论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要
神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的。在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上取得最大的准确率。
在 CIFAR-10数据集上,基于本文提出的方法生成的模型在测试集上得到结果优于目前人类设计的所有模型。测试集误差率为3.65%,比之前使用相似结构的最先进的模型结构还有低0.09%,速度快1.05倍。
在 Penn Treebank数据集上,根据本文算法得到的模型能够生成一个新颖的 recurrent cell,其要比广泛使用的 LSTM cell或者其他基线方法表现更好。在 Penn Treebank测试集上取得62.4的perplexity,比之前的最好方法还有优秀3.6perplexity。这个 recurrent cell也可以转移到PTB的字符语言建模任务中,实现1.214的perplexity。
1.介绍
深度神经网络在许多具有挑战性的任务重都取得了不俗的成绩。在这成绩背后涉及到的技术则是从特征设计迁移到的结构设计,例如从SIFT、HOG(特征设计)到AlexNet、VGGNet、GoogleNet、ResNet等(结构设计)。
各种优秀的网络结构使得多种任务处理起来简单不少,但是设计网络结构仍然需要大量的专业知识并且需要耗费大量时间。
为了解决上述问题,本文提出 Neural Architecture Search,以期望找到合适的网络结构。大致原理图如下:
RNN作为一个 controller去生成模型的描述符,然后根据描述符得到模型,进而得到该模型在数据集上的准确度。接着将该准确度作为 奖励信号(reward signal)对controller进行更新。如此不断迭代找到合适的网络结构。

2.相关工作
超参数优化在机器学习中是个重要的研究话题,也被广泛使用。但是,该方法很难去生成一个长度可变的参数配置,即灵活性不高。虽然 贝叶斯优化可以搜索得到非固定长度的结构,但是与本文提出方法相比在通用性和可变性上都稍逊一筹。
现代神经进化算法虽然可以很灵活的生成模型,但是在大规模数据上实用性不高。
program synthesis and inductive programming的思想是searching a program from examples,Neural Architecture Search与其有一些相似的地方。
与本文方法相关的方法还有 meta-learning、使用一个神经网络去学习用于其他网络的梯度下降更新(Andrychowicz et al., 2016)、以及 使用增强学习去找到用于其他网络的更新策略(Li & Malik, 2016)
3.方法
本节将从下面3个方面介绍所提出的方法:
1.介绍递归网络如何通过使用policy gradient method最大化生成框架的准确率
2.介绍几个改善方法,如skip connection(增加复杂度)、parameter server(加速训练)等
3.介绍如何生成递归
3.1 Generate Model Descriptions With A Controller Recurrent Neural Network
用于生成模型描述的RNN结构如下,所生成的超参数是一系列的 token。

在实验中,如果层数超过一定数量,生成模型就会被停止。这种情况下,或者在收敛时,所生成模型在测试集上得到的准确率会被记录下来。
3.2 Training With Reinforcement
RNN的参数用\(θ_c\)表示。controller所预测的一系列tokens记为一系列的actions,即\(a_{1:T}\),这些tokens是为了子网络(Child network)设计结构。子网络在验证集上得到的准确率用\(R\)表示,该准确率作为 reward signal,并且会用到增强学习来训练controller。
通过求解最大化reward找到最优的结构,reward表达式如下:
\]
因为奖励信号\(R\)是不可微分的,所以我们需要一个策略梯度方法来迭代更新\(θ_c\)。在本文中,使用到来自 Williams (1992) 的增强学习规则:
\]
根据经验上式约等于:
\]
其中\(m\)是controller在一个batch中采样得到的结构的数量,\(T\)是controller用于预测和设计神经网络结构的超参数的数量。
\(R_k\)表示第k个网络结构在验证集上的准确度。
上述的更新算法是对梯度的无偏估计,但是有很高的方差。为了降低方差,文中使用如下基线函数:
\]
只要\(b\)不依懒于当前的action,那么其仍是无偏梯度估计,且\(b\)是前面的结构准确率的 指数平均数指标(Exponential Moving Average, EMA)
EMA(Exponential Moving Average)是指数平均数指标,它也是一种趋向类指标,指数平均数指标是以指数式递减加权的移动平均。
其公式为:
EMA_{today}=α * Price_{today} + ( 1 - α ) * EMA_{yesterday};其中,α为平滑指数,一般取作2/(N+1)。
Accelerate Training with Parallelism and Asynchronous Updates 使用并行算法和异步更新来加速训练
每一次用于更新controller的参数\(θ_c\)的梯度都对应于一个子网络训练达到收敛。但是因为子网络众多,且每次训练收敛耗时长,所以使用 分布式训练和异步参数更新的方法来加速controller的学习速度。

训练模型如上图所示,一共有\(S\)个 Parameter Server用于存储 \(K\)个 Controller Replica的共享参数。然后每个 Controller Replica 生成\(m\)个并行训练的自网络。
controller会根据\(m\)个子网络结构在收敛时得到的结果收集得到梯度值,然后为了更新所有 Controller Replica,会把梯度值传递给 Parameter Server。
在本文中,当训练迭代次数超过一定次数则认为子网络收敛。
3.3 Increase Architecture Complexity With Skip Connections And Other Layer Types
3.1节中的示意图为了方便说明,所以其中的网络结构较为简单。本节则会介绍一种方法能够使得controller生成的网络结构假如 skip connections(如ResNet结构) 或者 branching layers(层分叉,如GoogleNet结构)。
为实现准确预测connections,本文采用了 (Neelakantan et al., 2015) 中的基于注意力机制的set-selection type attention方法。
在\(N\)层,根据sigmoid函数判断与其前面的\(N-1\)个层是否相连。sigmoid函数如下:
\]
上式中\(h_j\)表示controller在第\(j\)层的隐藏状态(\(j\)的大小是从0到\(N-1\))。

下面介绍如何应对有的层可能没有输入或输出的情况:
1.如果没有输入,那么原始图像作为输入
2.在最后一层,将所有还没有connected层的输出concatenate起来作为输入。
3.如果需要concatenated的输入层有不同的size,那么小一点的层通过补0来保证一样大小
3.4 GENERATE RECURRENT CELL ARCHITECTURES
下图展示了生成递归单元结构的具体细节。
由图可知采用了树结构来描述网络结构,这样也便于遍历每个节点。
每棵树由两个叶子节点(用0,1表示)和一个中间节点(用2表示)组成。

4. 实验与结果
具体的实验结果可查阅原论文 NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING。
5.读后感
【The First Step-by-Step Guide for Implementing Neural Architecture Search with Reinforcement Learning Using TensorFlow】这篇文章很详细的给出了如何实现NASnet的方法以及源代码,通过阅读代码能更好地理解本论文的思路。
NAS在生成网络的时候之前需要固定网络的结构,或者是说需要固定网络的层数。
以生成CNN网络为例,代码中默认最大层数参数max_layers=2,当然也可以人为修改。
而controller其实就是一个RNN网络,其输出数据表示某一层中各个节点的参数,各个参数是按顺序输出的。例如代码中是按照 [cnn_filter_size,cnn_num_filters,max_pool_ksize,cnn_dropout_rates] 输出的(貌似并没有实现skip-connection)。
伪代码:
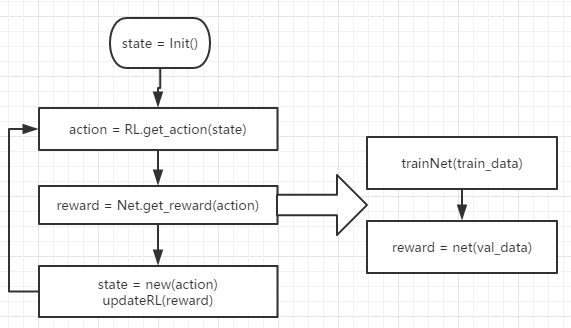
state = np.array([[10.0, 128.0, 1.0, 1.0]*max_layers], dtype=np.float32) # 初始化state
for episode in range(MAX_EPISODES):
action = RLnet.get_action(state) # 增强学习网络根据当前状态获取下一步的动作,其中是使用原论文所给的NAScell来对动作进行预测的。
reward, pre_accuracy = net_manager.get_reward(action) # 根据生成的动作得到对应的网络,然后将该网络在训练集上训练至收敛,再将收敛后的网络在验证集上运行得到准确度,根据一定的准则将准确度转化为reward。
reward = update(reward) # 更新reward
state = update(action) # 根据action更新state,在例子中是state=action[0]
从上面的伪代码可以看出每次采样得到的模型都需要在训练集上训练到收敛,然后再根据在验证集上得到的reward更新。所以NAS其本质是在离散搜索空间进行搜索,而且网络拓扑结构是固定的,并且训练时间较长,不过思路比较简单好懂。
论文笔记系列-Neural Architecture Search With Reinforcement Learning的更多相关文章
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记——NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
论文地址:https://arxiv.org/abs/1611.01578 1. 论文思想 强化学习,用一个RNN学一个网络参数的序列,然后将其转换成网络,然后训练,得到一个反馈,这个反馈作用于RNN ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...
- 告别炼丹,Google Brain提出强化学习助力Neural Architecture Search | ICLR2017
论文为Google Brain在16年推出的使用强化学习的Neural Architecture Search方法,该方法能够针对数据集搜索构建特定的网络,但需要800卡训练一个月时间.虽然论文的思路 ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (上)
之前已经发过一篇文章来介绍我写的AutoML综述,最近把文章内容做了更新,所以这篇稍微细致地介绍一下.由于篇幅有限,下面介绍的方法中涉及到的细节感兴趣的可以移步到论文中查看. 论文地址:https:/ ...
- (转)Illustrated: Efficient Neural Architecture Search ---Guide on macro and micro search strategies in ENAS
Illustrated: Efficient Neural Architecture Search --- Guide on macro and micro search strategies in ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
- 2017-ICLR-NAS_with_RL-Neural Architecture Search with Reinforcement Learning-论文阅读
NAS with RL 2017-ICLR-Neural Architecture Search with Reinforcement Learning Google Brain Quoc V . L ...
- 论文笔记系列-Simple And Efficient Architecture Search For Neural Networks
摘要 本文提出了一种新方法,可以基于简单的爬山过程自动搜索性能良好的CNN架构,该算法运算符应用网络态射,然后通过余弦退火进行短期优化运行. 令人惊讶的是,这种简单的方法产生了有竞争力的结果,尽管只需 ...
随机推荐
- BZOJ4828 AHOI/HNOI2017大佬(动态规划+bfs)
注意到怼大佬的操作至多只能进行两次.我们逐步简化问题. 首先令f[i][j]表示第i天结束后自信值为j时至多有多少天可以进行非防御操作(即恢复自信值之外的操作).这个dp非常显然.由于最终只需要保证存 ...
- Minimum Cost POJ - 2516(模板题。。没啥好说的。。)
题意: 从发货地到商家 送货 求送货花费的最小费用... 有m个发货地,,,n个商家,,每个商家所需要的物品和物品的个数都不一样,,,每个发货地有的物品和物品的个数也不一样,,, 从不同的发货地到不同 ...
- CUBA如何新增ServiceBean
简单的方法 在页面MIDDLEWARE模块,可以直接新建.编辑.删除 复杂的方法 在代码中手动实现,则需要1.添加Serviceweb-spring.xml中,添加 <entry key=&qu ...
- day11 高阶函数 函数式编程
高阶函数,满足 接收函数作为参数或者返回有函数 函数可以当做参数传递给另一个函数 def foo(n): print(n) def bar(name): print("my name is ...
- 【AtCoder010】A - Addition(奇偶)
AtCoder Grand Contest 010 A题 题目链接 题意 n个数,每次取两个奇偶性相同的数用他们的和代替他们,问最后能否只剩下一个数. 题解 因为奇偶相同的两个数之和一定是偶数,所以Y ...
- 【ARC063E】Integers on a tree
Description 给定一棵\(n\)个点的树,其中若干个点的权值已经给出.现在请为剩余点填入一个值,使得相邻两个点的差的绝对值恰好为1.请判断能否实现,如果能,请将方案一并输出. Solutio ...
- git 28原则
一.流程 $ git init # 创建一个新的仓库 sublime 编写文本,不要使用win自带文本编辑器 $ git add file1 # 将文件添加到暂存区 $ git add file2 $ ...
- bower介绍
一. bower是什么? bower是twitter推出的第三方依赖管理工具.其特点是对包结构没有强制规范,也因此bower本身并不提供一套构建工具,它充当的基本上是一个静态资源的共享平台.它可用于搜 ...
- HDU 3081 Marriage Match II (网络流,最大流,二分,并查集)
HDU 3081 Marriage Match II (网络流,最大流,二分,并查集) Description Presumably, you all have known the question ...
- ReactNative组件之scrollView实现轮播
想要实现轮播效果,首先安装时间定时器 接下来就是在我们的项目中使用定时器 接下来我们将竖着的轮播图变成横着的 接下来我们调整间距 我们知道轮播图下方,还有5个圆点,那我们怎么做呢? 拿到每一个圆点 看 ...