机器学习基石(台湾大学 林轩田),Lecture 2: Learning to Answer Yes/No

上一节我们跟大家介绍了一个具体的机器学习的问题,以及它的内容的设定,我们今天要继续下去做什么呢?我们今天要教大家说到底我们怎么样可以有一个机器学习的演算法来解决我们上一次提到的,判断银行要不要给顾客信用卡的问题。

那么复习一下我们上一次上了什么?我们上一次说机器学习做的事情就是,有一个演算法我们叫做 A ,这个演算法会看两件事情:一件事情是资料,我们叫做 D ;另一件事情是 hypothesis set ,假说集合。我们要从这个假说集合,即 hypothesis set 里面选一个 g ,这个 g 会当作譬如银行最后使用的公式,等于是学到了一个技能。今天,我们就来讲讲到底机器怎么样决定要不要发信用卡这件事情,或者更广意的来说机器怎么解决这种是非的题目。就像我们考试的时候做是非题一样,我们今天要来学习的是,怎么样的机器学习演算法可以做是非题。
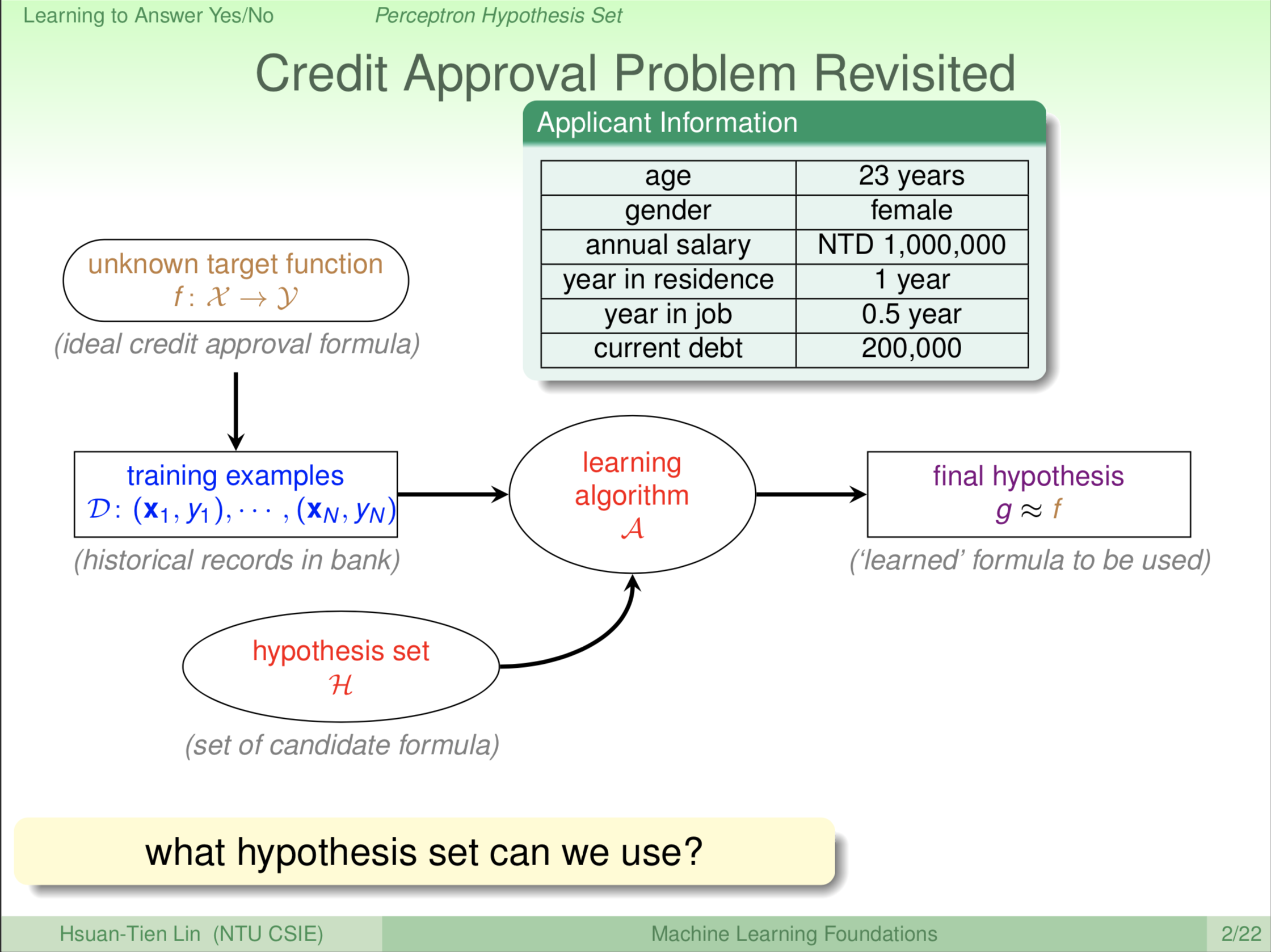
我们稍微复习一下,我们上一次整个机器学习的流程图是怎么样。我们说,我们是从资料出发。那么我们的一个假设是资料从哪里来的,资料从一个我们想学但我们不知道的这个公式,叫做 f 来的。我们有了资料以后,我们把这个资料喂给机器学习的演算法。这个演算法,帮助我们看这些资料,然后从所有的可能性,我们叫 H ,从所有 H 里面选一个 g 出来。我们希望 g 跟我们想要的 f 越接近越好。我们用这个信用卡的例子来做比喻说,今天有一个信用卡申请人申请信用卡,申请人信息我们用小写 x 表示,那它(机器)到底要给他信用卡还是不给他信用卡,我们用小写 y 来表示说要给还是不给。这是我们 Lecture 01 提到的机器学习的设定。那我们现在要学习什么呢?我们用学习和了解我们的大 H 到底长什么样子?上次我们只是泛泛的讲说,这些大 H 可供选择。今天,我们要跟大家介绍一个具体的大 H 的长相。
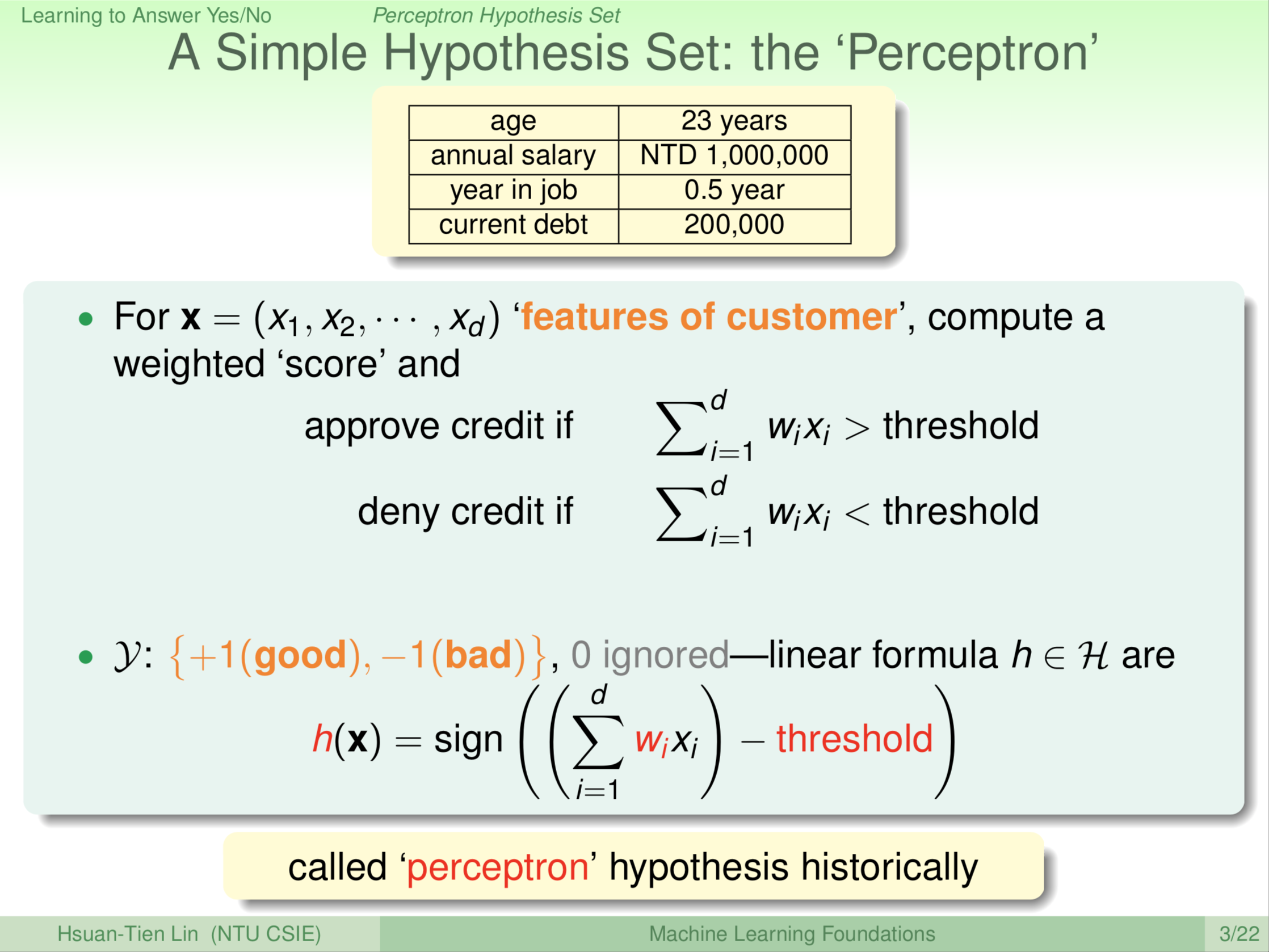
这边我们跟大家介绍一个模型。这个模型是说我们怎么样通过使用者(申请者)的资料评定要不要给他信用卡。我们可以把每一个使用者用一个向量来表示,每个使用者我们标记为 x ,我们可以把这个 x 想成一个向量,多个维度的向量。例如说,第一个维度可能是他的年纪,第二个维度可能是他的年薪,第三个维度可能是他工作有几年了,等等。每一个维度可能对我们有正面或负面的影响,决定我们要不要给他信用卡。那我们想做的事情是这样,我们把这些维度 \(x_1\) … \(x_d\) 综合的算一下,给申请者一个分数,如果这个分数超过了某个标准或者门槛(threshold),我们就决定说给申请者信用卡没问题。如果这个分数没有超过某个标准或者门槛,我们就说不要给申请者信用卡。这就有点像你在考试的时候,每道题目老师给你一个分数,把这些你满足参考解答的题目分数加起来,如果你超过60分,老师就说你及格了,给你过关好了;如果没有超过60分,就说你不及格不给你过关。有了这样的模型,每个维度我们用 \(x_i\) 来代表,然后乘以这个维度的重要性,如果今天这个维度对我们来说很重要,我们可能就多分配一点,说明该维度对我们来说是正相关;如果这个维度对我们来说是负相关的,例如说他欠的钱很多,那我们可能不要给他信用卡,此时,这里的 w 会是负的或者是较小的。总之,就是这些东西加起来,然后我们看他最后得几分。在这样的模型里,我们要做的事情是要电脑自动告诉我们说,要给信用卡,给信用卡是好的;还是不给信用卡,给信用卡是不好的。
我们当然可以用任意的数字或符号来表示好和坏,这里为了数学简单起见,我们用两个数字来代表好和不好。好的我们叫+1,不好的我们叫-1。这么做的好处是什么?这样表示的话,实际上我们发现一件事我们要电脑做决定,就是先计算出 \(\sum_{i=1}^d{\color{Red} {w_i}}x_i\) ,然后减去我们所设定的标准(门槛值)。如果 \(\sum_{i=1}^d{\color{Red} {w_i}}x_i - {\color{Red}{threshold}}\) 的结果为正数,我们就认为是好的;如果为负,我们就说是不好的。实际上就是取一些sign(符号),所以我们就可以很简洁的把使用者的资料拿来,通过 w 来做一个加权,然后取一个总分(求和),然后看看这个总分有没有超出我们的门槛值(求和与门槛值做差)。超出门槛值我们就 +1,没有超出我们就 -1。那如果刚好在门槛上面怎么样?通常这种事情很少发生,这种情况当作特例处理,我们暂且不去管它。事实上在我们未来讲的故事里面,大部分的时候在门槛值上的情形不是那么重要,或者我们遇到这种情况干脆就丢个铜板决定好了,反正有时候是对的,有时候是错的。注意我们这里用的是小 \({\color{Red}h}\),小 \({\color{Red}h}\) 是什么?小 \({\color{Red}h}\) 是我们可能的公式,这个小 \({\color{Red}h}\) 跟 \({\color{Red}w}\) 和我们选的门槛 \({\color{Red}{threshold}}\) 有关。所以,不同的 \({\color{Red}w}\),不同的 \({\color{Red}{threshold}}\),就造出不同的 \({\color{Red}h}\)。历史上我们把 perceptron 翻译叫做感知器,这个词的来源实际上是非常早期的类神经网络研究出来的。感知器就像我们人体里面的一个神经元的数学模型一样。所以综上,这是我们的一个 hypothesis,可以注意到 hypothesis 就是电脑最后会猜测这是不是一个可能的公式长相。\({\color{Red}h}\) 由 \({\color{Red}w}\) 和 \({\color{Red}{threshold}}\) 决定,\({\color{Red}w}\) 我们通常叫做 weigh,即权重,就是每一个维度的重要性。

\[{\color{Red} h}(\textbf x)=sign((\sum_{i=1}^d{\color{Red} {w_i}}x_i)-{\color{Red}{threshold}}) \tag{1}\]
每次这么写很麻烦,所以我们这里做一个符号上的简化,意思上没有太简化的地方。我们想要做什么呢?我们想要把这个门槛值 \({\color{Blue}{-threshold}}\),也当场一个特殊的 \({\color{Red}w}\),怎么处理呢?
\[{\color{Blue}{-threshold}} \Leftrightarrow +{\color{Blue}{(-threshold)*(+1)}}\]
\({\color{Blue}{-threshold}}\) 我们视为第0维 \({\color{Blue}{w_0}}\),常数 \({\color{Blue}{+1}}\) 视为 \({\color{Blue}{x_0}}\)
\({\color{Blue}{x}}\) 原来是一维到 d 维,现在我们加一个第0维。(1) 式就可以化简为:
\[{\color{Red} h}(\textbf x)=sign(\sum_{\color{Blue} {i=0}}^d{\color{Red} {w_i}}x_i)\]
\[\Rightarrow {\color{Red} h}(\textbf x)=sign({\color{Red} {\textbf w^{\textbf T}}} {\textbf x})\]
这样做了符号上的简化,我们就不用写一堆求和之类的符号和门槛值。我们现在的 x 就是顾客的资料,这个 x 是一个高高的向量,除了原来的的资料外还有第0维。w 也是一个高高的向量,它也有一个第0维,它的第0维 \({\color{Blue}{w_0}}\) 对应到我们原先想要的负的门槛值 \({\color{Blue}{-threshold}}\)。有了这些,我们就可以做一些数学上的操作。下面我们来看一个具体的 \({\color{Red} h}(\textbf x)\)。
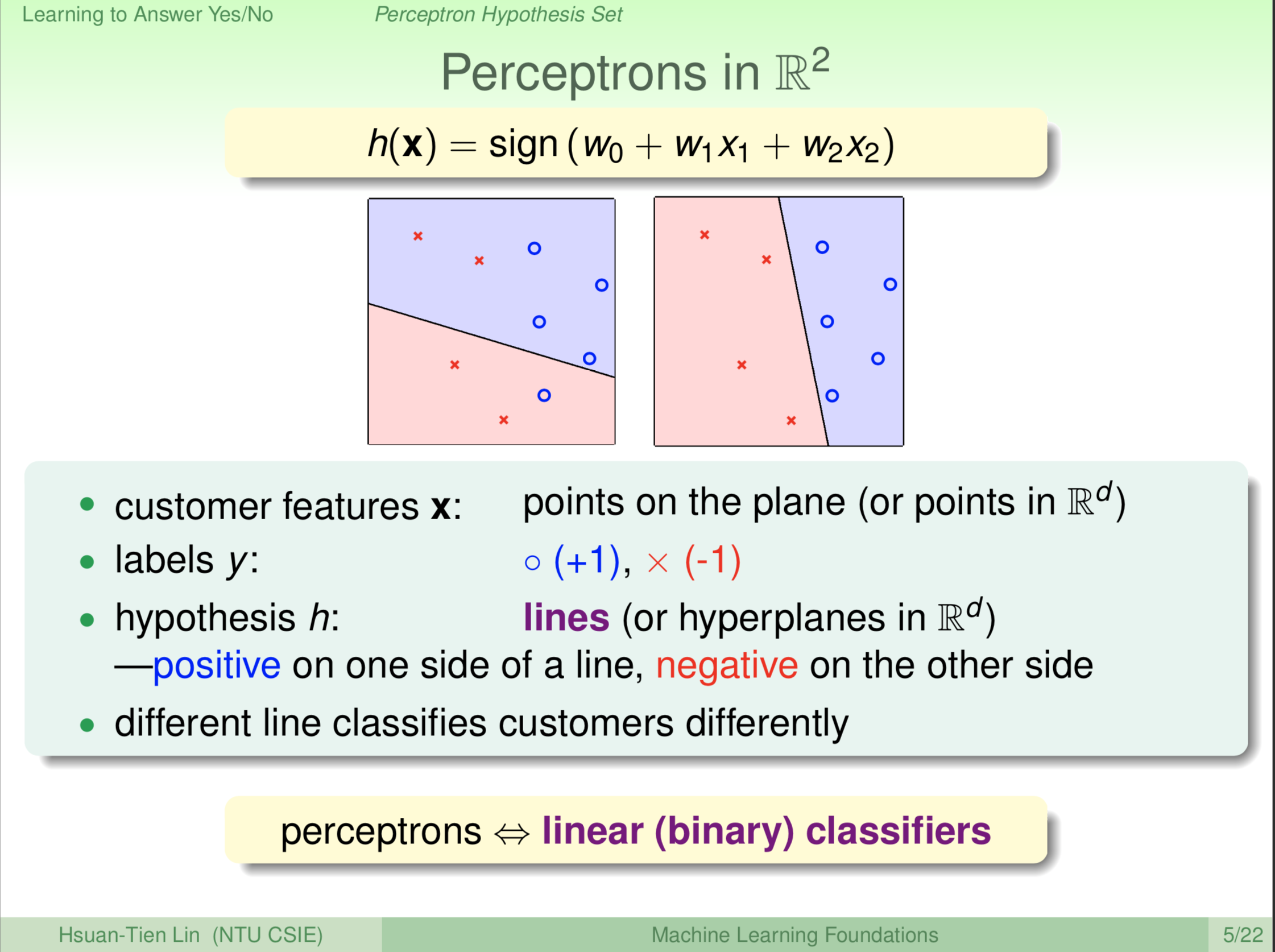
我们做什么呢?我们画一个二维图(\(x_1x_2\) 是变量)给大家看。这个二维图上是什么呢?二维图的每个 x 是二维的 \(x_1x_2\)。那如果我们加上 \(x_0\) 这个维度,是一个假三维,高高的向量:
\[
\left[
\begin{matrix}
x_0 \\
x_1 \\
x_2 \\
\end{matrix}
\right]
\]
每一个 \(h(\textbf x)\) ,它有一个 \(w_0\) (其实此处由于 \(x_0=+1\),所以 \(w_0x_0=w_0\)),一个 \(w_1\) 乘以 x 的第一个维度 \(x_1\) ,一个 \(w_2\) 乘以 x 的第二个维度 \(x_2\)。\(w_0\) 是我们的门槛值,可以视为截距;\(x_1x_2\) 未知,反映到平面上 \(h(\textbf x)\) 是一条线,任何一条这样的 \(h(\textbf x)\) 我们都可以把它画出来。像上图这样画出来,那怎么画呢?我给大家解释一下。我们的每一个原来的顾客的向量,是一个二维的向量。我们就把它们表示成平面上的一个点就是圈圈或者叉叉,通通都是一个点。如果我们有更多维,当然在欧几里德空间里,是更多维空间中的点。二维比较适合举例。那么我们的机器输出 y 在哪里呢?一般在资料里面对应到想要的输出我们一般把它叫做 lable,标签。这个标签在哪里呢?这个标签我们画成圈圈,还是叉叉。圈圈代表我们想要 +1,叉叉代表我们想要 -1。 \(h(\textbf x)\) 这条线把平面分割成两部分,在这条线上的点 x ,我们带入 \(h(\textbf x)\) ,则 \(h(\textbf x)\) 为零;这条线两侧的点带入 \(h(\textbf x)\) 则是异号。\(h(\textbf x)\) 这条线的一侧我们预测成圈圈,另一侧预测成叉叉。所以我们的 x 对应的每个 \(h(\textbf x)\) 实际上是对应到平面上面的一条线,我们的每个资料里面的每个 x 对应一个点,y 对应到我们的这个点上画圈圈还是叉叉。然后,每个 \(h(\textbf x)\) 我们对应一条线,线的一边是正的,一边是负的。所以你看到平面上有很多条线,例如说上左图中的那条线上面是正的,下面是负的;上右图右边是正的,左边是负的。每一个 \(h(\textbf x)\) ,即每一条线就会有不一样的预测。每一条线是不一样的,所以其实从另外一个角度来看,如果从几何角度来看的话,我们前面说的 perceptron,感知器,实际上就是平面上的一条一条线,所以我们又说它叫 linear classifiers,线性的分类器。我们要回答是非题,其实就是分成两类。线性的分类器,用一条线来代表的分类器。那在更高维的话,可能就是这个平面或高纬度的平面,跟线实际上在几何上是有类似的意义的。
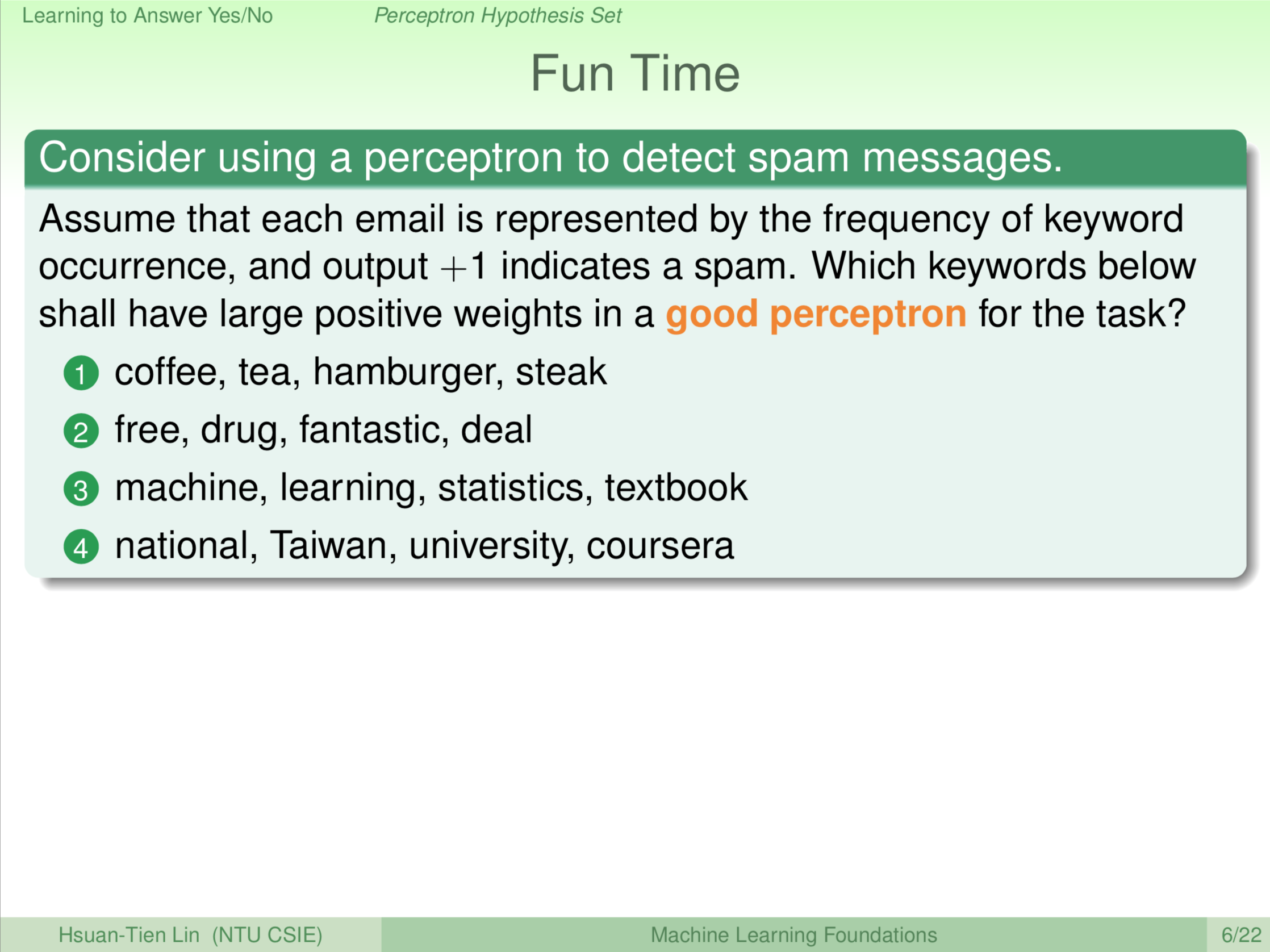
所以这个跟大家介绍的 perceptron,感知器,这样的一个 hypothesis。介绍完这个之后大家想一想,如果今天把感知器这样的东西用在垃圾邮件预测。要预测垃圾邮件,我们可能想到的方案是我们把邮件里面的文字表示成一个长长的向量,有出现这个文字就说有这个字,没有出现这个文字就说零,没有这个字。所以一个邮件可以看成一个长长的向量,如果我们使用感知器的话,那大家想一想,感知器里面不是有那些 \(xw\) 嘛,哪一个维度对应哪一个字,对应到的这个 \(w\) 会有比较大的权重,会有比较大的权重才是合理的。
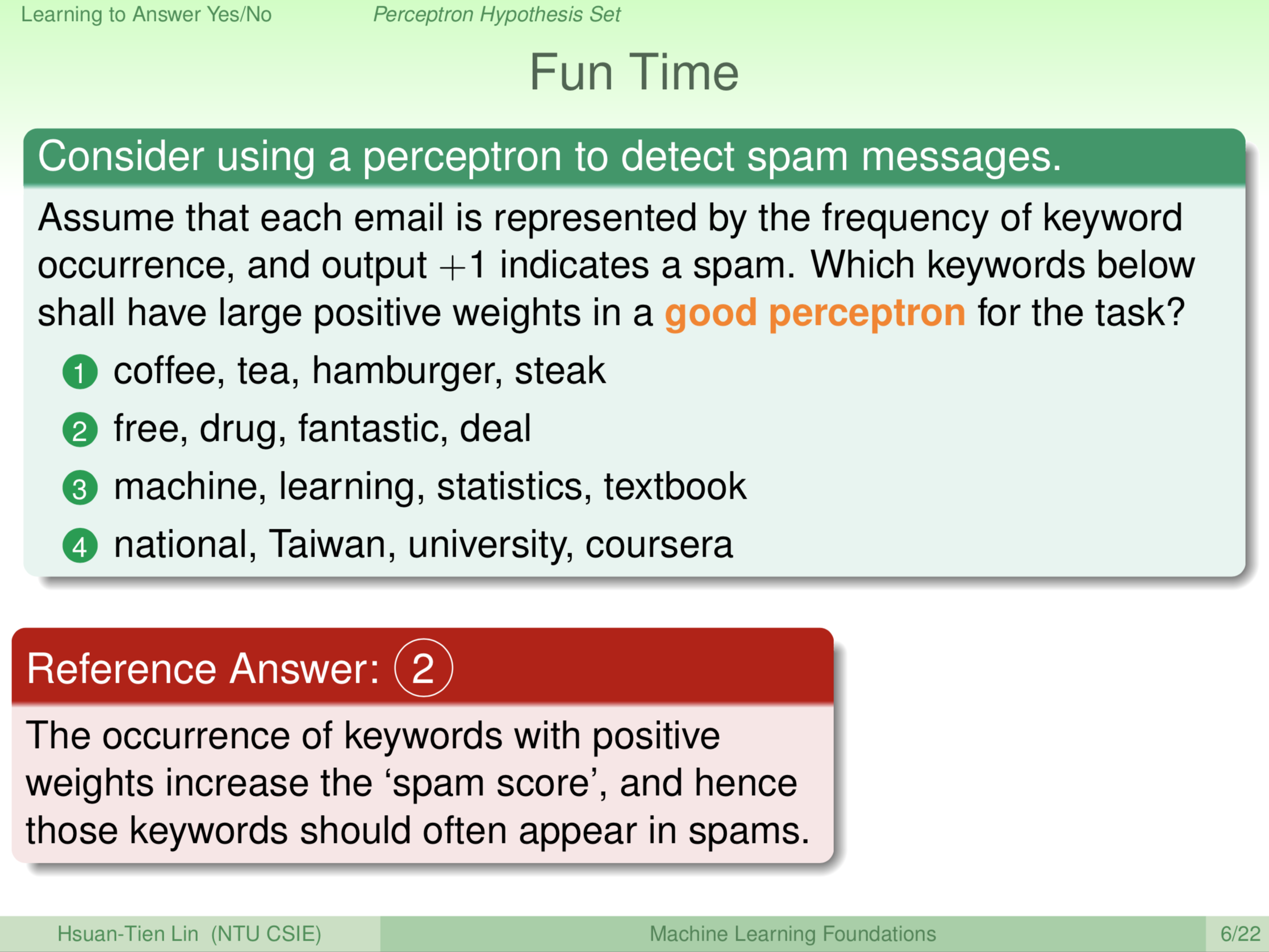
如果今天我们要做垃圾邮件预测,大家想一想之后希望大家得到的答案是2。什么东西会有很大的权重?基本上是,我们有点像在算垃圾邮件的分数,所以有很大的权重就表示那些字在垃圾邮件里面是常常出现的,这样才会帮垃圾邮件的分数加分。我们列出的2中的词,free、drug,等等,是在垃圾邮件里常常出现的词,这些词可能会得到较大的权重。

我们现在知道了一个可能的 hypothesis set,可能的大 H 的长相。也就是说,我们现在想象大 H 就是平面上所有的线,或者是说,我们在这个空间里面所有可能的高维平面。那我们现在的问题是我们要怎么样设计一个演算法?从这么多的线里面选一条最好的线出来。大家记得我们上次提到演算法的目的就是要选一个最好的东西出来。我们怎么选择一条最好的线呢?我们回头想想,我们觉得最好的线是什么?我们觉得最好的就是那个理想上的 f。但是 f 我们不知道,不然就收工回家吃饭啦!再三强调,f 我们是不知道的,如果我们知道 f ,那就不用机器学习了,这学期也不用上课了,大家下课回家!我们不知道 f,但是我们最想要的线是跟 f 长得越接近越好。那怎么办呢?我们只好回头看看我们知道什么,我们唯一知道的是我们的资料是从 f 产生的。
当我们的资料是从 f 产生的时候,我们至少可以先要求,我们的 g 跟 f 在我们所看过的资料上要长得越接近越好,或最好是一模一样的。如果是一模一样的话,那至少代表我看过的资料我都确定没有问题了,没看到的资料另当别论。所以,我们可以在已知的所有资料里面找一条线,这条线表明在我所看过的资料里都跟 f 长得一模一样。什么叫跟 f 长得一模一样?也就是说我如果用 g 预测资料里面的这些 \(\textbf x_n\),我就会马上得到这些 \(y_n\)(我想要的这些圈圈叉叉),在我已经看过的资料上面是准的。这是我们的出发点,这个出发点对不对我们之后整学期的课会再跟大家谈这个。接下来怎么做?我要在已经看过的资料里面找一条线,满足:我的资料里面如果是圈圈的,这条线就要告诉我们圈圈;我的资料里面如果是叉叉的,这条线就要告诉我是叉叉。
想一想,搞不好还不是这么容易。为什么不是这么容易?因为你有无限多条线。就算是二维空间,你的线在那边转来转去,你有无限多条线。如果你的搜寻方法很笨拙,搞不好你要搜寻无限多种可能才会决定说哪一条线是你要的。如果维度更高,可能就更困难。所以这不是太容易,那我们现在要跟大家介绍的方法出发点是什么呢?我们先有一条线在手上,而这条线可能不是那么好或怎么样。我们可不可想办法有一条线在手上以后,修正一下它。修正一下的意思就是说把这条线越变越好,这跟人类学习有一点像。我们一开始的时候可能这个不太会,可是越学越会。我们有一条线在手上,这条线可能会不太好,它可能在我们已知的资料上犯一点错误。像上图,我们现在手头有一条线,左边右下方的圈圈是一个错误。这一个错误怎么办?我们就想办法来修正一下。我们把这个线稍微移动一下,看看能不能完全修正这个错误或减轻这个错误。
这个是我们接下来要跟大家介绍的一个算法。我们一开始的时候从一条线出发,我们把这条线叫做 \(g_0\),从这一条线 \(g_0\) 出发,这条线如果不好,我们就把它变更好,直到我们觉得这条线好到不能再好,那我们才结束。
那我们从这个 \(g_0\) 出发,从符号上简单起见,我们把这个 \(g_0\) 用 \(w_0\) 来代表。前面提到每个 hypothesis 在我们现在的讨论里面对应一个高高的 \(\textbf w\) ,所以我们用 \(\textbf w_0\) 来代表一开始的线 \(g_0\),然后我们想办法要让这条线变得一次比一次更好。

那我们要怎么样做?我们一开始要有一个 \(\textbf w\),大家可能会很困惑 \(\textbf w\) 到底长什么样。可能会说,不管了一开始 \(\textbf w\) 设置为全0,代表你什么都不知道就很难决定。稍等一下会告诉大家怎么样能够做更好。一开始有个 \(\textbf w\) 之后,如果这个线还不完美,我们一定找得出某一个点,资料里面的某一个点,我们这里用 \((\textbf x_{n(t)},\textbf y_{n(t)})\) 代表,因为这个是一轮一轮的,\(t\) 代表第 \(t\) 轮。如果我现在的线把它叫做 \({\color{Red}{\textbf w_t}}\),在 \((\textbf x_{n(t)},\textbf y_{n(t)})\) 这点上犯了错误。什么叫犯了错误?犯了错误就是说,我拿这条线 \({\color{Red}{\textbf w_t}}\) 去跟 \(\textbf x_{n(t)}\) 做内积去做预测,结果得到的符号 \(sign({\color{Red} {\textbf w^{\textbf T}_t}} {\textbf x_{n(t)}})\),得到正负号。跟我想要的这个(\(\textbf y_{n(t)}\))符号不一样,就表示第 \(t\) 轮的这条线 \({\color{Red}{\textbf w_t}}\) 犯了错误。犯了错误怎么办呢?我们就想办法来修正它。
怎么修正呢?我们这里用上图右边的一个示意图跟大家讲,课程后边会有更详细的图给大家看到底是怎么回事儿。修正有两种:一种是我想要的符号是正的,即 \(\textbf y=+1\),结果它跟我说是负的(\(\color{red}{\textbf w}\) 与 \(\textbf x\) 是钝角),代表我的这个 \(\color{red}{\textbf w}\) 与 \(\textbf x\) 的角度太大。太大怎么样?太大我们就把 \(\color{red}{\textbf w}\) 转回来,我们用 \(\color{red}{\textbf w}\) 与 \(\textbf x\) 加起来,即 \(\color{purple}{\textbf {w+yx}}\) ( \(\textbf y=+1\) ),这样 \(\color{red}{\textbf w}\) 在这个 \(\textbf x\) 上可能就是正的,即 \(sign({\color{Red} {\textbf w^{\textbf T}_t}} {\textbf x_{n(t)}})\) 可能是正的。另外一种可能性,我想要的符号是负的,即 \(\textbf y=-1\),结果它跟我说是正的(\(\color{red}{\textbf w}\) 与 \(\textbf x\) 是锐角),代表我的这个 \(\color{red}{\textbf w}\) 与 \(\textbf x\) 的角度太小。太小怎么样?太小我们就把 \(\color{red}{\textbf w}\) 转开,我们用 \(\color{red}{\textbf w}\) 与 \(\textbf x\) 相减,即 \(\color{purple}{\textbf {w+yx}}\) ( \(\textbf y=-1\) ),这样 \(\color{red}{\textbf w}\) 在这个 \(\textbf x\) 上可能就是负的,即 \(sign({\color{Red} {\textbf w^{\textbf T}_t}} {\textbf x_{n(t)}})\) 可能是负的。这样,希望下一轮我的新的 \(\color{red}{\textbf w}\) 与 \(\textbf x\) 更对一些。
如果我要正的,那我就把 \(\color{red}{\textbf w}\) 转的靠近 \(\textbf x\) 一点;如果我要负的,我就把 \(\color{red}{\textbf w}\) 转离 \(\textbf x\) 一点。所以 \(\color{purple}{\textbf w_{t+1}}\leftarrow\color{red}{\textbf w_t}+\color{blue}{\textbf y_{n(t)}\textbf x_{n(t)}}\) 就是我们的式子,我 \(t\) 轮犯的错,\(t+1\) 修正。修正到什么时候呢?修正到我不再犯错的时候。所以它一直跑,跑到不再犯错的时候。不再犯错的时候,我最后那条线完全没有错误了,我就开心的说:“啊哈!找到这条线了!!”。我就把这条线传回去说,这是我继续学习的结果。
我继续学习的结果说,我找到这条线 \(\color{purple}{\textbf w}\)。我们把这条线叫做 \(\color{purple}{\textbf w_{PLA}}\),那个PLA这三个字是 Perceptron Learning Algorithm。
就这样,好简单的演算法。这个演算法我常常叫它什么?叫它知错能改演算法。我们大家看这个英文句子:A fault confessed is half redressed(知错能改,善莫大焉)。所以它知道错,它找出一个犯错地方,然后想办法把它改过来,直到改到没有错误。这一条线真是完美,回传回去。

我们刚才只是一个概略的演算,实际上这个演算法可能还有一些细节。例如,你要怎么简单的判断它就完全没有犯错?或你要怎么简单的找出来它到底还有没有错误?一个常见的方式是,我们就从1号、2号、3号 ··· ··· N号,把这N个点都看一下。例如说我有100个点,就从1号~100号,我一个一个轮流去看我的点,如果这个点没有错,我就开开心心去看下一个点,如果这个点犯了错误,我就做刚才的错误修正。如果我100个人都拜访过又绕回来后,发现都没有再犯错,就表示我做完了。这样的方式我们一般叫做 cyclic。这是一个常见的方法来写 PLA,当然还有很多其他不同的方法,这个 cycle,你可以说我就原来资料有第一个到第一百个人,就从原来的一号到一百号;或者你先用乱数决定一个顺序说,我第一个人跳第七个人再跳回第二个人,再跳第九个人,再跳第五个人,直到跳完这一百个人,这种方法也可以。只要你能够绕圈圈的做就可以了。这些是常见的方式,因为可以很简单的知道还有没有人犯错,然后来决定我们的演算法要不要停。
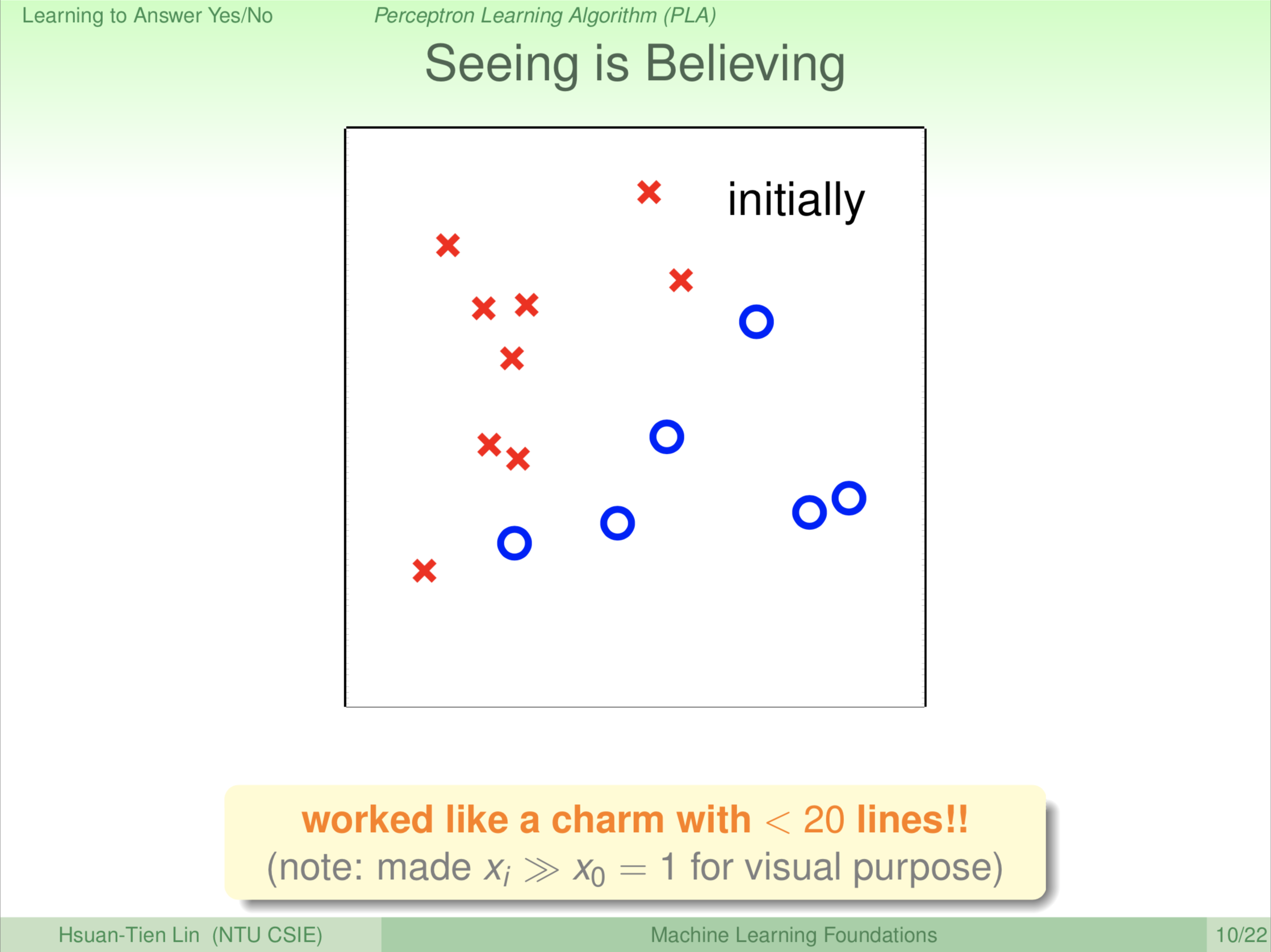
这样讲,大家可能不太相信,可能说哪有这个三言两语的演算法就可以做机器学习的。接下来,我们就来看看这样的演算法能不能真正做到很好。我们喂给机器这样的资料,大家现在应该开始熟悉这样的图。这是一个二维的资料,我们有一堆的 \(\textbf x\),这些 \(\textbf x\) 对应到+1是圈圈;我们有另外一堆 \(\textbf x\),这些 \(\textbf x\) 对应到-1是叉叉。机器看到的资料,就可以视觉化成这样子的图,一堆圈圈,一堆叉叉。我们现在的问题是机器能不能通过我们刚才的那个方法找到那条线。
\[{\color{Red} h}(\textbf x)=sign({\color{Red} {\textbf w^{\textbf T}}} {\textbf x})\]
该方程类似于直线的点法式是方程。\(\color{red}{\textbf w^{\textbf T}}\) 是直线的 \({\color{Red} h}(\textbf x)=sign({\color{Red} {\textbf w^{\textbf T}}} {\textbf x})=0\) 的法向量。
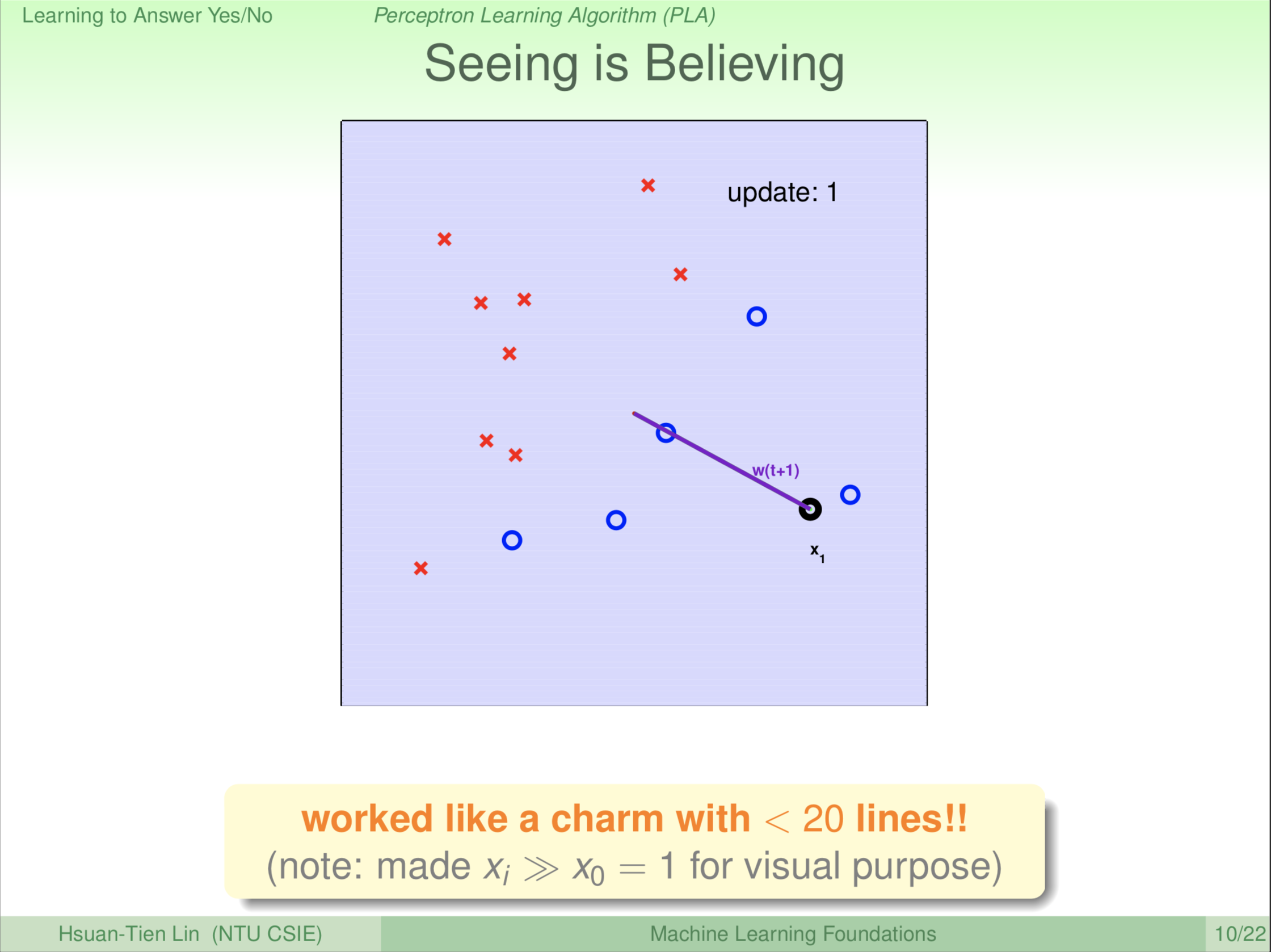
第一轮。由于一开始是没有线的,所以机器不管看到什么都认为是错的。机器先找第一个点 \(\textbf x_1\),认为该点是错的,修正该点。怎么做修正呢?做修正就是把该点与原点(0,0)连线作为一条线的法向量,我们把二维图中心作为原点。所以下一轮我们就会看到垂直于这个法向量的一条线把二维平面分割成红、蓝两部分。
\(\color{red}{\textbf w_{(t)}}\) 是当前轮的红、蓝区域分割线的法向量;\(\color{purple}{\textbf w_{(t+1)}}\) 是下一轮红、蓝区域分割线的法向量。
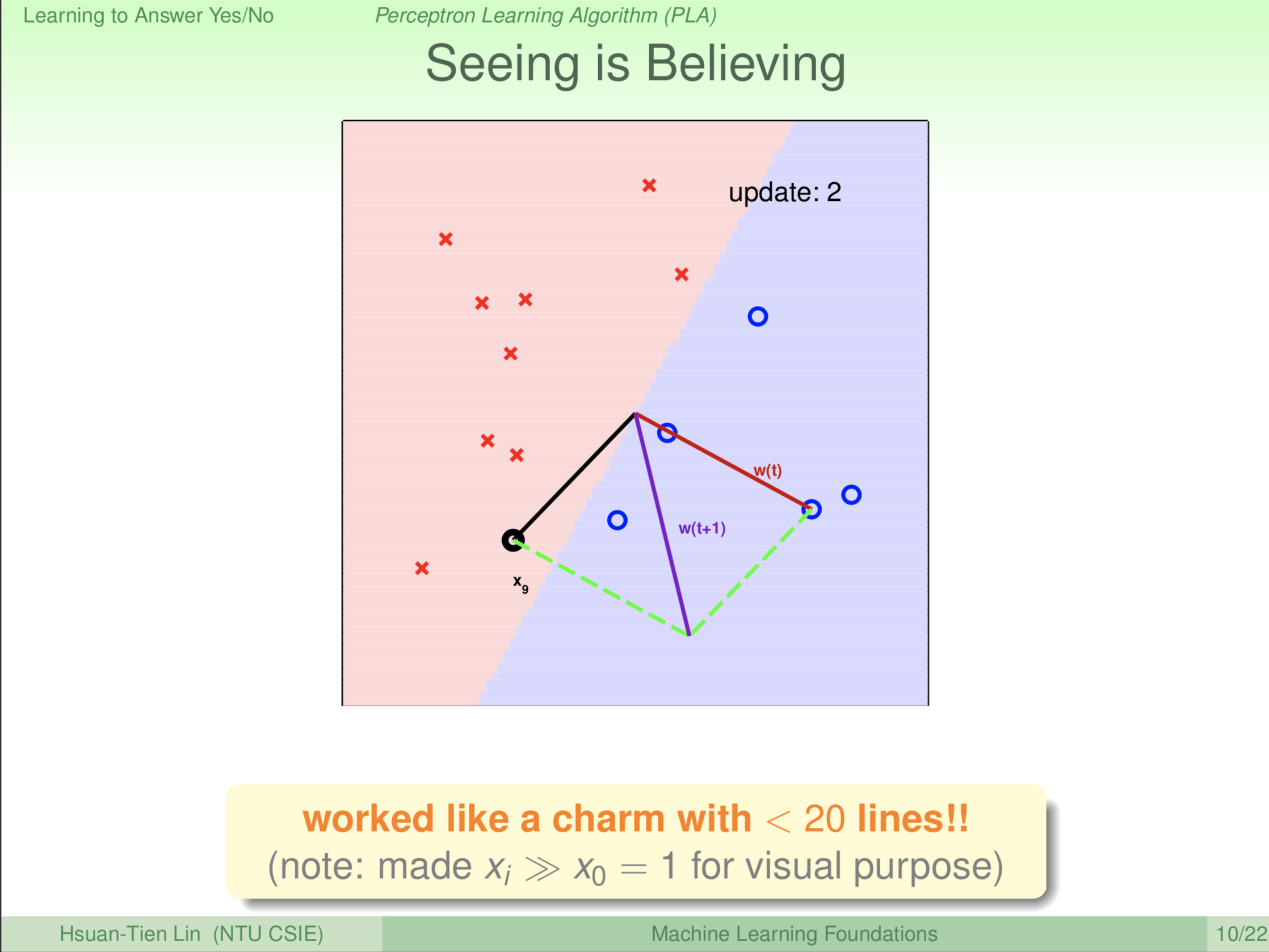
二维平面分割线是不是已经完全没有错误了吗?大部分叉叉在红色区域(负),大部分圈圈在蓝色区域(正)。这个演算法就找啊找,发现红色那边还有一个圈圈,有错误就要改正。怎么改正?原来的方向是红色的线 \(\color{red}{\textbf w_{(t)}}\),我的错误发生在黑色的线 \(\color{black}{\textbf x_9}\),我想要把这个黑色的线往正的那边(蓝色区域)修正。也就是说,我要做的更新是什么呢?把我原来的方向 \(\color{red}{\textbf w_{(t)}}\) 做个旋转,跟 \(\color{black}{\textbf x_9}\) 靠近一点,所以我旋转过来得到 \(\color{purple}{\textbf w_{(t+1)}}\) 这条紫色的线。所以大家在下一轮会看到,红、蓝区域的分割线就往 \(\color{black}{\textbf x_9}\) 这边转了, \(\color{purple}{\textbf w_{(t+1)}}\) 是红、蓝区域分割线的法向量。
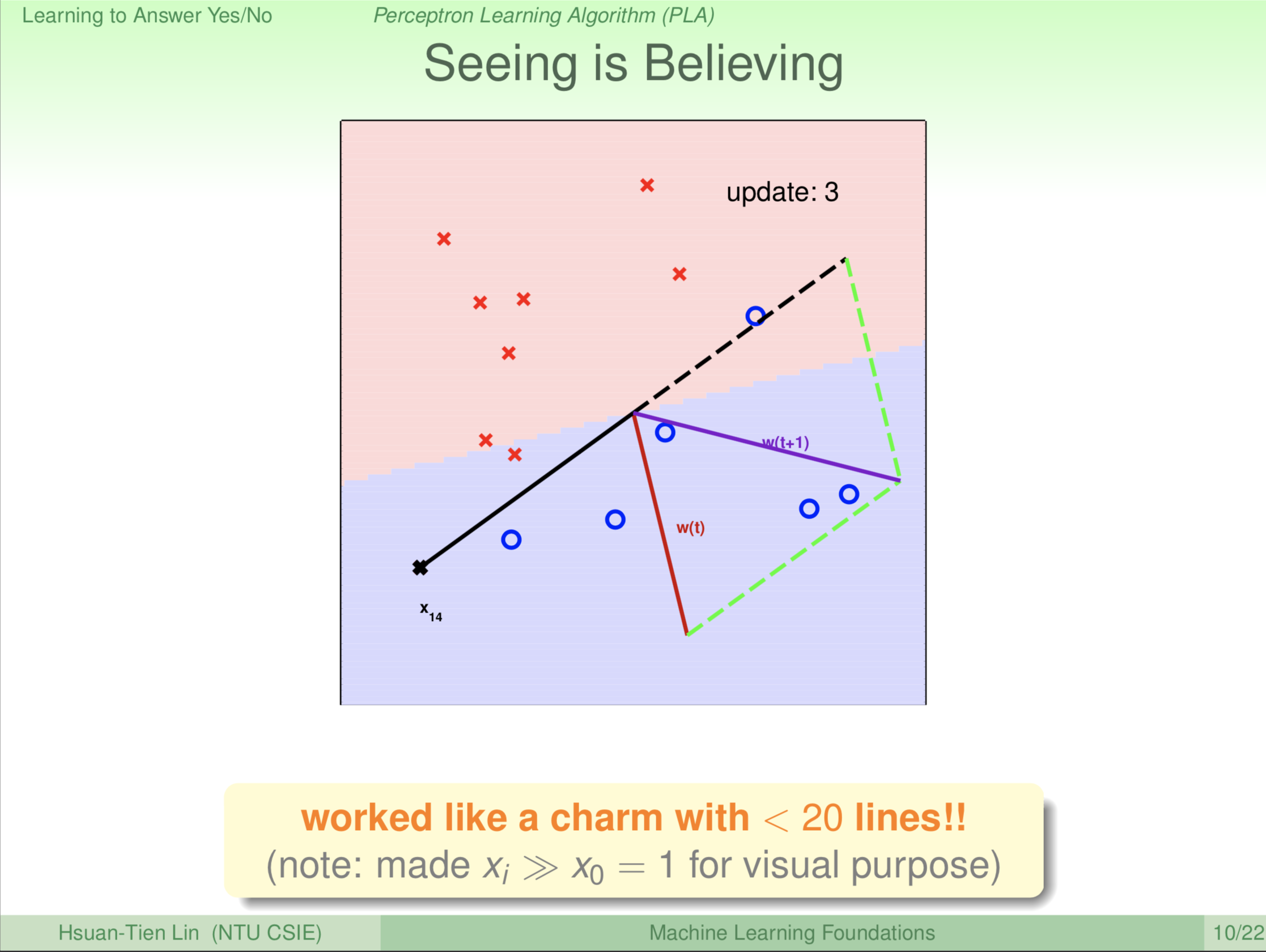
大家看到红、蓝区域的分割线转过来了。转过来后,我们是修正完了一个错误,那是不是就可以高枕无忧了呢?并没有。红、蓝区域的分割线转太多了,上一轮的 \(\color{black}{\textbf x_9}\) 这一点对了,可是 \(\color{black}{\textbf x_{14}}\) 所在的位置又发生了错误,因为叉叉本应该在红色区域。这个演算法就找啊找,发现 \(\color{black}{\textbf x_{14}}\) 这个叉叉有错误,这个错误代表红、蓝区域的分割线还有继续旋转,怎么旋转?\(\color{red}{\textbf w_{(t)}}\) 这条线太靠近 \(\color{black}{\textbf x_{14}}\),我们把 \(\color{red}{\textbf w_{(t)}}\) 转到 \(\color{purple}{\textbf w_{(t+1)}}\) 的位置。此时 \(\color{purple}{\textbf w_{(t+1)}}\) 是新的红、蓝区域分割线的法向量,所以再更新一次。
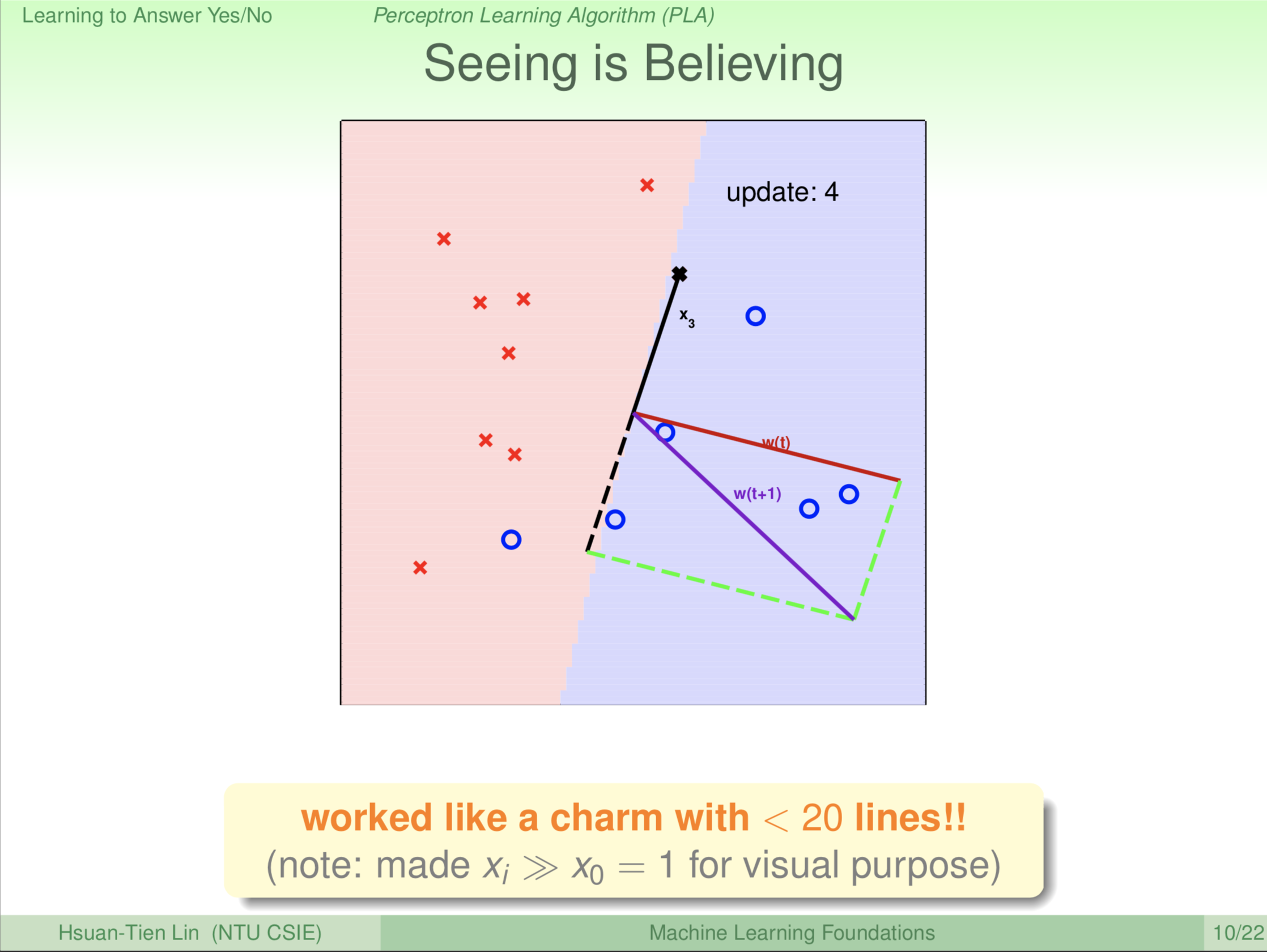
这条红、蓝区域的分割线完美了吗?哪里错了?\(\textbf x_{13}\) 发生错误。再修正一下,\(\color{red}{\textbf w_{(t)}}\) 转到 \(\color{purple}{\textbf w_{(t+1)}}\) 的位置。此时 \(\color{purple}{\textbf w_{(t+1)}}\) 是新的红、蓝区域分割线的法向量,所以再更新一次。
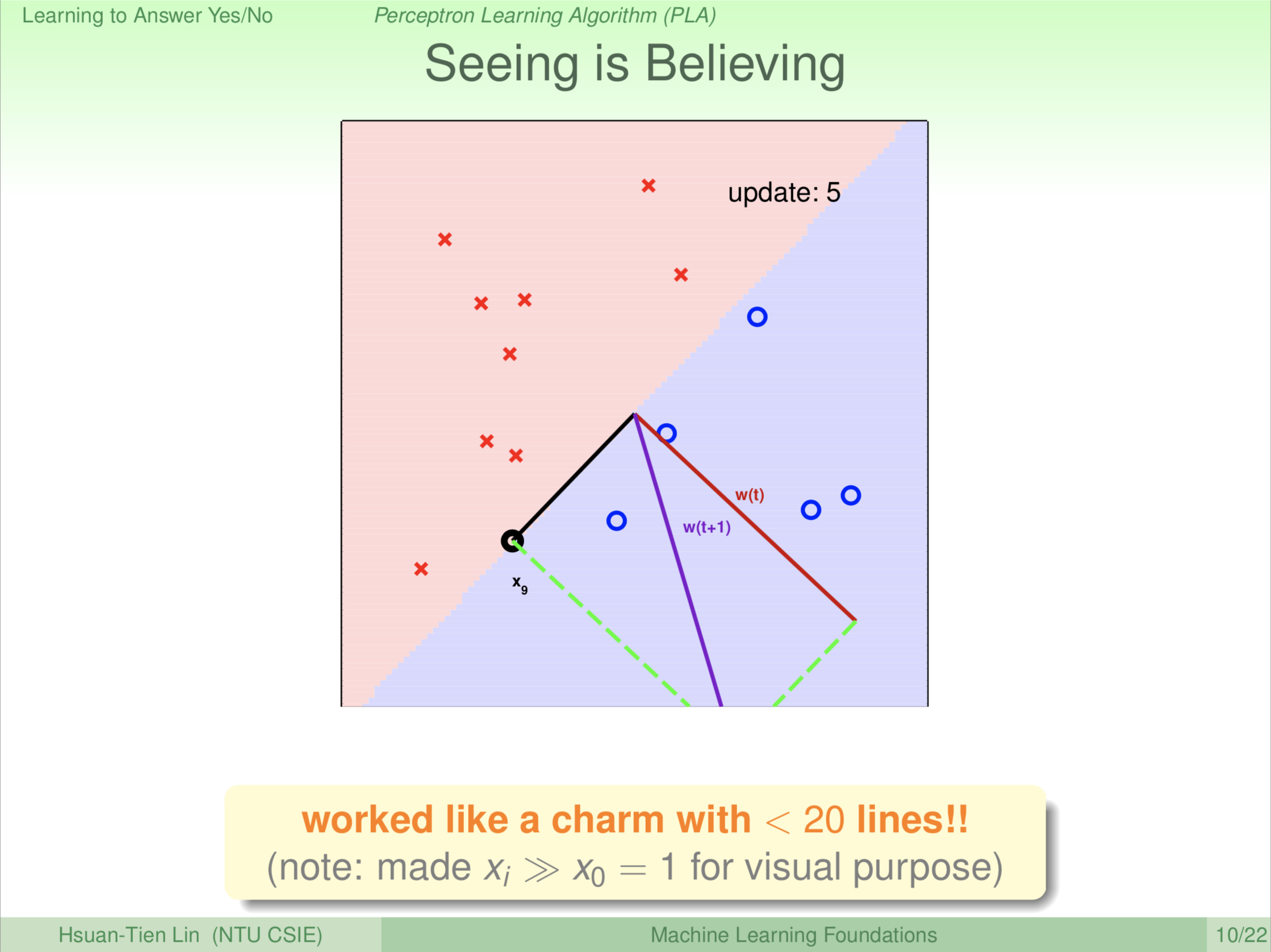
转后,发现 \(\textbf x_9\) 错了。你会想为什么错误这么多?因为我们一次只看一个点,考虑到这个点就有可能漏掉那个点。继续旋转 \(\color{red}{\textbf w_{(t)}}\) 转到 \(\color{purple}{\textbf w_{(t+1)}}\) 的位置。此时 \(\color{purple}{\textbf w_{(t+1)}}\) 是新的红、蓝区域分割线的法向量,所以再更新一次。
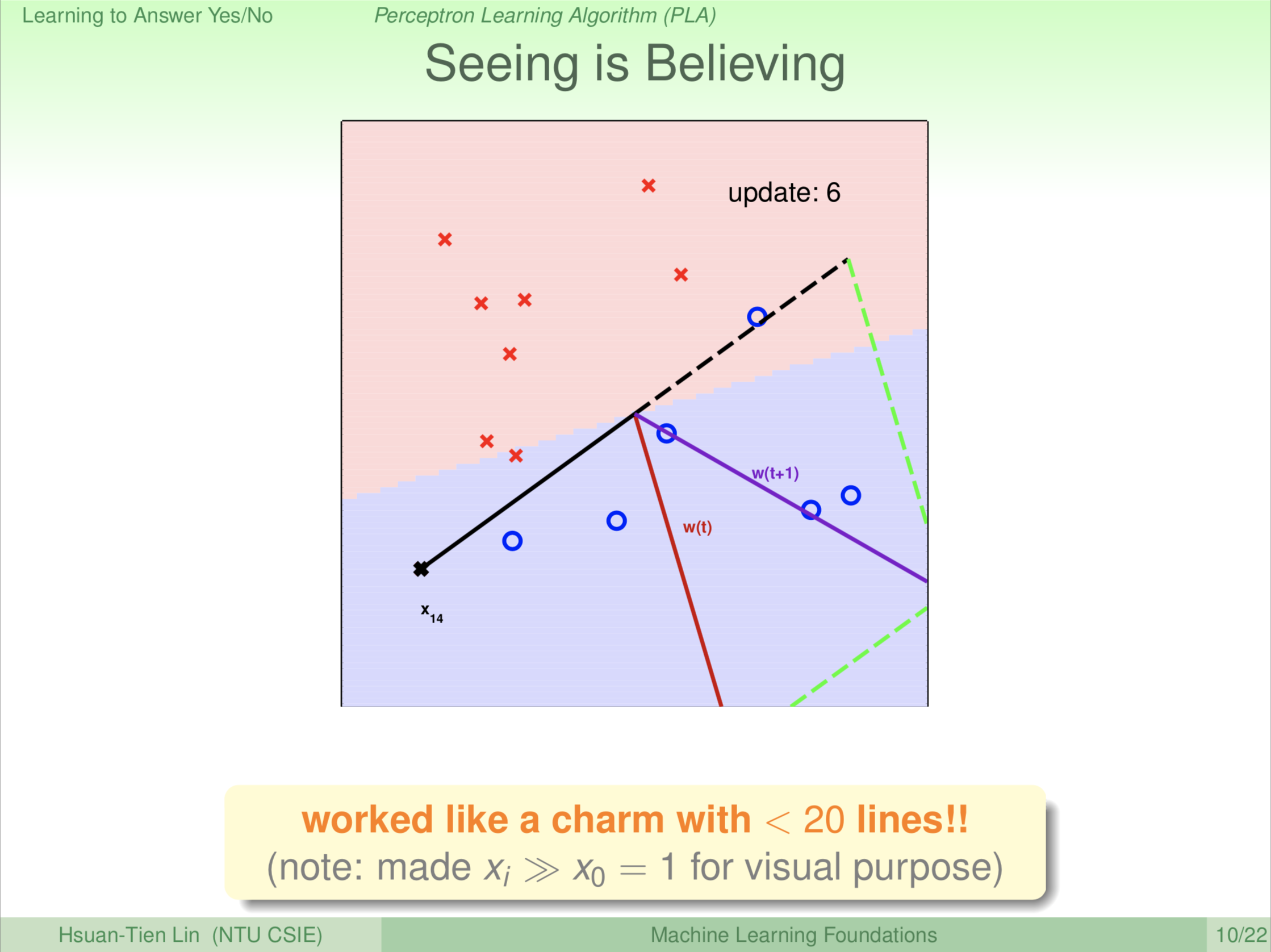
转回来发现又转太多了,继续转。
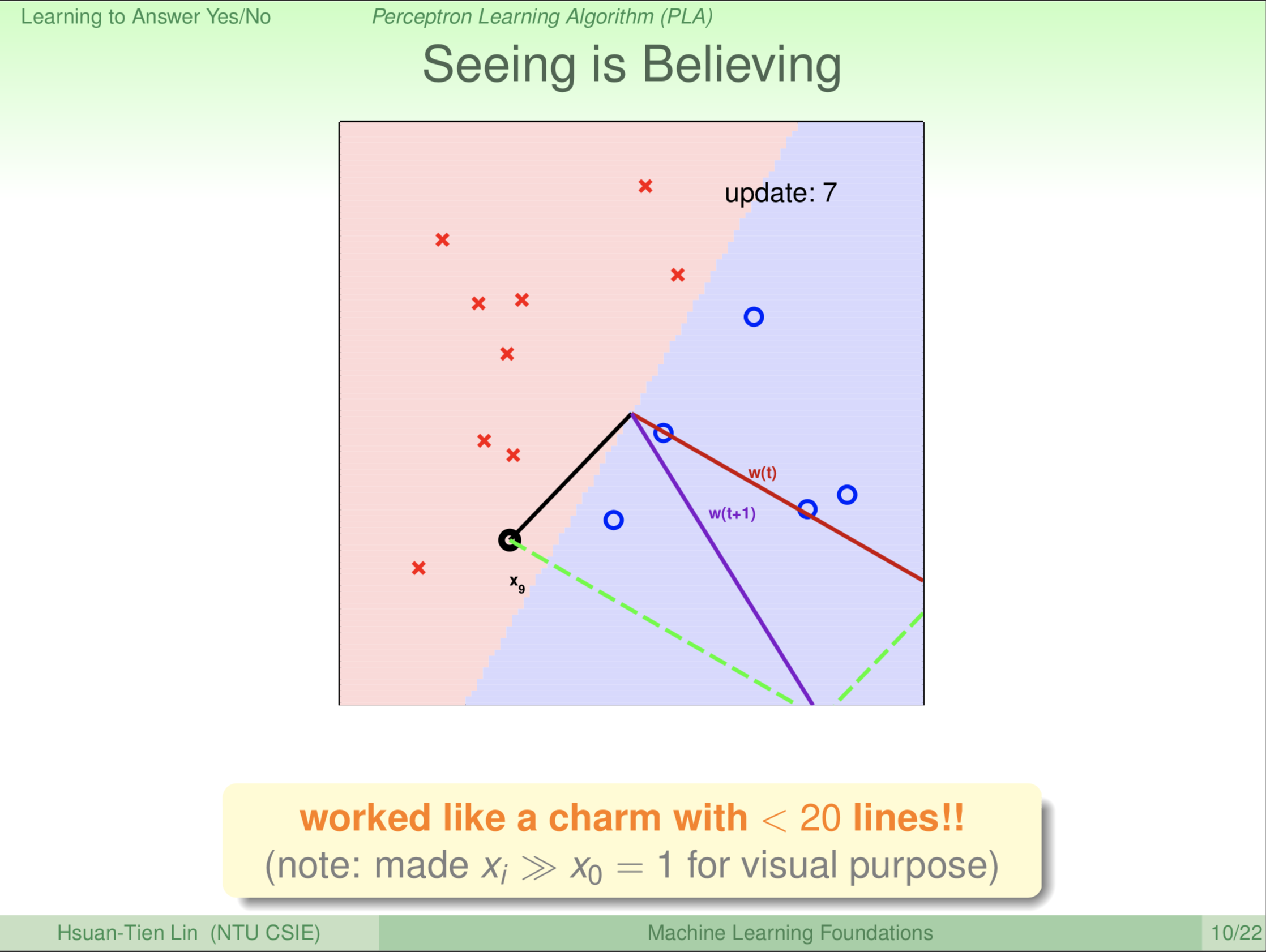
一直旋转 \(\color{red}{\textbf w_{(t)}}\)
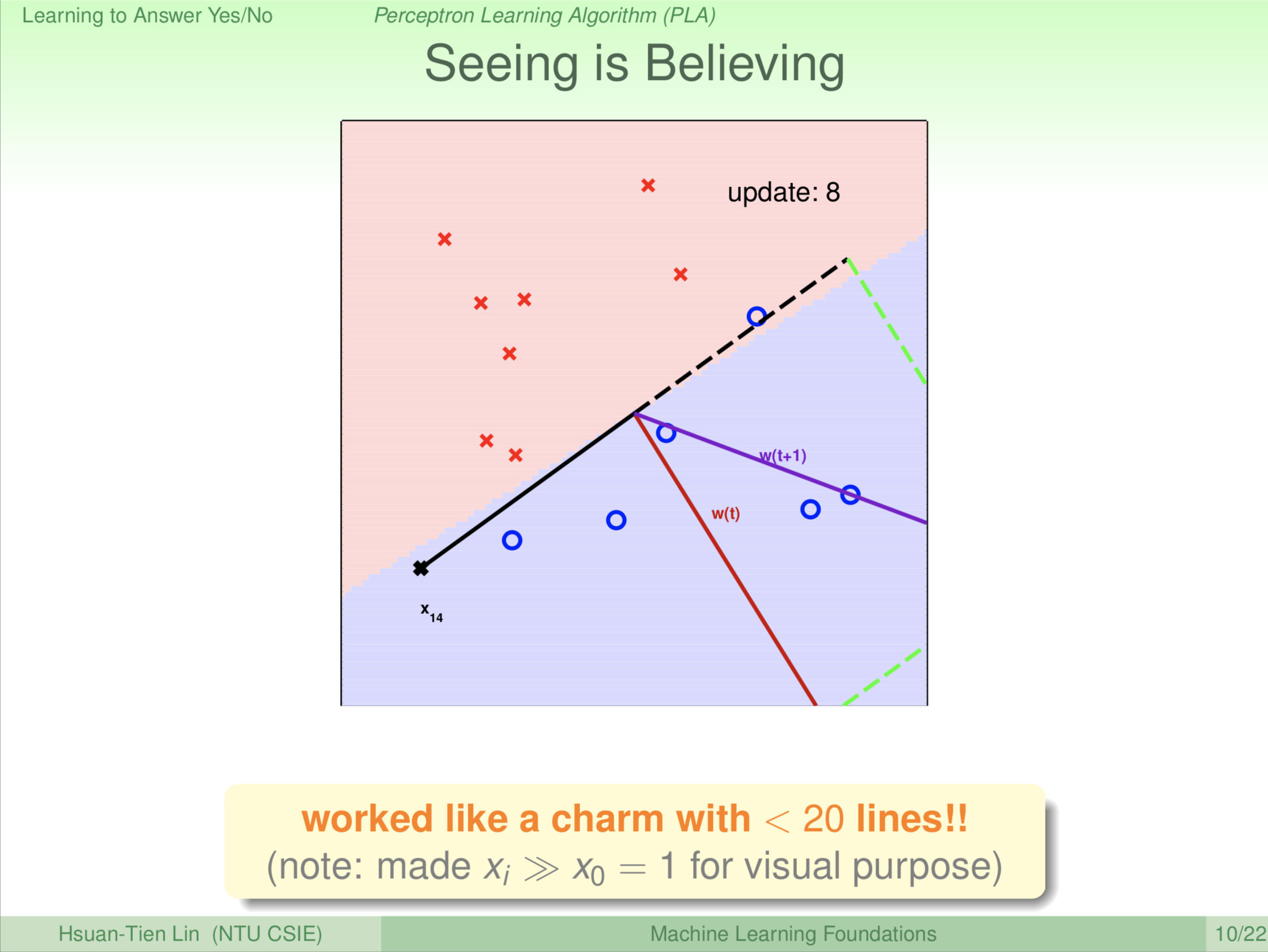
一直旋转 \(\color{red}{\textbf w_{(t)}}\)
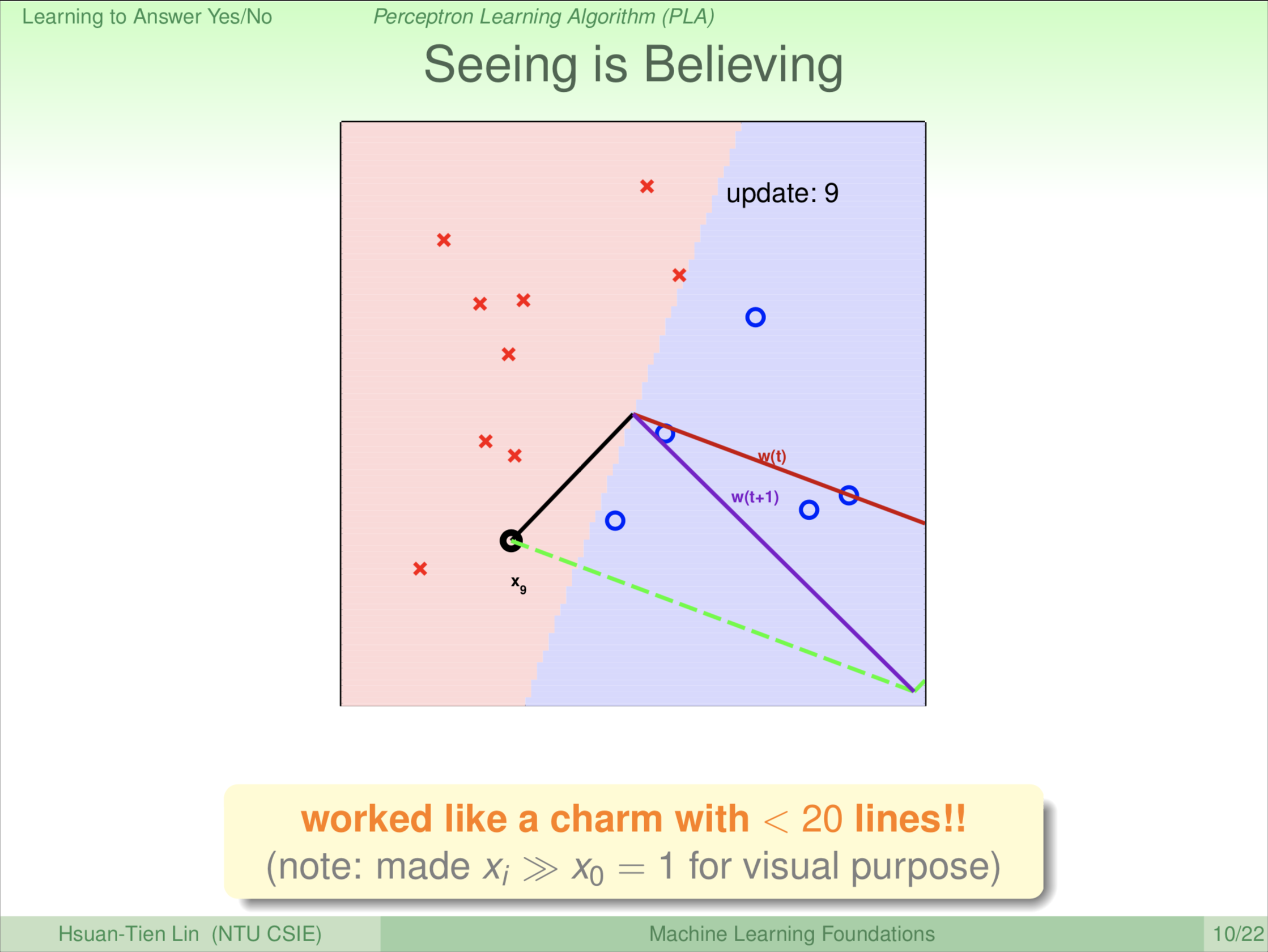
一直旋转,到了第9轮。大家看圈圈已经在蓝色区域(除了 \(\textbf x_9\)),叉叉已经在红色区域。剩下 \(\textbf x_9\) 这个圈圈,第9轮更新(旋转)之后。
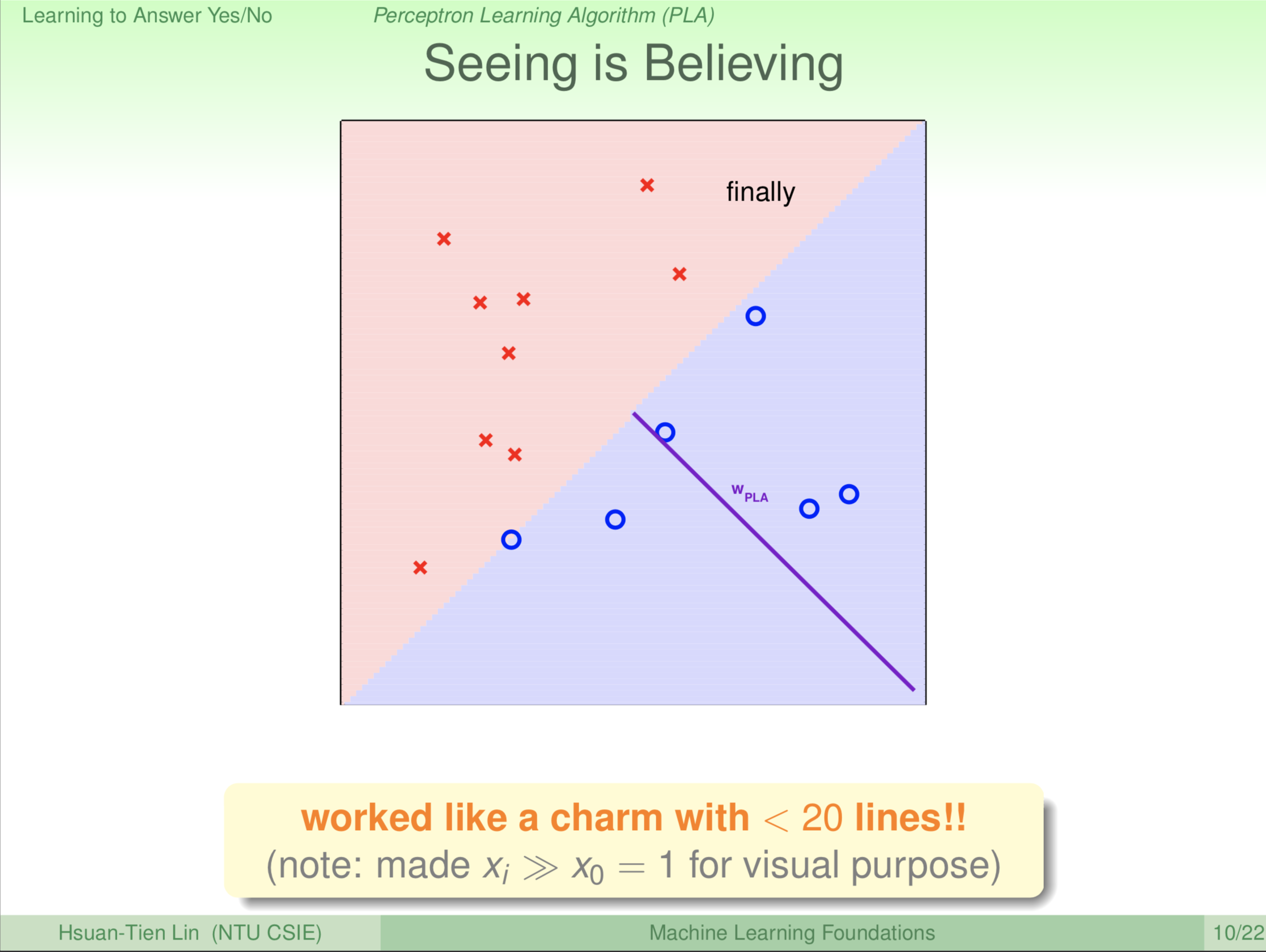
第9轮更新之后,很神奇,我们找到了一条线,这条线把所有的圈圈分割到一边,所有的叉叉分割到另一边,这是一条完美的线。至少,在我们所看到的资料上,是一个完美的线。
未来的作业里,我们会让大家写这个演算法。这是一个非常简洁的演算法。我写完的程式(程序,台译:程式)如果不含画图部分,不到二十行。
不断修正,最后找到一条还不错的线,\(\color{purple}{\textbf w_{PLA}}\) 是这条线的法向量。
为了视觉效果,我们让顾客的特征 \(\textbf x_{\textbf i}\) 都比 \(\textbf x_0\) 大很多。大家回忆前面我们强制把 \(\textbf x_0\) 设置成 +1,\(\textbf w_0\) 是门槛值。
为了视觉效果,我们要这么做。等一下我们会证明说这个演算法不管是不是为了视觉效果,都能帮我们找出好的线来。

那现在的问题是,这个演算法什么时候会停下来?没有错误的时候就会停下来,这个演算法停下来的时候就会找出好的线。这个演算法一定会停下来吗?我们前边没有讲说这个演算法一定会停下来,这是一个问题。它如果会停下来一切都好办,为什么它会停下来?它什么时候不会停下来?所以从另一个角度说,我们假设它停下来了,我们拿到的 g,跟我们最渴望的那个 f 到底一样不一样?
在一些特定的状况下,如果你让这个演算法跑得够久,它一定会停下来。它一定会停就表示至少在看到的资料上 g 跟 f 是相近的,看到的资料以外的部分,我们后边的课程会讲。

这个演算法我们很快的跟大家介绍过去,那我们希望深化大家对这个演算法的了解,所以我们有上面这一个题目。其实大家看到我们的演算法的核心就只有两条规则:
\(sign({\color{Red} {\textbf w^{\textbf T}_t}}\color{blue}{\textbf x_n})=\color{blue}{\textbf y_n}\)
找出一个犯错误的点,简洁起见我们把错误点叫做 \(\color{blue}{\textbf x_n\textbf y_n}\)
\(\color{purple}{\textbf w_{t+1}}\leftarrow\color{red}{\textbf w_t}+\color{blue}{\textbf y_n\textbf x_n}\)
用犯错误的点 \(\color{blue}{\textbf x_n\textbf y_n}\) 来做某种旋转更新 \(\textbf w\)
大家看一看上面这四个式子,然后想一想我给大家的这两条规则,这四个哪个是对的?

参考答案是 3
\[\color{purple}{\textbf w_{t+1}}\leftarrow\color{red}{\textbf w_t}+\color{blue}{\textbf y_n\textbf x_n}\]
\[\Leftrightarrow\color{purple}{\textbf w_{t+1}^{\textbf T}}\leftarrow\color{red}{{\textbf w_t}^{\textbf T}}+\color{blue}{(\textbf y_n\textbf x_n)^{\textbf T}}\]
\[\because\color{blue}{\textbf y_n\textbf x_n}是一个数\]
\[\therefore\color{blue}{\textbf y_n\textbf x_n}=\color{blue}{(\textbf y_n\textbf x_n)^{\textbf T}}\]
\[\Leftrightarrow\color{purple}{\textbf w_{t+1}^{\textbf T}}\leftarrow\color{red}{{\textbf w_t}^{\textbf T}}+\color{blue}{\textbf y_n\textbf x_n}\]
\[\Leftrightarrow\color{blue}{\textbf y_n}\color{purple}{\textbf w_{t+1}^{\textbf T}}\color{blue}{\textbf x_n}\leftarrow\color{blue}{\textbf y_n}\color{red}{{\textbf w_t}^{\textbf T}}\color{blue}{\textbf x_n}+\color{blue}{\textbf y_n^2\textbf x_n^2}\]
\[\because\color{blue}{\textbf y_n^2\textbf x_n^2}\geqslant0\]
\[\therefore\color{blue}{\textbf y_n}\color{purple}{\textbf w_{t+1}^{\textbf T}}\color{blue}{\textbf x_n}\geqslant\color{blue}{\textbf y_n}\color{red}{{\textbf w_t}^{\textbf T}}\color{blue}{\textbf x_n}\]
也就是说 \(\color{purple}{\textbf w_{t+1}^{\textbf T}}\) 乘上 \(\color{blue}{\textbf y_n\textbf x_n}\) 就会比 \(\color{red}{\textbf w_{t}^{\textbf T}}\) 乘上 \(\color{blue}{\textbf y_n\textbf x_n}\) 来得大。来得大是什么意思?\(\color{purple}{\textbf w_{t+1}^{\textbf T}}\color{blue}{\textbf x_n}\) 其实就是我们前边的分数减去门槛值,即:\(\sum_{i=1}^d{\color{Red} {w_i}}x_i - {\color{Red}{threshold}}\) 。
\(\color{purple}{\textbf w_{t+1}^{\textbf T}}\color{blue}{\textbf x_n}\) 乘上 \(\color{blue}{\textbf y_n}\) 会变大,代表说如果 \(\color{purple}{\textbf w_{t+1}^{\textbf T}}\color{blue}{\textbf x_n}\) 原来是负的,乘上 \(\color{blue}{\textbf y_n}\) 会变得稍微靠近正一点,\(\color{purple}{\textbf w_{t+1}^{\textbf T}}\color{blue}{\textbf x_n}\) 与 \(\color{blue}{\textbf y_n}\) 的符号会稍微符合一点,搞不好就变成全对了,搞不好还没有那么对。所以这里说的事情是,我们这个更新的规则实际上代表了这个演算法真的在尝试修正那条线,尝试把线转到正确的方向。
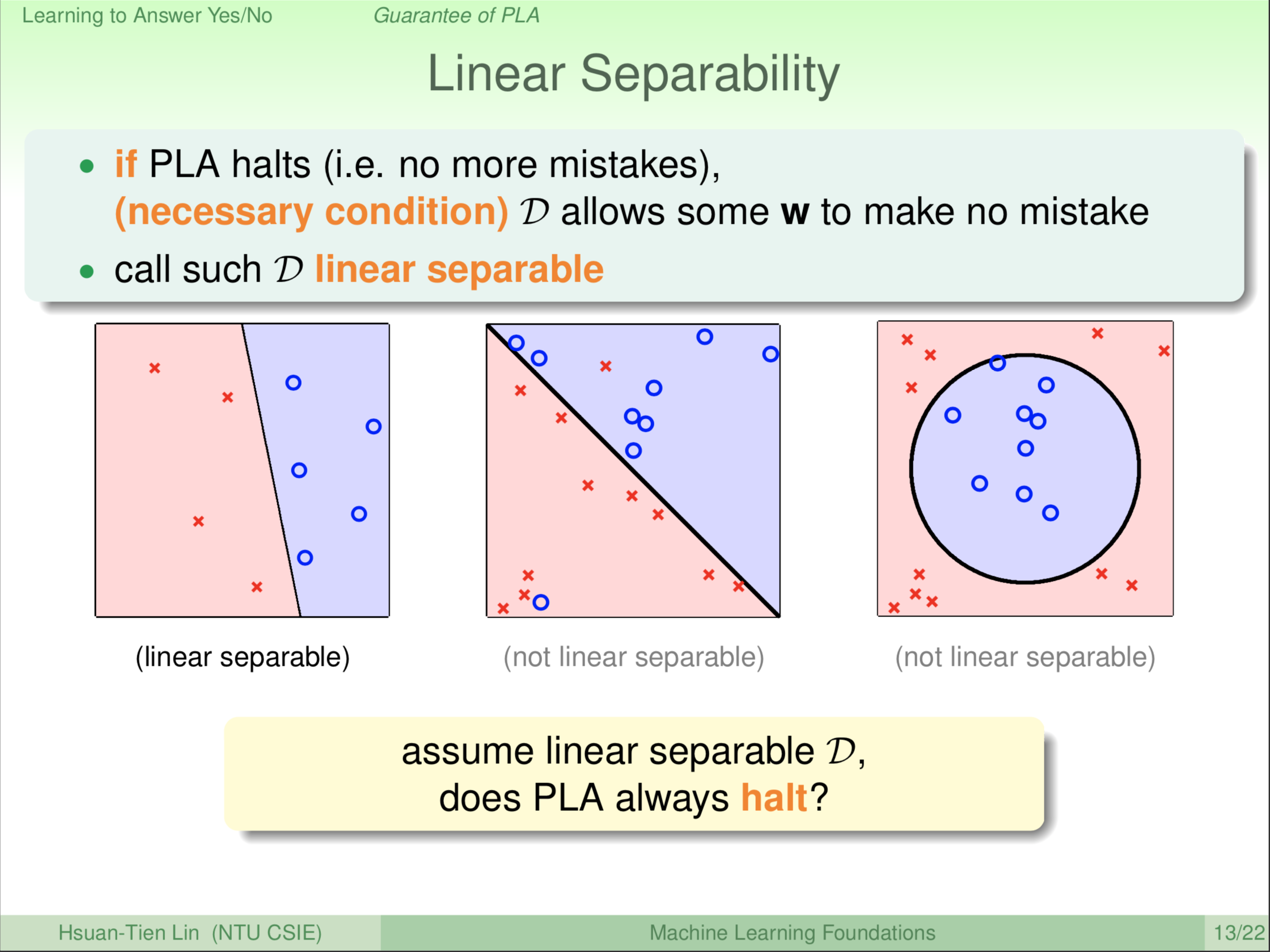
我们来看看说 PLA 什么时候可能会停下来?在想这个问题之前我们先回头想 PLA 的终止条件是什么?终止条件是它如果找到一条线把资料分的完全没有犯任何错误,那么PLA就停下来。要达成这个终止条件的前提条件是,你的资料要能够有一条线可以切开,如果你的资料根本就没有一条线可以切开,PLA跑一辈子也不会停下来的。这样的条件,我们就把它叫做Linear Separable,线性可分。
例如左边这幅图,我可以找到一条线把圈圈和叉叉分在对的地方,这叫做线性可分。那什么样的资料不是线性可分的?例如说中间那图,大家想想看,你不管怎么样转那条线,总会有一些圈圈在错误的地方,或有一些叉叉在错误的地方,我们永远都没有办法用一条线就把资料一刀两断统统都分对。或者再如右图这样的资料也不是线性可分,我们可能用圆圈把它分开,不过如果你坚持要用一条线的话,怎么切你一定不可能把圈圈切在一边,叉叉切在另一边。除了第一幅,右边这两种情形都不是线性可分的情形。眼尖的同学可能会发现,右边这两种情形实际上就是我们课程Logo里面我用的那两个图案。在未来的课程里,我们会介绍怎么处理这种不是线性可分的情形。
现在,我们先讲PLA在最简单的情形,Linear Seperable,线性可分,那么PLA到底会不会停下来?到底会不会找到一条这样的线呢?

好我们来看看,有一条线代表什么意思。我们把这条就叫做 \(\textbf w_f\) 好了,f 是我们特意用的。\(\textbf w_f\) 这条线就是我们的目标,f 就是我们所谓的 Target Function,目标函数。目标这条线 \(\textbf w_f\) 有什么特性?目标这条线满足 \(\textbf y_n=sign(\textbf w^{\textbf T}_f\textbf x_n)\) ,即 \(\textbf w_f\) 这条线很完美,通通都切开,正的就在正的那边,负的就在负的那边。数学上代表什么意思呢?
\[\color{blue}{\underset{n}{min} \textbf y_{\textbf n}\textbf w^{\textbf T}_f\textbf x_n}\color{red}{>0}\]
数学上代表每一个点 \(\textbf x_n\) 如果我用这条线 \(\textbf w_f\) 切下去,\(\textbf w^{\textbf T}_f\textbf x_n\) 我们算出它离这个线的距离有多远,当然是矢量距离(带正负号的距离)。然后用 \(\textbf w^{\textbf T}_f\textbf x_n\) 这个矢量距离乘上 \(\textbf y_n\) (乘上我们想要它在哪一边)。每一个 \(\underset{n}{min} \textbf y_{\textbf n}\textbf w^{\textbf T}_f\textbf x_n\) 都要大于0,也就是与线有一个距离。所以,\(\textbf w_f\) 这条线这么的完美,你切下去,圈圈就在圈圈那边,叉叉就在叉叉那边,它不会在线上也不会在错误的那一边。记得我们的PLA是每轮选一个错误的点 \((\textbf x_{n(t)},\textbf y_{n(t)})\),这个错误点也会满足:
\[\color{purple}{\underbrace{\textbf y_{n(t)}\textbf w^{\textbf T}_f\textbf x_{n(t)}}_1}\color{blue}{\geqslant\underbrace{\underset{n}{min} \textbf y_{\textbf n}\textbf w^{\textbf T}_f\textbf x_n}_2}\color{red}{>0}\]
有了这样的基础,我们就可以去看说理想的 \(\textbf w_f\) 和我们真正在找的 \(\textbf w_t\) 之间是什么关系,我们可以看看说 \(\textbf w_f\) 和 \(\textbf w_t\) 到底接不接近。衡量两个向量接不接近有好几种方法,其中一种方法是把它们做内积,内积的值越大,从某种角度考虑就代表着两个向量越接近。更新以后的内积值是 \(\textbf w^{\textbf T}_f\textbf w_{t+1}\),更新的 \(\textbf w^{\textbf T}_f\textbf w_{t+1}\) 怎么来的呢?上图已经给出。\(\textbf w_f\) 与 \(\textbf w_t\) 的乘积越来越大,后一轮比前一轮大(\(\textbf w^{\textbf T}_f\textbf w_{t+1}\color{red}>\textbf w^{\textbf T}_f\textbf w_t\)),表示 \(\textbf w_f\) 与 \(\textbf w_t\) 这两个向量越来越接近。所以,我们经过PLA以后,两个向量越来越接近。数学比较好的同学可能就会质疑,老师你说得不对,两个向量的内积越来越大,你没有考虑两个向量的模长。两个长度很长的向量,内积如果是正的也有可能越来越大。所以此时,你会怀疑这两个向量不是真的角度上的接近,而是因为长度的问题。
所以,我们在PLA的过程中找的那个向量 \(\textbf w_t\) 看似跟我们梦想中的向量 \(\textbf w_f\) 越来越接近了。但是我们还要考虑向量长度因素。

我们要使用到的关键是这样,大家看到说我们在上一页里面,我们只说我们拿 \(\textbf x\) 来更新而已。实际上我们还没有用到PLA最重要的一个性质:我们有错才更新。有错什么意思?有错就是说,如果我把 \(\textbf w^T_t\textbf x_{n(t)}\) 这两个向量的乘积的符号跟 \(\textbf y_{n(t)}\) 做比较,这两个的符号是不一样的,就叫做有错。那或者我们用一个更简洁的表示的话,我们如果 \(\textbf y_{n(t)}\textbf w^T_t\textbf x_{n(t)}\leqslant 0\),即它们异号,异号的意思就是说,这些通通乘起来会小于等于0。我们现在来用到这个性质,那这个性质看什么呢?我们看 \(\textbf w_{t+1}\),就是 \(\textbf w_t\) 跟那个更新的那两部分。我们如果看它的长度,或说它的长度的平方的话,会发现里面有 \(\textbf w_t\) 和 \(\textbf y_{n(t)}\textbf x_{n(t)}\) 两项。两项平方后,拆成三项。中间蓝色部分那项我们用上边黄色区域的蓝色部分替换,\(\color{blue}{\textbf y_{n(t)}\textbf w^T_t\textbf x_{n(t)}\leqslant 0}\) 代表什么?代表我们只有犯错才更新的话,我们的 \(\textbf w_t\) 是不会成长太快的,因为它会加上一个负的项上去,它就不会成长太快,它会成长只会靠哪个项成长呢?只会靠最后这个我们标记成红色的 \(\color{red}{\left \| \textbf y_{n(t)}\textbf x_{n(t)} \right \|^2}\) 这项成长,中间这项 \(\color{blue}{\textbf y_{n(t)}\textbf w^T_t\textbf x_{n(t)}\leqslant 0}\) 不会给 \(\textbf w_t\) 任何的成长。那这个红色的这项最后会怎么样呢?红色这项是我们随便选的一个犯错误的点,我们可以把它跟所有资料里面的点来做比较,也许是跟最远的那个(即最长)点做比较,我们会有这样的不等式 \(\color{red}{\left \| \textbf y_{n(t)}\textbf x_{n(t)} \right \|^2\leqslant \underset{n}{\textbf {max}}\color{red}{\left \| \color{gray}{\textbf y_n}\textbf x_n \right \|^2}}\),因为任何一个点会比最长的那个点的长度平方还来的小。大家注意到灰色的 \(\color{gray}{\textbf y_n}\),因为我们前边讲过它的值为+1或-1,所以+1或-1的平方没有差,对长度的影响没有差别。重要的是 \(\color{red}{\left \| \textbf x_n \right \|^2}\),所以我们与最大的这个 \(\color{red}{\underset{n}{\textbf {max}} \left \| \textbf x_n \right \|^2}\) 作比较。然后我们就发现说,\(\textbf w_t\) 每次最多长多长呢?最多就长最长的 \(\color{red}{\left \| \textbf x_n \right \|^2}\) (\(\color{red}{\underset{n}{\textbf {max}} \left \| \textbf x_n \right \|^2}\))这么多,其它项都不是正的,只有这一项是正的,最多最多就长这么多。
所以前一页说 \(\textbf w_t\) 和 \(\textbf w_f\) 越来越靠近,每次都靠近一定的份量。这一页说 \(\textbf w_t\) 满满地长,如果我们把这两页结果合起来,那我这个留给大家做练习,可能要拿出一张纸来把这两个结果写下来。你会发现,如果你从这个0开始一路做更新,做了 T 个更新之后,你看 \(\textbf w_t\) 和 \(\textbf w_f\) 这两个向量分别正规化之后的内积(正规化其实就是单位化,两个向量的正规化内积其实就是这两个向量夹角的余弦值),我们把 \(\textbf w_f\) 我们想象的那个理想的东西正规化,我们把经过 T 次更新后,我们得到的那个 \(\textbf w_t\) 也正规化,这两个正规化的向量的乘积会大于等于根号 T 乘上某个常数,当然大家花点力气去把这个常数是什么写出来。两个向量的正规化的内积代表这两个向量的角度有多靠近,如果这个角度记为 $\theta $,两个向量的正规化的内积就是 \(\cos \theta\)。 \(\textbf w_t\) 和 \(\textbf w_f\) 越来越靠近,每一轮经过一次更新,就靠近一点点,靠近的速度大概是你更新的次数 T 开根号这样的比例。那 \(\textbf w_t\) 和 \(\textbf w_f\) 可不可能无限次的靠近?不可能,因为两个向量的正规化的内积最大为1,即 \(\left| \cos \theta \right| \leqslant 1\),所以我们证明了这个演算法会停下来。

我们这边留给大家一个练习,确保说大家有听得懂我们刚才在推导的是什么样的东西。这个练习是这样子,我们的PLA到底要更新几次才会停下来?也就是与 T 有关的信息是什么?这个 T 实际上根据我们刚才的推导是可以算出来的,那我们这边定义两个东西。一个叫做 R 的平方,这个 R 的平方大家看到说有人把它叫做半径的平方,也就是说你每一个向量的长度,最大的那个向量的长度的平方。另一个叫做 \(\rho\),这个 \(\rho\) 是什么呢?是我们想要的目标那条线 \(\textbf w_f\) 的法向量 \(\frac{\textbf w_f^T}{\left \| \textbf w_f \right \|}\),然后跟每个点的内积,然后根据它的 \(\textbf y_n\) 是+1还是-1看看在哪个方向,如果是线性可分的,那么 \(\rho\) 一定是大于0的,一定是正的。我们就用这两个定义来算算看,PLA到底最多更新几次就会停。

如果你跑了 T 次
\[\because \sqrt{T}*constant \leqslant \frac{\textbf w_f^T}{\left \| \textbf w_f \right \|} \frac{\textbf w_t}{\left \| \textbf w_t \right \|} = \cos \theta \leqslant 1\]
\[\therefore \sqrt{T}*constant \leqslant 1\]
\[\therefore T \leqslant \frac{1}{constant^2}\]
\[其中 \frac{1}{constant^2} = \frac{\textbf R^2}{\rho^2}\]
\(\frac{1}{constant^2} = \frac{\textbf R^2}{\rho^2}\),这个数字就是最多最多更新(迭代/轮)的数字。我们的参考答案就是2。

所以,我们已经证明了PLA演算法会停。这里稍微总结一下,我们说如果你的资料是线性可分,然后PLA这个演算法是每一次挑一个错出来修正。线性可分告诉我们告诉我们 \(\textbf w_t\) 和 \(\textbf w_f\) 会越来越接近;用错误的点来修正代表说我们 \(\textbf w_t\) 的长度会缓慢的成长。所以我们刚才融合这两个结果,我们证明了PLA会停下来。
那这样延伸的好处是什么?这样延伸的好处是太简单了!我们前边讲代码量不到二十行,然后它其实蛮快的。然后我们刚才虽然都只在二维给大家看,但是大家可以想象说这里都是向量的运算,实际上你要做二维跟做一百维是类似的意思,只是二维的的五十倍时间而已,但是,整个演算法的精髓是一样的,它并没有用到很特殊的几何性质说二维要怎么做,三维要另外做,四维要另外做。二维或一百维对于程式来说都是差不多的。
坏处是什么?坏处是我们要先假设这个资料是线性可分。这是一个假设,如果这个假设不成立的话,PLA根本就跑不完。但是我现在问问大家,我们知不知道这个假设对不对?我给大家的答案是不知道。为什么?我们这个假设是什么?要有 \(\textbf w_f\),那如果你已经知道 \(\textbf w_f\) 的话,你还做PLA干什么呢?所以我们要知道这个假设对不对,我们就要找一个 \(\textbf w_f\) 出来,这样就陷入了一个循环论证。所以我们一开始是不知道 \(\textbf w_f\) 是什么,既然不知道 \(\textbf w_f\) 是什么,我们在拿到资料的时候,某种角度我们是不知道PLA会不会停。另外,就算我们欺骗我们自己说有一个 \(\textbf w_f\),那我问你,PLA多久会停下来?你说在 \(T \leqslant \frac{1}{constant^2} = \frac{\textbf R^2}{\rho^2}\) 这个上限一定会停下来,这是我们刚刚推算过的。
\[\textbf R^2=\underset{n}{\textbf{max}}\left\| \textbf x_n \right\|^2\]
\[\rho=\underset{n}{\textbf{min}\textbf y_n}\frac{\textbf w_f^T}{\left \| \textbf w_f \right \|}\textbf x_n\]
\(\textbf R\) 从你的资料的长度可以算出。那 \(\rho\) 怎么算出? \(\rho\) 的计算需要 \(\textbf w_f\),而 \(\textbf w_f\) 我们是不知道的。所以你不但不知道PLA会不会停,就算你欺骗自己说PLA会停,你也不知道它多久会停。我们推导了PLA会停,但是实际上,这部分我们是不确定的,你只能让PLA一直跑,然后停了你很高兴,如果不停的话,要么就是还没跑够,要么就是这个资料根本不是线性可分。所以,PLA正真在使用的时候是有一些麻烦的地方。如果你的资料根本不是线性可分怎么办?这是更大的问题哦!现实的资料,你怎么知道它一定是线性可分或一定不是线性可分?
当然要解决这个问题,我们先跟大家讲说我们在机器学习的设定并不是真的这么死硬的说我们拿到了资料,一定是从我们的目标函数 f 很完整的这样产生出来的。搞不好我们在产生资料、收集资料的过程中,有一些杂讯那也不一定。例如说我们判断要不要给这个人信用卡?但是之前理财专员弄错了一些东西,导致我们的资料里面可能有杂讯(不真实的数据、资料)。如果用我们原来的机器学习的整个框架,杂讯发生在图中的第一阶段。所以我们要一个目标函数,不过我们要知道我们取得资料的过程可能是有杂讯的。有杂讯的意思是什么呢?就算我们原来的 f 是一条线,我拿到的资料 D 也不见得是线性可分。那我们现在跟大家讲,有没有什么方法在我们不确定我们的资料是不是线性可分的状况下,在可能有杂讯的状况下,还是找到一条好的线呢。
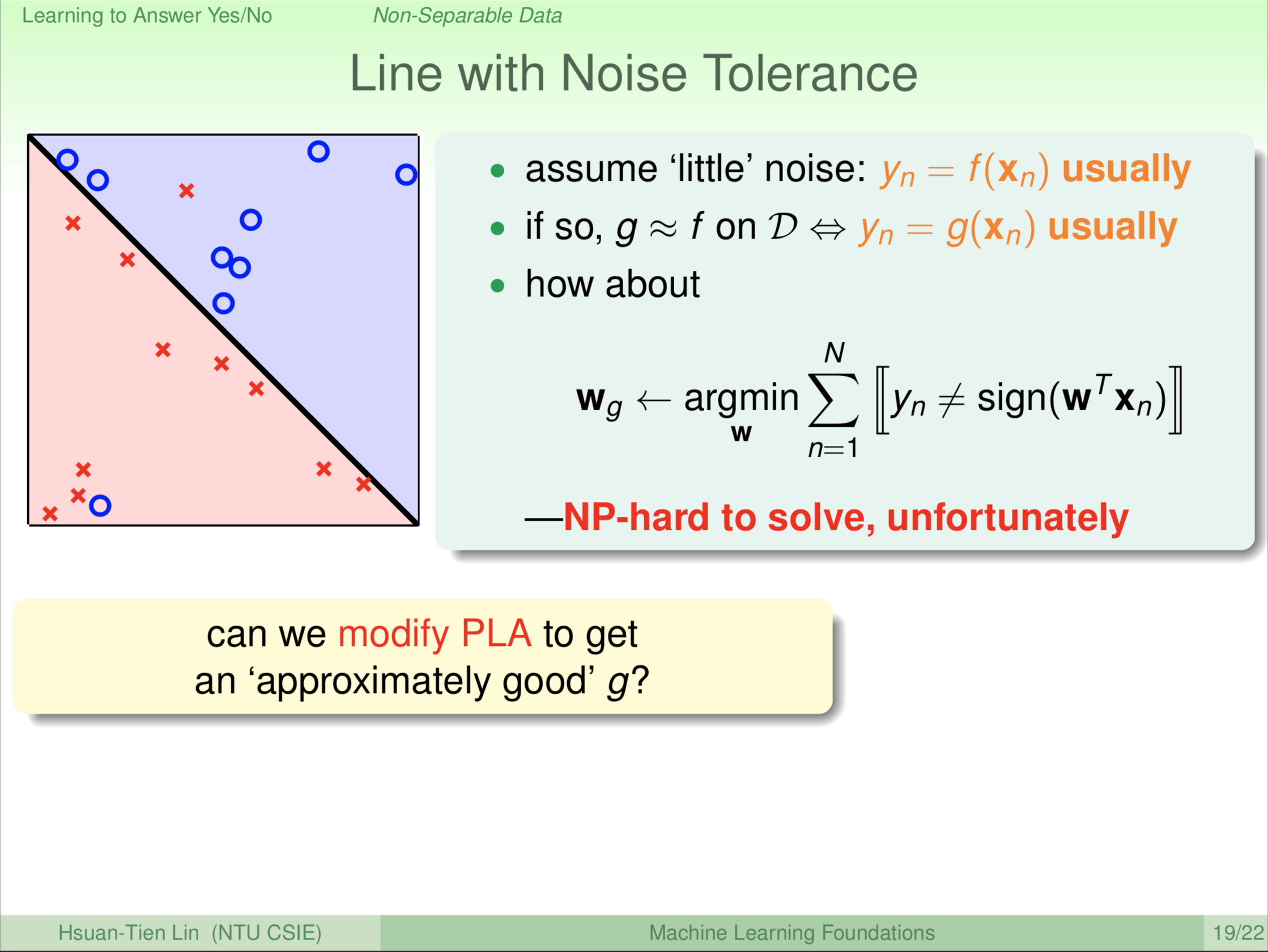
我们不知道 f ,也不知道杂讯是什么。所以我们只能在我们知道的资料 D 上面看看发生什么事。大部分的时候,杂讯很小。如果杂讯很大的话,你干脆去学杂讯就好了,不用学 f。所以杂讯相对于你真正想学的 f 应该是小的,小的状况下代表什么?代表我们在我们的资料上,y 跟 f 要有一定的对应程度。y 跟 f ,如果拿 f 作用到 \(\textbf x\) 上面的话,我应该要得到大部分的时候看到的 \(\textbf y_n\)。
所以如果我们要找一个 g 跟 f 很像的话,也应该满足说我们看到的 \(\textbf y_n\) 跟 g 预测出来的这个标签也要非常的相像。
也就是什么呢?干脆我们找一条犯错误最少的线,我们现在还没有办法找到不犯错误的线。我们把犯错误最少的这条线记为 g,所以这是退而求其次。其实刚才我们在PLA的时候我们说执行一阵子后,一定能够找到一条完美的线。现在我们假设我们找不到一条完美的线,那干脆我们就找一条最好的线。我们定义说最好就是在我们所看过的资料上犯错误最少。我们要找到犯错误最少,大家看到我这个符号,我这边有 \(\textbf y_n\) 不等于这个 sign,我这边用这个方框代表布林运算。然后我们算说这边是我总共犯了多少错误,我在所有的可能的 \(\textbf w\) 里面选一个犯错误最小的当作我的 \(\textbf w_g\)。你会写程式解决这个问题吗?如果你说你会,你有一个非常非常有效率的方法解决这个问题,赶快来跟我讲。为什么呢?因为这个问题在电脑科学里面已经被证明是一个 NP-hard 的问题,电脑科学的从业者可能比较熟悉这个名词是什么意思。如果有不懂的人,我们就把它想成是一个很难很难,几十年来电脑科学家都没有办法解决的问题,所以我说,如果你真的有一个好的解法,赶快来跟我讲。我们搞不好合作一下,然后看看能不能解决这个千古的悬题。不过机会大概不太大,目前还没有什么很有效率的演算法来解决这个问题。那糟糕了!你说老师你列了一个问题,结果又告诉我们这个问题不能解。那这学期课是不是结束了?反正我们不能解。在这么难的问题下,机器学习的科学家或以前的一些电脑科学家就设计了一些演算法。这些演算法没有办法完美的解决这个问题,不过做的还不错。我们现在就跟大家介绍一个简单的演算法,这个演算法实际上可以看成是我们刚才学过的 PLA 的一个变形。找一条差不多很好的线,不见得是最完美的那条线,但是差不多很好的线。

怎么做呢?我们的做法是一个有一点点贪心的做法。我们说我们刚才会PLA啊!PLA不就是一直跑,找到一个错误的点修正一下,找到一个错误的点修正一下。如果我们相信在这个修正的过程中,我们总会碰到一条还不错的线的话,那我们可以做这样的事情。这件事有一点像小孩子,一个贪心的小孩手上拿一个他觉得最好玩的玩具,然后看到新玩具,觉得那个更好玩,就把手上的玩具丢掉,把新的玩具抓在手上。他一直把他觉得最好玩的玩具抓在手上。我们现在也是一样,我们把什么东西抓在手上?把我们觉得最好的那条线抓在手上或者传统上这个演算法叫 Pocket,Pocket 是口袋的意思,放在口袋里。外国人比较含蓄说放在口袋里,我觉得其实就是抓在手上。
所以我们做的事情是什么?我们就跑 PLA 这个演算法,然后跟我们刚刚学的一样,看到一个错误修正一下,看到一个错误修正一下。通常我们在做 Pocket,口袋演算法的时候,我们会用比较随机的更新方式,因为我们想要找到的线多一点点不一样的地方,随机方式一般能够找到一条比较好的。谈后口袋演算法和 PLA 不一样的是什么呢?我们每一次找到一条新的线的时候,我就去看看这一条新的线跟我口袋里的那一条线哪一条比较好。什么叫比较好?犯错误比较少就是比较好。如果新的线比较好,我就把我口袋里的丢掉,放一条新的线在口袋里,就这么简单,所以跟原来的 PLA 长得差不多。差在什么?我抓一条最好的线在口袋里,然后这时候我们就不能确定什么时候停下来,因为这不像 PLA 说不犯错就停下。我们就让它一直跑,一直跑,一直跑,跑到我们觉得跑得够多了,跑得够多代表我们看过够多的线,然后可能里面会有一条蛮好的线,我们再把它停下来。停下来的时候,我们把我们口袋里那条线回传回去。Pocket 就是这样的演算法,所以它跟 PLA 长得非常像,大家可以看到实际上只有两三行的不一样而已。理论的证明我们这边不做介绍。我们想要告诉大家的是,如果你的资料是线性可分的,PLA会做得很好;如果不是线性可分,PLA的一个变形(Pocket,口袋演算法)可能也可以做得还不错。

不过说到这里,我们其实是让同学们想一想说我们拿到一个资料,我们不知道它是不是线性可分。我们有两种选择,一个是我们就去跑 PLA,然后跑到天荒地老,它搞不好都不会停;一个是我们觉得它搞不好不会是线性可分,所以我们就去跑 Pocket,口袋演算法,跑够久的时间,然后看看它停下来变成什么。那我们的问题是,如果我们去跑了口袋演算法(Pocket),结果这个资料真的是线性可分。比起一开始就去跑 PLA,我到底浪费了什么东西?

我希望大家想一想以后发现答案是1。就是Pocket比PLA要慢。慢又两个原因:
- Pocket 要花费时间去存档,把口袋里的东西存起来。
- Pocket 要检查每一条线有没有比较好。大家记得以前PLA的时候,我们就只要找出一个错误的点就好了。Pocket 要检查两条线哪条比较好,它把所有的资料都看过一次才知道我的口袋里面的线比较好,还是新的那个线比较好。所以这会花额外的力气。
所以今天如果是一个线性可分的资料,你说我不要跑PLA,我跑Pocket的话,那你会花额外的计算时间。

今天的课程里面我们进一步跟大家介绍了是非题。我们介绍了一个线性的 hypothesis set,线性的集合,那里面的东西实际上就是我们高维的平面,或者是二维上实际上就是一条线,我们叫 Linear Classify,或者是 Perceptron 感知器。我们介绍了一个跟 hypothesis set 相对应的演算法 PLA。PLA 只在线性可分的时候用。我们证明了 PLA 在线性可分的时候最后会停下来。如果不是线性可分的情况,你可以改成 Pocket,还是可以做得还不错。但这是希望大家对机器学习会有一个比较具体的认识。
下一次课程里面我们会跟大家说机器学习不是只能做是非题,还可以做很多不一样的问题,或很多很多不同的资料形式。
机器学习基石(台湾大学 林轩田),Lecture 2: Learning to Answer Yes/No的更多相关文章
- 机器学习基石(台湾大学 林轩田),Lecture 1: The Learning Problem
课程的讲授从logo出发,logo由四个图案拼接而成,两个大的和两个小的.比较小的两个下一次课程就可能会解释到它们的意思,两个大的可能到课程后期才会解释到它们的意思(提示:红色代表使用机器学习危险,蓝 ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- 林轩田机器学习基石笔记3—Types of Learning
上节课我们主要介绍了解决线性分类问题的一个简单的方法:PLA.PLA能够在平面中选择一条直线将样本数据完全正确分类.而对于线性不可分的情况,可以使用Pocket Algorithm来处理.本节课将主要 ...
- 【The VC Dimension】林轩田机器学习基石
首先回顾上节课末尾引出来的VC Bound概念,对于机器学习来说,VC dimension理论到底有啥用. 三点: 1. 如果有Break Point证明是一个好的假设集合 2. 如果N足够大,那么E ...
- 【 Logistic Regression 】林轩田机器学习基石
这里提出Logistic Regression的角度是Soft Binary Classification.输出限定在0~1之间,用于表示可能发生positive的概率. 具体的做法是在Linear ...
- 【Linear Regression】林轩田机器学习基石
这一节开始讲基础的Linear Regression算法. (1)Linear Regression的假设空间变成了实数域 (2)Linear Regression的目标是找到使得残差更小的分割线(超 ...
- 【Theory of Generalization】林轩田机器学习基石
紧接上一讲的Break Point of H.有一个非常intuition的结论,如果break point在k取到了,那么k+1, k+2,... 都是break point. 那么除此之外,我们还 ...
- 【Training versus Testing】林轩田机器学习基石
接着上一讲留下的关子,机器学习是否可行与假设集合H的数量M的关系. 机器学习是否可行的两个关键点: 1. Ein(g)是否足够小(在训练集上的表现是否出色) 2. Eout(g)是否与Ein(g)足够 ...
- 【Feasibility of Learning】林轩田机器学习基石
这一节的核心内容在于如何由hoeffding不等式 关联到机器学习的可行性. 这个PAC很形象又准确,描述了“当前的可能性大概是正确的”,即某个概率的上届. hoeffding在机器学习上的关联就是: ...
随机推荐
- gcc,make,cmake
1.gcc是GNU Compiler Collection(就是GNU编译器套件),也可以简单认为是编译器,它可以编译很多种编程语言(括C.C++.Objective-C.Fortran.Java等等 ...
- java后端学习路线
java基础-->java设计模式-->java数据结构与算法
- IPVS负载均衡
概念: ipvs (IP Virtual Server) 实现了传输层负载均衡,也就是我们常说的4层LAN交换,作为 Linux 内核的一部分.ipvs运行在主机上,在真实服务器集群前充当负载均衡器. ...
- (转)开源项目miaosha(上)
石墨文档:https://shimo.im/docs/iTDoZs4CVfICgSfV/ (二期)19.开源秒杀项目miaosha解读(上) [课程19]几张图.xmind0.6MB [课程19]开源 ...
- qvalue: Check that you have valid p-values or use a different range of lambda
ERROR: The estimated pi0 <= 0. Check that you have valid p-values or use a different range of lam ...
- python 安装wheel .whl文件
首先得有pip没有的话安装一个. 然后:pip install wheel 然后:pip install 路径\文件名.whl ===================== pip --versionp ...
- oracle单行函数 之 数字函数
Round(数字 \ 列 [,保留小数的位数]):四舍五入 select Round(1234.45,1) from dual = 1234.5 Trunc(数字 \ 列 [,保留小数的位数] ...
- synchronized 关键字如何使用
http://blog.csdn.net/shenshibaoma/article/details/53009505 http://www.importnew.com/20444.html 锁一般分为 ...
- (zhuan) Where can I start with Deep Learning?
Where can I start with Deep Learning? By Rotek Song, Deep Reinforcement Learning/Robotics/Computer V ...
- pyqt笔记2 布局管理
https://zhuanlan.zhihu.com/p/28559136 绝对布局 相关方法setGeometry().move() 箱式布局 QHBoxLayout和QVBoxLayout是基本的 ...