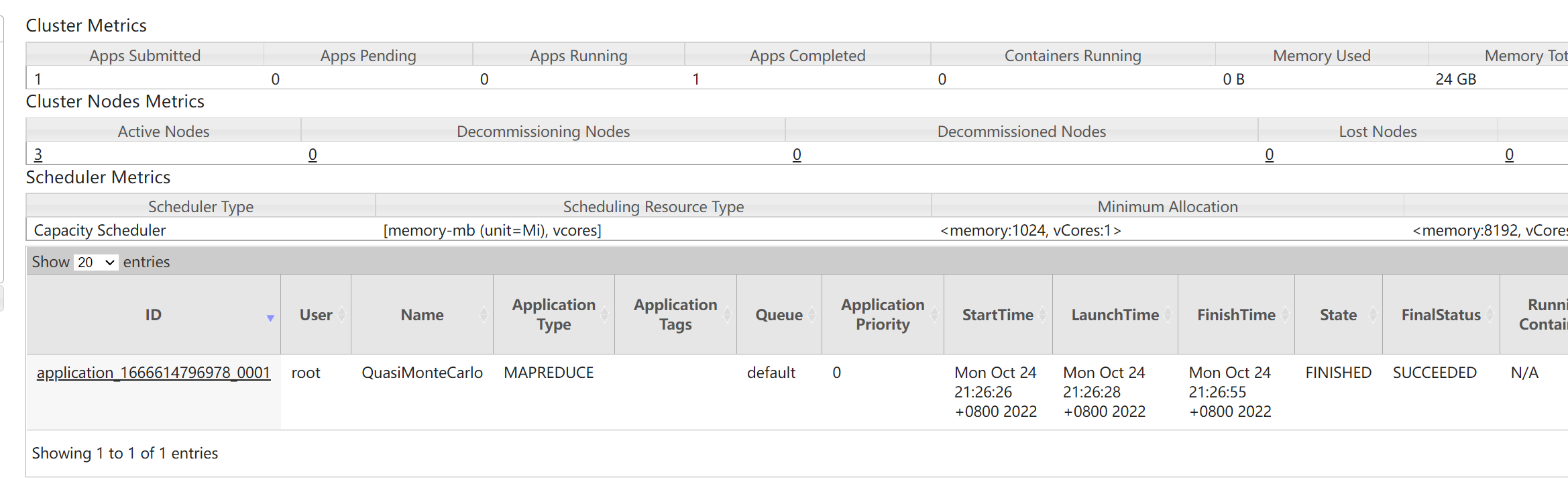
MapReduce+YARN初体验
[root@node1 ~]# cd /export/server/hadoop-3.3.0/
[root@node1 hadoop-3.3.0]# ll
总用量 88
drwxr-xr-x 2 root root 203 7月 15 2021 bin
drwxr-xr-x 3 root root 20 7月 15 2021 etc
drwxr-xr-x 2 root root 106 7月 15 2021 include
drwxr-xr-x 3 root root 20 7月 15 2021 lib
drwxr-xr-x 4 root root 288 7月 15 2021 libexec
-rw-rw-r-- 1 root root 22976 7月 5 2020 LICENSE-binary
drwxr-xr-x 2 root root 4096 7月 15 2021 licenses-binary
-rw-rw-r-- 1 root users 15697 3月 25 2020 LICENSE.txt
drwxr-xr-x 3 root root 4096 10月 24 20:33 logs
-rw-rw-r-- 1 root users 27570 3月 25 2020 NOTICE-binary
-rw-rw-r-- 1 root users 1541 3月 25 2020 NOTICE.txt
-rw-rw-r-- 1 root users 175 3月 25 2020 README.txt
drwxr-xr-x 3 root root 4096 7月 15 2021 sbin
drwxr-xr-x 3 root root 20 7月 15 2021 share
[root@node1 hadoop-3.3.0]# cd share/hadoop/
[root@node1 hadoop]# ll
总用量 12
drwxr-xr-x 2 root root 123 7月 15 2021 client
drwxr-xr-x 6 root root 217 7月 15 2021 common
drwxr-xr-x 6 root root 4096 7月 15 2021 hdfs
drwxr-xr-x 5 root root 4096 7月 15 2021 mapreduce
drwxr-xr-x 7 root root 87 7月 15 2021 tools
drwxr-xr-x 8 root root 4096 7月 15 2021 yarn
[root@node1 hadoop]# cd mapreduce/
[root@node1 mapreduce]# ll
总用量 5276
-rw-r--r-- 1 root root 589704 7月 15 2021 hadoop-mapreduce-client-app-3.3.0.jar
-rw-r--r-- 1 root root 803842 7月 15 2021 hadoop-mapreduce-client-common-3.3.0.jar
-rw-r--r-- 1 root root 1623803 7月 15 2021 hadoop-mapreduce-client-core-3.3.0.jar
-rw-r--r-- 1 root root 181995 7月 15 2021 hadoop-mapreduce-client-hs-3.3.0.jar
-rw-r--r-- 1 root root 10323 7月 15 2021 hadoop-mapreduce-client-hs-plugins-3.3.0.jar
-rw-r--r-- 1 root root 50701 7月 15 2021 hadoop-mapreduce-client-jobclient-3.3.0.jar
-rw-r--r-- 1 root root 1651503 7月 15 2021 hadoop-mapreduce-client-jobclient-3.3.0-tests.jar
-rw-r--r-- 1 root root 91017 7月 15 2021 hadoop-mapreduce-client-nativetask-3.3.0.jar
-rw-r--r-- 1 root root 62310 7月 15 2021 hadoop-mapreduce-client-shuffle-3.3.0.jar
-rw-r--r-- 1 root root 22637 7月 15 2021 hadoop-mapreduce-client-uploader-3.3.0.jar
-rw-r--r-- 1 root root 281197 7月 15 2021 hadoop-mapreduce-examples-3.3.0.jar
drwxr-xr-x 2 root root 4096 7月 15 2021 jdiff
drwxr-xr-x 2 root root 30 7月 15 2021 lib-examples
drwxr-xr-x 2 root root 4096 7月 15 2021 sources
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
Number of Maps = 2
Samples per Map = 2
Wrote input for Map #0
Wrote input for Map #1
Starting Job
2022-10-24 21:26:25,174 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.151:8032
2022-10-24 21:26:25,982 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1666614796978_0001
2022-10-24 21:26:26,237 INFO input.FileInputFormat: Total input files to process : 2
2022-10-24 21:26:26,308 INFO mapreduce.JobSubmitter: number of splits:2
2022-10-24 21:26:26,492 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1666614796978_0001
2022-10-24 21:26:26,492 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-10-24 21:26:26,687 INFO conf.Configuration: resource-types.xml not found
2022-10-24 21:26:26,688 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-10-24 21:26:27,169 INFO impl.YarnClientImpl: Submitted application application_1666614796978_0001
2022-10-24 21:26:27,218 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1666614796978_0001/
2022-10-24 21:26:27,219 INFO mapreduce.Job: Running job: job_1666614796978_0001
2022-10-24 21:26:38,491 INFO mapreduce.Job: Job job_1666614796978_0001 running in uber mode : false
2022-10-24 21:26:38,492 INFO mapreduce.Job: map 0% reduce 0%
2022-10-24 21:26:48,699 INFO mapreduce.Job: map 100% reduce 0%
2022-10-24 21:26:56,768 INFO mapreduce.Job: map 100% reduce 100%
2022-10-24 21:26:56,777 INFO mapreduce.Job: Job job_1666614796978_0001 completed successfully
2022-10-24 21:26:56,877 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=795057
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=520
HDFS: Number of bytes written=215
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=13640
Total time spent by all reduces in occupied slots (ms)=5089
Total time spent by all map tasks (ms)=13640
Total time spent by all reduce tasks (ms)=5089
Total vcore-milliseconds taken by all map tasks=13640
Total vcore-milliseconds taken by all reduce tasks=5089
Total megabyte-milliseconds taken by all map tasks=13967360
Total megabyte-milliseconds taken by all reduce tasks=5211136
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=284
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=906
CPU time spent (ms)=5000
Physical memory (bytes) snapshot=793993216
Virtual memory (bytes) snapshot=8363589632
Total committed heap usage (bytes)=677380096
Peak Map Physical memory (bytes)=299003904
Peak Map Virtual memory (bytes)=2789269504
Peak Reduce Physical memory (bytes)=200515584
Peak Reduce Virtual memory (bytes)=2788036608
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 31.796 seconds
Estimated value of Pi is 4.00000000000000000000
运行结果:
Hadoop集群简单入门的更多相关文章
- hadoop集群简单搭建
分布式搭建 在ubuntu下创建hadoop用户组和用户 bigdata@master:~$sudo addgroup hadoop bigdata@master:~$sudo adduser --i ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- Hadoop入门进阶步步高(五)-搭建Hadoop集群
五.搭建Hadoop集群 上面的步骤,确认了单机能够运行Hadoop的伪分布运行,真正的分布式运行无非也就是多几台slave机器而已,配置方面的有一点点差别,配置起来就很easy了. 1.准备三台se ...
- Hadoop学习之路(四)Hadoop集群搭建和简单应用
概念了解 主从结构:在一个集群中,会有部分节点充当主服务器的角色,其他服务器都是从服务器的角色,当前这种架构模式叫做主从结构. 主从结构分类: 1.一主多从 2.多主多从 Hadoop中的HDFS和Y ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- 搭建简单的hadoop集群(译文)
本文翻译翻译自http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/ClusterSetup.html 具体的实 ...
- 简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作. 注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和 ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- Spark新手入门——2.Hadoop集群(伪分布模式)安装
主要包括以下三部分,本文为第二部分: 一. Scala环境准备 查看 二. Hadoop集群(伪分布模式)安装 三. Spark集群(standalone模式)安装 查看 Hadoop集群(伪分布模式 ...
随机推荐
- 用lambda表达式和std::function类模板改进泛型抽象工厂设计
- 成为 Apache 贡献者,So easy!
点击上方蓝字关注 Apache DolphinScheduler Apache DolphinScheduler(incubating),简称"DS", 中文名 "海豚调 ...
- Luogu2869 [USACO07DEC]美食的食草动物Gourmet Grazers (贪心,二分,数据结构优化)
贪心 考场上因无优化与卡常T掉的\(n \log(n)\) //#include <iostream> #include <cstdio> #include <cstri ...
- 使用二手 gopro 做行车记录仪
背景 自打开了博客以后,一直在写技术说明文,今天打算写点程序以外的东西换换味口.前段时间在某鱼上以 300 元的价格入手了一套完整的 gopro3+ 运动摄像头,带一张 32G SD 卡,两块备用电池 ...
- [跨数据库、微服务] FreeSql 分布式事务 TCC/Saga 编排重要性
前言 FreeSql 支持 MySql/SqlServer/PostgreSQL/Oracle/Sqlite/Firebird/达梦/Gbase/神通/人大金仓/翰高/Clickhouse/MsAcc ...
- Excel 单元格的相对引用和绝对引用
引用方式 单元格的地址由该单元格所在的行号和列标构成,一个引用代表工作表上的一个或者一组单元格,指明公式中数据所在的位置. 编号 消费记录 价格 1 乒乓球 1 2 火腿肠 2 3 乒乓球 1 4 羽 ...
- MySQL查询关键数据方法
MySQL查询关键数据方法 操作表的SQL语句补充 1.修改表名 alter table 表名 reame 新表名: 2.新增字段名 alter table 表名 add 字段名 字段类型(数字) 约 ...
- NSK DD马达 直驱电机 RS232通信连接
NSK DD马达 通信连接 通信测试平台 驱动器:NSK EDC系列 电机:NSK PS1006KN系列 电机线:UVW对应红白黑. 电源线:Main和Ctrl电路220V交流电供电即可. 测试软件: ...
- vue2和vue3的区别?
vue2和vue3的主要区别在于以下几点: 1.生命周期函数钩子不同 2.数据双向绑定原理不同 3.定义变量和方法不同 4.指令和插槽的使用不同 5.API类型不同 6.是否支持碎片 7.父子组件之间 ...
- 02_Django-路由配置-HTTP协议的请求和响应
02_Django-路由配置-HTTP协议的请求和响应 视频:https://www.bilibili.com/video/BV1vK4y1o7jH 博客:https://blog.csdn.net/ ...