tensorflow学习5----变量管理
---恢复内容开始---
前面,读书笔记用加入正则化损失模型效果带来的提升要相对显著。
变量管理:
目的:当神经网络的结构更加复杂,参数更多的时候,就需要一个更好的方式来管理神经网络中的参数。
解决方法:提供了通过变量名称来创建或者获取一个变量的机制。
作用:在不同的函数可以通过变量的名字来使用变量。而不需要通过参数进行传递。
主要函数:
tf.variable_scope()
tf.get_variable()
tf.get_variable() #创建和获取变量。
#在创建变量时,tf.get_variable()和tf.Variable() 等价。 v=tf.get_variable(“v”,shape=[1],initializer=tf.constant_initializer(1.0)) v=tf.Variable(tf.constant(1.0,shape=[1]),name="v")
tf.get_variable()里面,name="v",shape=[1],initializer=tf.canstant_initializer(1.0)等变量初始化函数。
如:initializer=tf.truncated_normal_initializer(stddev=0.02) :将变量初始化为满足正态分布的随机值,如果随机出来的值偏离平均值超过两个标准差,那么重新随机------>主要参数为均值和标准差。 如这里的stddev就是标准差。
卷积神经网络:
相邻两层之间只有部分的节点相连,为了展示每一层神经元的维度,一般会把每一层卷积层的节点组织成一个三维矩阵。
全连接层的缺点:当参数过多,参数增加回=会导致计算的缓慢,也容易出现过拟合。
卷积神经网络的流程:
1.输入层:组织成一个三维矩阵,一般为输入层,三维矩阵的长和宽代表图像的大小,而三维矩阵的深度代表channel。
2.卷积层:卷积层的每一个节点的输入只是上一层神经网络的一小块,这个小块通常为3*3、5*5,卷积层试图将神经网络的每一块更加深入的分析而得到抽象程度更高的特征。
一般来说,卷积层处理后。节点矩阵的深度会增加。
3.池化层(pooling):池化层不会改变三维矩阵的深度,而是缩小矩阵的大小。池化操作可以认为将一张分辨率较高的图片。
卷积层:比较重要的是一个结构------>filter:可以将当前神经网络上的子节点矩阵转换为下一层神经网路上的一个单位节点矩阵,单位节点矩阵指的是长和宽都为1,但是深度不限的节点矩阵。
filter的长和宽是人为指定的,filter的尺寸通常为3*3或5*5,同时需要指定处理的得到的单位节点矩阵的深度。

标准的计算方程还是:f(x*w+b)----->只不过对
于卷积运算的话是channel个乘以对应的权重,最后add一个biases。
卷积神经网络的前向传播过程:
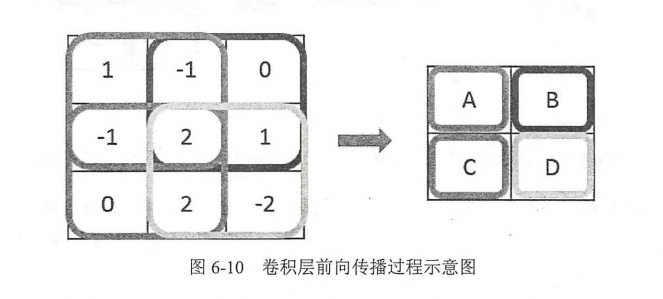
尺寸变化了,但是在当前矩阵的边界上加入全0填充后,可以保持前向传播的结果和当前层的矩阵保持一致。
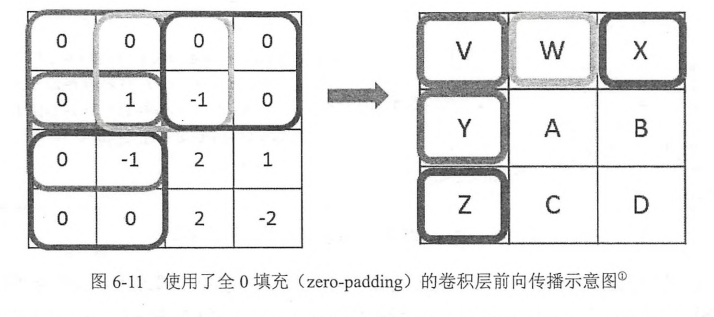
padding到0后,当前层神经网络的长和宽与filer的尺寸可以决定输出层矩阵的长和宽。


共享filter的参数,可以巨幅减少神经网络上的参数
卷积神经网路的code:
filter_weights=tf.get_variable('weights',shape=[5,5,3,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
#shpae的四维矩阵,前两个为filter的尺寸,第三个为当前层的深度,第四个为过滤器的深度,即得到的前向传播层的深度。
biases=tf.get_variable('biases',shape=[16],initializer=tf.constant_initializer(0.1))
#biases的声明,与前向传播的深度一致。
conv=tf.nn.conv2d(input,filter=filter_weights,strides=[1,1,1,1],padding='SAME')
#tf.nn.conv2d实现卷积层前向传播。
#注意这个input为一个四维的矩阵,第一维对应每个输入batch,
#input[0,:,:,:]表示第一张图片,input=images、
#第三个数组,stride,为四维,要求第一维和最后一维都必须为1。
#最后一维为填充的方法,padding method,提供了SAME和VALID两种选择。 SAME为全零填充,VALID为不添加。
bias=tf.nn.bias_add(conv,bisas)
#tf.nn_bias_add 每个节点加上bias
actived_conv=tf.nn.relu(bias)
#将计算的结果通过RELU激活函数去
池化(pooling)
目的(object):有效减少矩阵的尺寸。可以减小最后全连接层的参数的个数。同时。可以加快计算的速度,也有防止过拟合的作用。
步骤(procedure):也类似于过滤器的结构,只不过不是加权和而是采用更加简单的最大值和平均值。
包括(including):1.最大值 操作的池化层----->max pooling (using) 2.平均值操作的pooling, (average pooling)
参数设置:与convolution相似
区别:卷积层的过滤器横跨整个深度。而池化层的过滤器只影响一个深度上的节点。所以池化层的filter除了在长和宽的两个维度移动之外,还需要在深度这个维度进行移动。
注意:池化层的目的是减小矩阵的长和宽,一般不减小矩阵的深度。
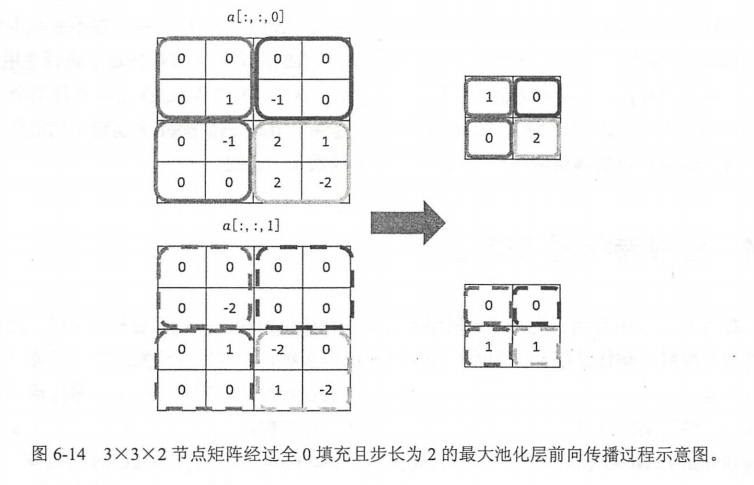
pool_code:
pool=tf.nn.max_pool(actived_conv,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
#tf.nn.max_pool实现最大池化层的前向传播过程。
#ksize提供了filter的尺寸,strides提供了步长的信息,padding提供是否zero_padding
#filter的尺寸,第一个和最后一个必须z1i用得最多的是[1,2,2,1]和[1,3,3,1]
#strides同样第一维和最后一维必须为1,
tf.nn.max_pool()最大池化层,tf.nn.avg_pool()平均池化层。
tensorflow学习5----变量管理的更多相关文章
- 83、Tensorflow中的变量管理
''' Created on Apr 21, 2017 @author: P0079482 ''' #如何通过tf.variable_scope函数来控制tf.ger_variable函数获取已经创建 ...
- Tensorflow学习教程------变量
#coding:utf-8 import tensorflow as tf x = tf.Variable([1,2]) a = tf.constant([3,3]) #增加一个减法op sub = ...
- TensorFlow学习笔记3——变量共享
因为最近在研究生成对抗网络GAN,在读别人的代码时发现了 with tf.variable_scope(self.name_scope_conv, reuse = reuse): 这样一条语句,查阅官 ...
- TensorFlow学习笔记4——变量共享
因为最近在研究生成对抗网络GAN,在读别人的代码时发现了 with tf.variable_scope(self.name_scope_conv, reuse = reuse): 这样一条语句,查阅官 ...
- tensorflow学习笔记二----------变量
tensorflow里面的变量表示,需要使用特定的语法进行.如果想构造一个行(列)向量,需要调用Variable函数进行.对两个变量进行操作,也要调用相应的函数. import tensorflow ...
- 【转载】TensorFlow学习笔记:共享变量
原文链接:http://jermmy.xyz/2017/08/25/2017-8-25-learn-tensorflow-shared-variables/ 本文是根据 TensorFlow 官方教程 ...
- TensorFlow学习笔记:共享变量
本文是根据 TensorFlow 官方教程翻译总结的学习笔记,主要介绍了在 TensorFlow 中如何共享参数变量. 教程中首先引入共享变量的应用场景,紧接着用一个例子介绍如何实现共享变量(主要涉及 ...
- TensorFlow学习笔记(三)MNIST数字识别问题
一.MNSIT数据处理 MNSIT是一个非常有名的手写体数字识别数据集.包含60000张训练图片,10000张测试图片.每张图片是28X28的数字. TonserFlow提供了一个类来处理 MNSIT ...
- tensorflow学习笔记——常见概念的整理
TensorFlow的名字中已经说明了它最重要的两个概念——Tensor和Flow.Tensor就是张量,张量这个概念在数学或者物理学中可以有不同的解释,但是这里我们不强调它本身的含义.在Tensor ...
随机推荐
- SSM(Spring+SpringMVC+Mybatis)框架环境搭建(整合步骤)(一)
1. 前言 最近在写毕设过程中,重新梳理了一遍SSM框架,特此记录一下. 附上源码:https://gitee.com/niceyoo/jeenotes-ssm 2. 概述 在写代码之前我们先了解一下 ...
- 要继续看Python写算法的内容请到那里去
由于在这里发文章的时候.莫名其妙的出现公布出去的问题.客服告知是由于链接或者敏感词. 能不能告诉我哪里出了问题?我能够改动,以便再发. 可是,没有人告诉我.仅仅是告诉我不能发. 另外,能不能公布一下敏 ...
- chmod a+r file:给所有用户添加读的权限
chmod a+r *:用户自己使用此命令,柯给所有用户添加可读的权限 超级用户给其他用户设置权限:sudo chmod a+rx /home/user 使所有人可以访问,读取文件,bu no W ...
- 014-通过JDB调试,通过HSDB来查看HotSpot VM的运行时数据
一.JDB调试 在预发环境下进行debug时,时常因为工具和环境的限制,导致debug体验非常差,那么有什么方法能够简化我们进行debug的体验吗?JDB就是一种. JDB ...
- 【LNMP】提示Nginx PHP “No input file specified”错误的解决办法
原理: 任何对.php文件的请求,都简单地交给php-cgi去处理,但没有验证该php文件是否存在. PHP文件不存在,没办法返回普通的404错误,它返回 一个404,并带上一句”No input f ...
- Linux下安装zookeeper集群(奇数个)
1. 解压zookeeper压缩包 2. data里创建“myid”文件(命令touch myid),内容是1(命令 echo 1 >> myid) 3. zoo.cnf里配置dat ...
- 【Tools】-NO.10.Tools.2.IDEA.1.001-【IDEA Configuration】-
1.0.0 Summary Tittle:[Tools]-NO.10.Tools.2.IDEA.1.001-[IDEA Configuration]- Style:Tools Series:IDEA ...
- mac-Navicat Premium 12连接Oracle
安装及破解: https://pan.baidu.com/s/1ip0oM9p856k34t3cIExa7Q(提取码请留言) Navicat连接了Oracle数据库 测试连接失败,提示:hostnam ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- python导入csv/txt文件
1. 导入csv文件 ### python导入csv文件的三种方法 ```python #原始的方式 lines = [line.split(',') for line in open('iris.c ...