ING国际银行基于Volcano的大数据分析平台应用实践
摘要:ING集团发表了《Efficient Scheduling Of High Performance Batch Computing For Analytics Workloads With Volcano - Krzysztof Adamski & Tinco Boekestijn, ING》主题演讲。
在KubeCon + CloudNativeCon North America,ING集团发表了《Efficient Scheduling Of High Performance Batch Computing For Analytics Workloads With Volcano - Krzysztof Adamski & Tinco Boekestijn, ING》主题演讲,重点介绍了云原生批量计算项目Volcano如何在数据管理平台中为大数据分析作业提供高性能调度工作。
详情参见:KubeCon + CloudNativeCon North America
ING背景介绍
ING集团(荷兰语:Internationale Nederlanden Groep),亦名荷兰国际集团,是一个国际金融服务私营企业,成立于1991年,由荷兰最大的保险公司Nationale-Nederlanden,与荷兰的第三大银行NMB PostBank Group合并而成。
ING集团的服务遍及全球40多个国家,核心业务是银行、保险及资产管理等。ING集团的全球职员大约56,000人,顾客5320万人,包括自然人、家庭,企业、政府及其他等,例如基金组织。务背
业务背景介绍
在银行行业有许多法规和限制,如:监管要求在全球范围内各不相同、数据孤岛-全局和本地限制、数据安全、合规创新等,想要快速引入新技术不是一件容易的事情,为此,ING布局符合自身产业的DAP平台(Data Analytics Platform),为全球50%的ING员工提供安全的、自助的端到端分析能力,帮助员工在数据平台之上构建并解决业务问题。
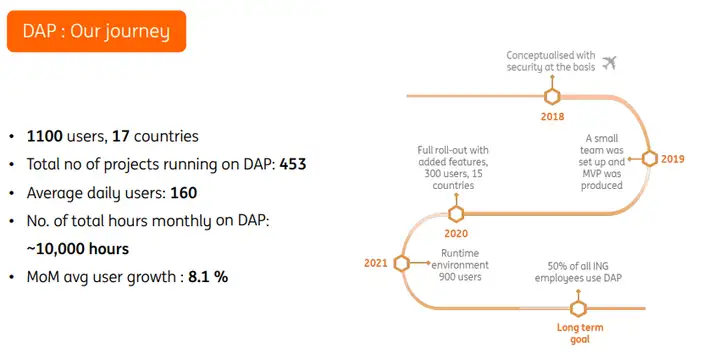
2013年开始我们有了数据平台的概念,2018年通过引入云原生技术打造新一代基础设施平台,从那时起,平台需求有了稳定的增长,采用率也在持续提升,目前数据索引平台上的项目已超过400个。我们所构建的平台目标是在高度安全的自助服务平台中完成所有分析需求,并且具备以下特点:
- 开源工具模型
- 强大的计算能力
- 严格的安全和合规措施
- 所有的分析集中在同一个平台
- 满足全球和本地需求
挑战与方案

目前我们在由传统的Hadoop平台向Kubernetes过渡,但是对于作业管理和多框架支持方面还存在一些挑战,如下:
1.Job的管理
a.Pod级调度,无法感知上层应用
b.缺乏细粒度的生命周期管理
c.缺乏任务依赖关系,作业依赖关系
2.调度
a.缺少基于作业的调度,如:排序、优先级、抢占、公平调度、资源预定等
b.缺少足够的高级调度算法,如:CPU拓扑、任务拓扑、IO-Awareness,回填等
c.缺少对作业、队列、命名空间之间资源共享机制的支持
3.多框架支持
a.对Tensorflow、Pytorch等框架的支持不足
b.对每个框架部署(资源规划、共享)等管理比较复杂
利用Kubernetes来管理应用服务(无状态应用、甚至是有状态应用)是非常方便的,但是对于批量计算任务的调度管理不如yarn友好,同样yarn也存在一些限制,比如对新框架的支持不够完善,比如TensorFlow、Pytorch等,为此,我们也在寻找新的解决方案。
▍Kubernetes + Hadoop
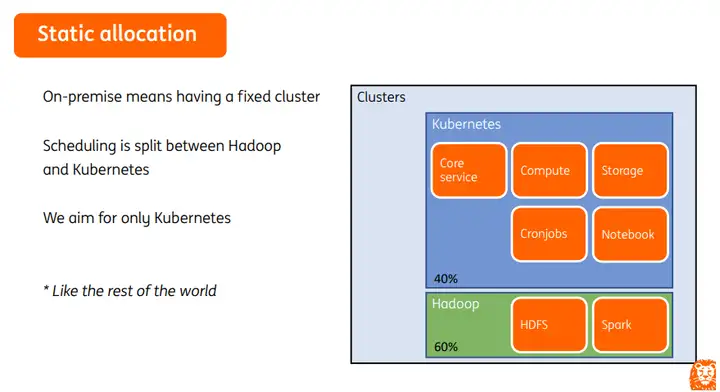
在我们之前的集群管理上,会把Hadoop和Kubernetes的调度分开,基本上所有的spark作业都会运行在Hadoop集群中,其他的一些任务和算法会运行在Kubernetes集群,我们的目标是希望所有的任务全部运行在Kubernetes集群,这样管理起来会更简单。
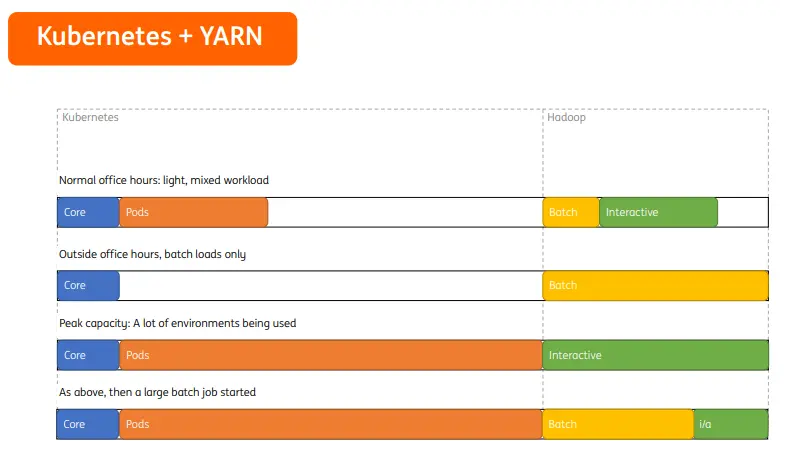
Kubernetes和YARN共同工作时,由于Kubernetes和Hadoop资源是静态划分的,在正常办公时间,Hadoop应用和Kubernetes各自使用自身分配资源,即便spark任务压力大也无法借用更多资源。夜晚时间,集群中仅有批处理任务,Kubernetes资源全部空闲,却无法分配给Hadoop进行有效利用,对于调度平台来讲,这不是一种最佳的资源分配方式。
▍Kubernetes with Volcano

使用Kubernetes管理整个集群,通过Volcano进行spark任务调度,此时不需要再对资源做静态划分,集群资源可根据Pod、Batch、Interactive任务的优先级、资源压力等进行动态调整,集群整体资源利用率得到极大提升。比如在正常办公时间内,常规服务应用资源空闲的情况下,Batch和Interactive应用资源需求增多时,可以暂时借用常规服务的资源;在假期和夜晚休息时,Batch业务可以使用集群所有资源进行数据计算,集群资源利用率得到极大提升。
比如在正常办公时间内,常规服务应用资源空闲的情况下,Batch和Interactive应用资源需求增多时,可以暂时借用常规服务的资源;在假期和夜晚休息时,Batch业务可以使用集群所有资源进行数据计算,集群资源利用率得到极大提升。

Volcano是专为Kubernetes而生的批处理调度引擎,其提供了以下能力:
- 加权优先级的作业队列
- 如果集群具有备用容量,可提交超过队列资源限制的任务
- 当更多的pod被调度时,具备抢占能力
- 丰富可配置的工作负载调度策略
- 兼容YARN的调度能力
Volcano的引入,补齐了Kubernetes平台对批处理作业的调度管理能力,并且自Apache Spark 3.3版本以来,Volcano被作为Spark on Kubernetes的默认batch调度器,安装使用更方便。
业务常用特性
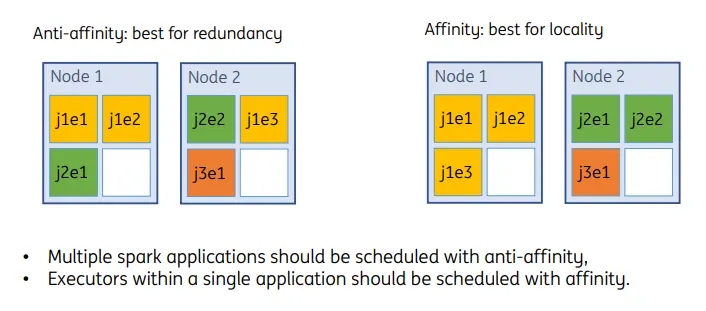
▍冗余与局部亲和
Volcano保留Kubernetes中pod级别的亲和性反亲和性策略配置,并增加了task级别的亲和性和反亲和性策略。
▍DRF(Dominant Resource Fairness)调度
DRF调度算法的全称是Dominant Resource Fairness,是基于容器组Domaint Resource的调度算法。volcano-scheduler观察每个Job请求的主导资源,并将其作为对集群资源使用的一种度量,根据Job的主导资源,计算Job的share值,在调度的过程中,具有较低share值的Job将具有更高的调度优先级。
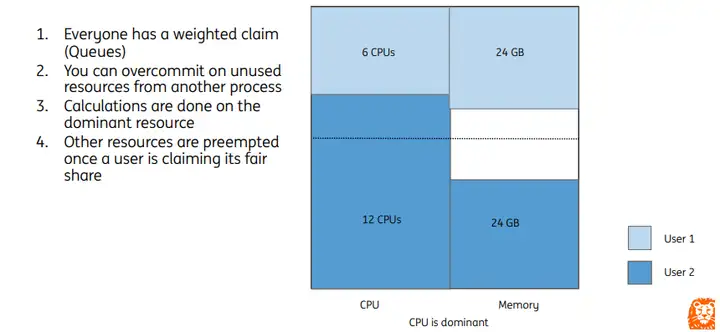
比如集群资源总量为CPU:18C,Memory:72GB,两个用户分别是User1和User2,每个User分配1个队列,在提交作业时会根据主导资源计算job的调度优先级。
- User1: CPU share值为 6/18=0.33,Memory share值为 24 / 72 = 0.33,最终share值为0.33
- User2:CPU share值为 12/18=0.67,Memory share值为 24 / 72 = 0.33,最终share值为0.67
DRF策略在任务调度时,优先分配share值较低的Job,即User1所申请的资源。
集群内队列资源可以通过配置权重值进行划分,但是当本队列提交任务超出队列分配的资源,并且其他队列存在资源空闲时,可以进行队列间资源共享。即User2在使用完本队列CPU资源后,可以使用User1队列内的空闲CPU资源。当User1队列提交新任务需要CPU资源时,将会触发抢占动作,回收User1被其他队列借用的资源。
▍避免资源匮乏
在使用过程中,需要避免批量计算任务与自有服务出现资源抢占与冲突的问题。比如:我们集群中有两个可用节点,集群中需要部署一个统一的服务层对外提供服务,比如Presto,或者类似Alluxio的缓存服务。但是在批量计算调度时,集群的资源空间有可能全部被占用,我们将无法完成自有服务的部署或升级,为此我们增加了空间可用系数相关配置,为集群预留一些备用空间,用于自有服务的部署使用。

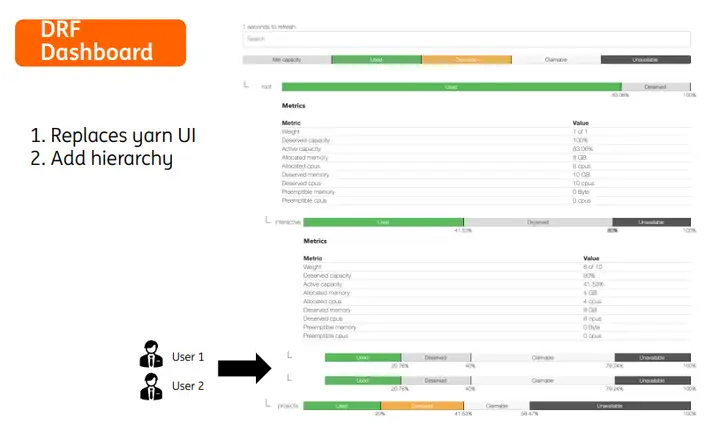
▍DRF 仪表盘
我们根据Volcano的监控数据做了一个drf调度的仪表盘,在不同层次显示更细粒度的调度信息。在业务集群中,我们有一个队列存放交互式用户的任务,另有队列存放平台运行的所有重大项目的计算任务,我们可以为重大项目队列提供一定的资源倾斜,但是此时对交互式用户的任务将不会太友好。
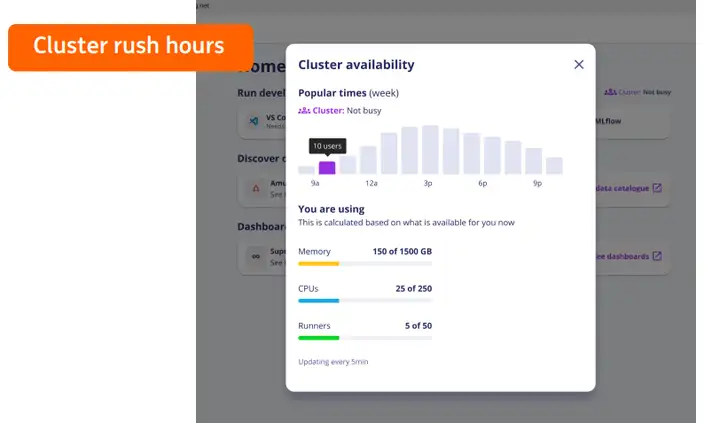
目前我们正在考虑增加集群高峰时段展示的功能,为用户提供更多的集群使用状态和压力等信息,在自助服务平台用户视角来看,用户按照集群的繁忙程度选择自己任务的开始时间,这样可以避免后台复杂的配置就可以获得高性能的运算体验。
总结
Volcano对批处理任务调度做了很好的抽象,使我们在Kubernetes平台能够获得更高的调度性能,后面我们也会将开发的功能逐步回合社区,比如:DRF Dashboard、在每个节点添加空闲空间、自动队列管理、更多的Prometheus监控指标、Grafana仪表盘更新、kube-state-metrics更新和集群角色限制等。
Volcano社区技术交流地址
Volcano官网:https://volcano.sh
GitHub : https://github.com/volcano-sh/volcano
每周例会: https://zoom.us/j/91804791393
ING国际银行基于Volcano的大数据分析平台应用实践的更多相关文章
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- 使用Kylin构建企业大数据分析平台的4种部署方式
本篇博客重点介绍如何使用Kylin来构建大数据分析平台.根据官网介绍,其实部署Kylin非常简单,称为非侵入式安装,也就是不需要去修改已有的 Hadoop大数据平台.你只需要根据的环境下载适合的Kyl ...
- Net Core SignalR 测试,可以用于unity、Layair、白鹭引擎、大数据分析平台等高可用消息实时通信器。
SignalR介绍 SignalR介绍来源于微软文档,不过多解释.https://docs.microsoft.com/zh-cn/aspnet/core/signalr/introduction?v ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- Apache Kylin大数据分析平台的演进
转:http://mt.sohu.com/20160628/n456602429.shtml 我是来自Kyligence的李扬,是上海Kyligence的联合创始人兼CTO.今天我主要来和大家分享一下 ...
- DKH大数据分析平台解决方案优势说明
大数据技术的发展与应用已经在深刻地改变和影响我们的日常生活与工作,可以预见的是在大数据提升为国家战略层面后,未来的几年里大数据技术将会被更多的行业应用. 相信很多人对于大数据技术的应用还是处于一个非常 ...
- Clickhouse 在大数据分析平台 - 留存分析上的应用
导语 | 本文实践了对于千万级别的用户,操作总数达万级别,每日几十亿操作流水的留存分析工具秒级别查询的数据构建方案.同时,除了留存分析,对于用户群分析,事件分析等也可以尝试用此方案来解决. 文章作者: ...
随机推荐
- Asp.Net Core MVC传值 Asp.Net Core API 前台写法
$("#Add_User").click(function () { var obj = { //"属性名": 传递的值, "User_Name&qu ...
- Java8新特性:函数式编程
1. 概述 函数式编程学习目的: 能够看懂公司里的代码 大数据量下处理集合效率更高 代码可读性高 消灭嵌套地狱 函数式编程思想: 面向对象思想需要关注用什么对象完成什么事情.而函数式编程思想就类似于我 ...
- Terminal(oh-my-zsh) 美化
如果你使用Mac进行开发,那么Terminal.app应该是你使用非常频繁的app了.初体验Terminal时你可能觉得单调乏味,阅读密密麻麻的内容也很费劲.但是如果你跟着我一起配置它,就会发现你平时 ...
- 某工控图片上传服务 CPU 爆高分析
一:背景 1.讲故事 今天给大家带来一个入门级的 CPU 爆高案例,前段时间有位朋友找到我,说他的程序间歇性的 CPU 爆高,不知道是啥情况,让我帮忙看下,既然找到我,那就用 WinDbg 看一下. ...
- 使用Jupyter记事本记录和制作.NET可视化笔记
前言:对于记录笔记的工具特别多,不过对于程序员来说,记录笔记+程序代码+运行结果演示可以同时存在,无疑会极大增加我们的笔记的可读性和体验感.以前在写python的时候,使用jupyter的体验很好,所 ...
- ctfshow web入门部分题目 (更新中)
CTFSHOW(WEB) web入门 给她 1 参考文档 https://blog.csdn.net/weixin_51412071/article/details/124270277 查看链接 sq ...
- 周立功DTU+温度传感器,ZWS物联网平台尝试
1.前言 了解到周立功有相关的物联网云平台,近期在调研动态环境监控项目,可以进行一个上云的尝试.购置了传感器.周立功的DTU等硬件,将传感器的温度.湿度等数据进行一个云平台的上传. 2.前期准备 传感 ...
- 靶机练习: Vikings
靶机:Vikings 准备工作 靶机地址: https://download.vulnhub.com/vikings/Vikings.ova MD5 校验:84f72c38e2458e01d00db9 ...
- 【大数据面试】【数仓项目】分层:ODS层、DWD层、DWS层、ADS层构成、操作
一.ODS层 1.保持数据原貌,不做任何修改 2.数据压缩:LZO压缩,减少磁盘空间 3.创建的是分区表:可以防止后续的全表扫描 包括 用户行为:string line dt ods_start ...
- SQL注入问题/触发器trigger/事务/事物隔离
SQL注入问题 本质:利用特殊符号的组合产生特殊的含义,从而避开正常的业务逻辑 select * from userinfo where name='jason' -- kasdjksajd' and ...