053 关于hive的存储格式
1.存储格式
textfile
rcfile
orc
parquet
2.存储方式
按行存储
-》textfile
按列存储
-》parquet
3.压缩比

4.存储textfile的原文件

并加载数据
5.大小
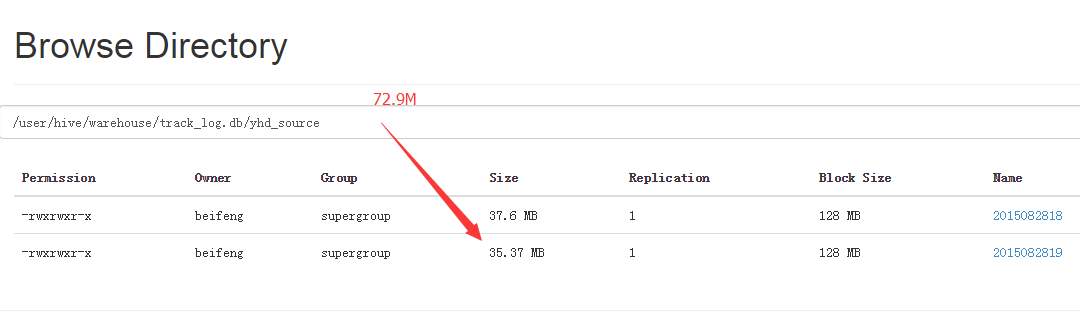
6.保存为textfile,经过mapreduce
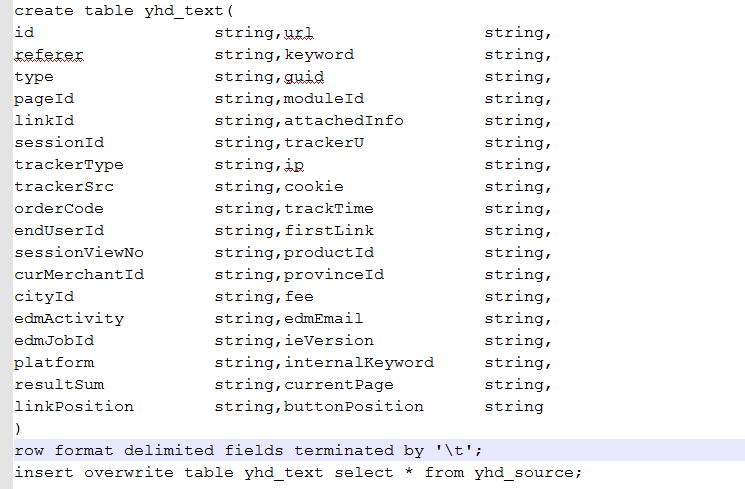
7.结果的大小
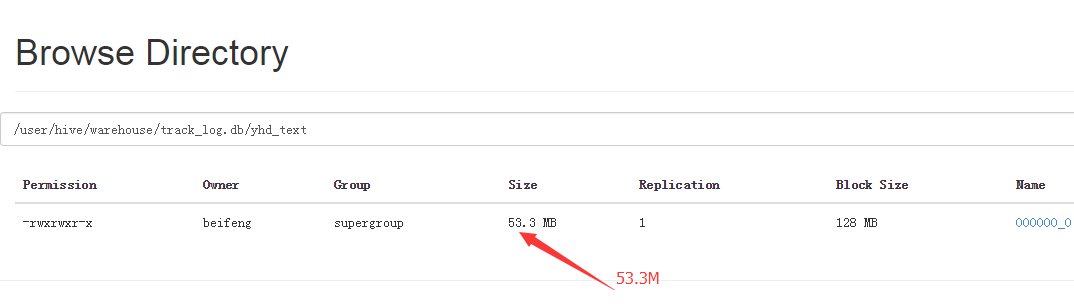
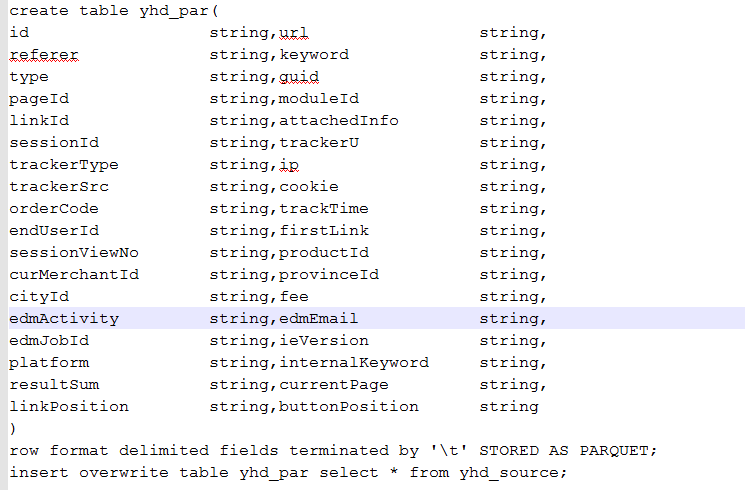
8.保存为orc格式
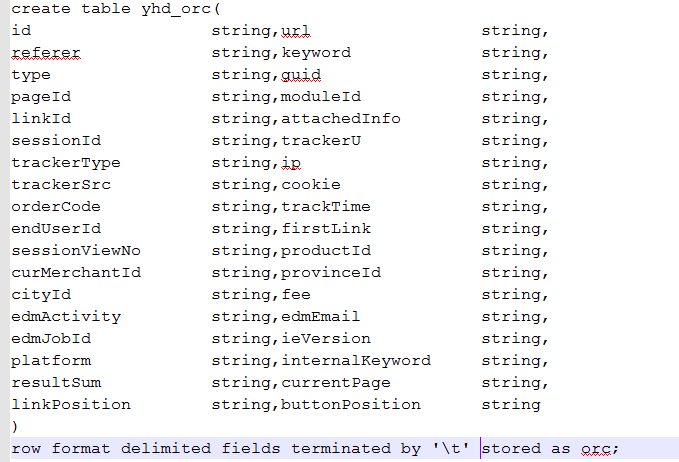
9.大小
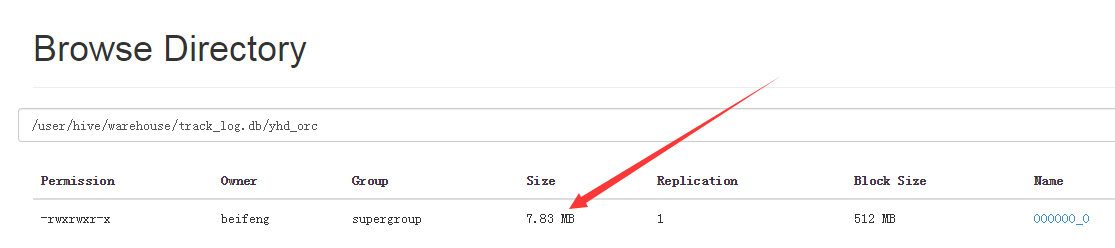
10.存储为parquet
11.大小
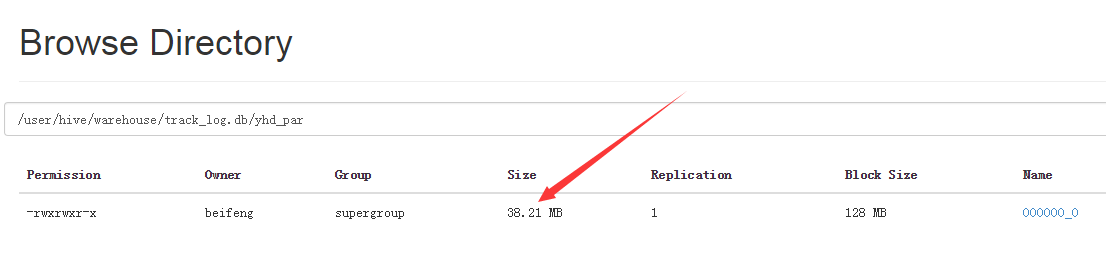
12.使用命令求大小
bin/hdfs dfs -du -s -h /user/hive/warehouse/track_log.db/yhd_par

053 关于hive的存储格式的更多相关文章
- Hive文件存储格式
hive文件存储格式 1.textfile textfile为默认格式 存储方式:行存储 磁盘开销大 数据解析开销大 压缩的text文件 hive无法进行合并和拆分 2.sequencef ...
- hive 压缩全解读(hive表存储格式以及外部表直接加载压缩格式数据);HADOOP存储数据压缩方案对比(LZO,gz,ORC)
数据做压缩和解压缩会增加CPU的开销,但可以最大程度的减少文件所需的磁盘空间和网络I/O的开销,所以最好对那些I/O密集型的作业使用数据压缩,cpu密集型,使用压缩反而会降低性能. 而hive中间结果 ...
- [Hive_add_9] Hive 的存储格式
0. 说明 Hive 的存储格式 | textfile | sequencefile | rcfile | orc | parquet | 1. Hive的存储格式 1.1 textfile 行式存储 ...
- Hive文件存储格式和hive数据压缩
一.存储格式行存储和列存储 二.Hive文件存储格式 三.创建语句和压缩 一.存储格式行存储和列存储 行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据. 列存储,以字段聚集存储,可以理解为 ...
- 关于hive的存储格式
1.存储格式 textfile rcfile orc parquet 2.存储方式 按行存储 ->textfile 按列存储 ->parquet 3.压缩比 4.存储textfile的原文 ...
- 【图解】Hive文件存储格式
摘自:https://blog.csdn.net/xueyao0201/article/details/79103973 引申阅读原理篇: 大数据:Hive - ORC 文件存储格式 大数据:Parq ...
- Hive文件的存储格式
hive文件存储格式包括以下几类: TEXTFILE SEQUENCEFILE RCFILE 自定义格式 其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到h ...
- hive常见的存储格式
Hive常见文件存储格式 背景:列式存储和行式存储 首先来看一下一张表的存储格式: 字段A 字段B 字段C A1 B1 C1 A2 B2 C2 A3 B3 C3 A4 B4 C4 A5 B5 C5 行 ...
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
随机推荐
- asp.net mvc Htmlhelper简单扩展
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- [HEOI2015]定价 (贪心)
分类讨论大法好! \(solution:\) 先说一下我对这个题目的态度: 首先这一题是贪心,这个十分明显,看了一眼其他题解都是十分优秀的贪心,可是大家都没有想过吗:你们贪心都是在区间\([l,r]\ ...
- 【vim】自动补全 Ctrl+n
Vim 默认有自动补全的功能.的确这个功能是很基本的,并且可以通过插件来增强,但它也很有帮助.方法很简单. Vim 尝试通过已经输入的单词来预测单词的结尾. 比如当你在同一个文件中第二次输入 &quo ...
- nodejs package.json解释
{ "name": "node-echo", # 包名,在NPM服务器上须要保持唯一 "version": "1.0.0" ...
- 无向图最小割Stoer-Wagner算法学习
无向连通网络,去掉一个边集可以使其变成两个连通分量则这个边集就是割集,最小割集当然就权和最小的割集. 使用最小切割最大流定理: 1.min=MAXINT,确定一个源点 2.枚举汇点 3.计算最大流,并 ...
- Day5----------------------文件合并与文件归档
一.文件合并 1.命令: >:覆盖式 >>:追加式 例如:cat /etc/passwd > a.txt 把/etc/passwd下的内容合并到a.txt内,若没有文 ...
- mysql 常用,使用经验
mysql default boolean字段 `enable` char(1) NOT NULL DEFAULT '1' COMMENT '启(禁)用',结果: this.enable ? &qu ...
- Java基础95 过滤器 Filter
1.filter 过滤器的概述 filter过滤器:是面向切面编程的一种实现策略,在不影响原来的程序流程的前提下,将一些业务逻辑切入流程中,在请求达到目标之前进行处理,一般用于编码过滤.权限过滤... ...
- SQL开发测试使用基础
目录 一.客户端配置与使用 1.oracle(PLSQL Developer) 2.hive(hive cli)及命令 3.postgre(pgAdmin) 二.注意事项及基础 ...
- js获取iframe中的元素
var obj=document.getElementById("iframe的name").contentWindow; var ifmObj=obj.document.getE ...