MySQL 查询优化之 Multi-Range Read
MySQL 查询优化之 Multi-Range Read
在存储引擎中未缓存的大表,使用辅助索引的range scan检索数据, 可能会导致基表进行许多随机磁盘访问。
通过磁盘扫描多范围读取(MRR)优化,可以减少随机I/O,并且将随机I/O转化为顺序I/O,提高查询效率
MRR的工作原理
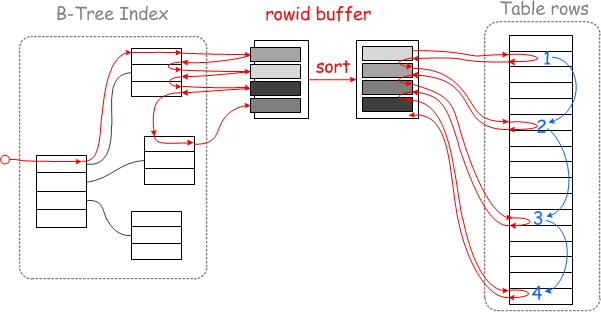
根据辅助索引的叶子结点上找到的主键值得集合存储到read_rnd_buffer中,然后在该buffer中对主键值进行排序,最后再利用已经排序好的主键值的集合,去访问表中的数据,这样就由原来的随机/O变成了顺序I/O,降低了查询过程中的I/O消耗。
SELECT * FROM t WHERE key_part1>=1000 and key_part1<2000 AND key_part2=1000;
表t有(key_part1,key_part2)的联合索引因此索引根据key_part1,key_part2的位置关系进行排序。
若没有MRR,此时查询类型为Range。SQL优化器会先将key_part1>1000 and key_part2<2000的数据线取出来,即使key_part2不等于1000。待取出的行数据后在根据key_part2的条件进行过滤,这会导致无用的数据被取出,如果有大量的数据且其key_part2不等于1000,则启用MRR优化会使性能有巨大的提升
启用MRR优化,优化器会先将查询条件进行拆分,然后在进行数据查询。上述语句,优化器会将查询条件拆分为(1000,1000),(1001,1000),(1002,1000),...,(1999,1000),然后在根据这些拆分出的条件进行数据查询
MRR开启与关闭
通过参数 optimizer_switch 的标记来控制是否使用MRR
当设置
mrr=on时,表示启用MRR优化。mrr_cost_based表示是否通过cost base基于成本的方式来启用MRR如果选择mrr=on,mrr_cost_based=off,则表示总是开启MRR优化,参数read_rnd_buffer_size 用来控制键值缓冲区的大小。
默认情况下:
mrr=on,mrr_cost_based=on
使用MRR示例
使用MRR时,EXPLAIN输出中的Extra列显示Using MRR。
mysql> show index from salaries;
+----------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| salaries | 0 | PRIMARY | 1 | emp_no | A | 300557 | NULL | NULL | | BTREE | | |
| salaries | 0 | PRIMARY | 2 | from_date | A | 2838426 | NULL | NULL | | BTREE | | |
| salaries | 1 | emp_no | 1 | emp_no | A | 299974 | NULL | NULL | | BTREE | | |
| salaries | 1 | idx_salary | 1 | salary | A | 73229 | NULL | NULL | | BTREE | | |
+----------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
4 rows in set (0.00 sec) 默认使用的是mrr=on,mrr_cost_based=on mysql> explain select * from salaries s where s.salary between 68000 and 70000;
+----+-------------+-------+------------+-------+---------------+------------+---------+------+--------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------+---------+------+--------+----------+-----------------------+
| 1 | SIMPLE | s | NULL | range | idx_salary | idx_salary | 4 | NULL | 222726 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+------------+---------+------+--------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec) 设置总是开启mrr mysql> set optimizer_switch='mrr=on,mrr_cost_based=off';
Query OK, 0 rows affected (0.00 sec) mysql> explain select * from salaries s where s.salary between 68000 and 70000;
+----+-------------+-------+------------+-------+---------------+------------+---------+------+--------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------+---------+------+--------+----------+----------------------------------+
| 1 | SIMPLE | s | NULL | range | idx_salary | idx_salary | 4 | NULL | 222726 | 100.00 | Using index condition; Using MRR |
+----+-------------+-------+------------+-------+---------------+------------+---------+------+--------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
参考文档
https://dev.mysql.com/doc/refman/5.7/en/mrr-optimization.html
https://www.cnblogs.com/vadim/p/7403544.html
MySQL 查询优化之 Multi-Range Read的更多相关文章
- Atitit Mysql查询优化器 存取类型 范围存取类型 索引存取类型 AND or的分析
Atitit Mysql查询优化器 存取类型 范围存取类型 索引存取类型 AND or的分析 Atitit Mysql查询优化器 存取类型 范围存取类型 索引存取类型 AND or的分析1 存 ...
- MySQL查询优化之explain的深入解析
在分析查询性能时,考虑EXPLAIN关键字同样很管用.EXPLAIN关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作.以及MySQL成功返回结果集需要执行的行数.expla ...
- Mysql查询优化器
Mysql查询优化器 本文的目的主要是通过告诉大家,查询优化器为我们做了那些工作,我们怎么做,才能使查询优化器对我们的sql进行优化,以及启示我们sql语句怎么写,才能更有效率.那么到底mysql到底 ...
- MySQL查询优化之explain
在分析查询性能时,考虑EXPLAIN关键字同样很管用.EXPLAIN关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作.以及MySQL成功返回结果集需要执行的行数.expla ...
- Mysql查询优化器浅析
--Mysql查询优化器浅析 -----------------------------2014/06/11 1 定义 Mysql查询优化器的工作是为查询语句选择合适的执行路径.查询优化器的代码 ...
- MySQL查询优化之explain详解
MySQL explain命令显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: ...
- (转)支持Multi Range Read索引优化
支持Multi Range Read索引优化 原文:http://book.51cto.com/art/201701/529465.htm http://book.51cto.com/art/2016 ...
- MySQL 查询优化之 Block Nested-Loop 与 Batched Key Access Joins
MySQL 查询优化之 Block Nested-Loop 与 Batched Key Access Joins 在MySQL中,可以使用批量密钥访问(BKA)连接算法,该算法使用对连接表的索引访问和 ...
- MySQL 查询优化之 Index Condition Pushdown
MySQL 查询优化之 Index Condition Pushdown Index Condition Pushdown限制条件 Index Condition Pushdown工作原理 ICP的开 ...
随机推荐
- jvm 调优(转)
转自 http://pengjiaheng.iteye.com/blog/538582 年轻代的设置很关键 JVM中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系 ...
- Date类学习一
- Eclipse - lombok的@Slf4j和@Data无效
问题与分析 最近开始学习spring-boot框架,我用的是Eclipse,然后发现在使用到了lombok的@Data注解时,Eclipse会编译错误.@Data的作用是自动生成toString方法和 ...
- form表单提交转为ajax方式提交
<form action="xxx" method="get"> //action的值是请求的url地址 <div class="f ...
- CSS实现多行文字限制显示
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name ...
- C# 文件操作 全收录 追加、拷贝、删除、移动文件、创建目录、递归删除文件夹及文件....
本文收集了目前最为常用的C#经典操作文件的方法,具体内容如下:C#追加.拷贝.删除.移动文件.创建目录.递归删除文件夹及文件.指定文件夹下 面的所有内容copy到目标文件夹下面.指定文件夹下面的所有内 ...
- python对文件的压缩解压
python自带的zipfile的模块支持对文件的压缩和解压操作 zipfilp.ZipFile 表示创建一个zip对象 zipfile.ZipFile(file[, mode[, compressi ...
- Mysql5.7安装错误处理与主从同步及!
basedir=/iddbs/mysql-5.7.16 datadir=/iddbs/mysql5.7/data3306 一.自定义Mysql.5.7版本免编译安装: 1.Db-server1安装前期 ...
- SimpleDateFormat 如何安全的使用?
前言 为什么会写这篇文章?因为这些天在看<阿里巴巴开发手册详尽版>,没看过的可以关注微信公众号:zhisheng,回复关键字:阿里巴巴开发手册详尽版 就可以获得. 关注我 转载请务必注明 ...
- MySQL在远程访问时非常慢的解决skip-name-resolve
服务器放在局域网内进行测试时,数据库的访问速度还是很快.但当服务器放到外网后,数据库的访问速度就变得非常慢. 后来在网上发现解决方法,my.cnf里面添加 [mysqld] skip-name-res ...