了解Hadoop
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。
Hadoop 的框架最核心的设计就是:HDFS(Hadoop Distributed File System) 和 MapReduce。HDFS 为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
Hadoop 受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。其中 Hadoop 的分布式存储系统 HDFS 对应 Google 的 GFS,而 Hadoop 分布式计算框架 MapReduce 对应 Google 的 MapReduce.
其中 Hadoop 的核心架构如下图1所示:
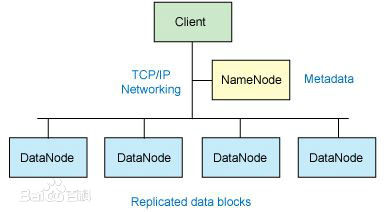
图1 Hadoop 核心架构
显示处理和存储的物理分布的 Hadoop 集群如下图2所示.
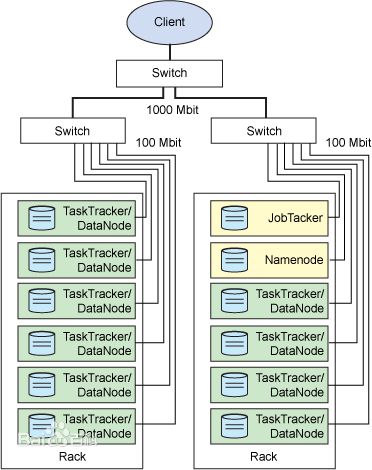
图2 显示处理和存储的物理分布的 Hadoop 集群
目前 Hadoop 主要有两代,分别是 Hadoop1.0 和 Hadoop2.0 (代称). Hadoop 主要由客户端(Client)和服务器端组成, 其中客户端用于提交作业, 服务器端处理客户端提交过来的作业.
这里主要讲的是服务器端. Hadoop 采用 master/slave (主/从)架构, 一个 master, 多个 slaves. 不管 MapReduce 还是 HDFS 都是 master/slave 架构.
Hadoop1.0 与 Hadoop2.0 资源管理方案对比
Hadoop1.0 和 Hadoop2.0 如下图3所示:
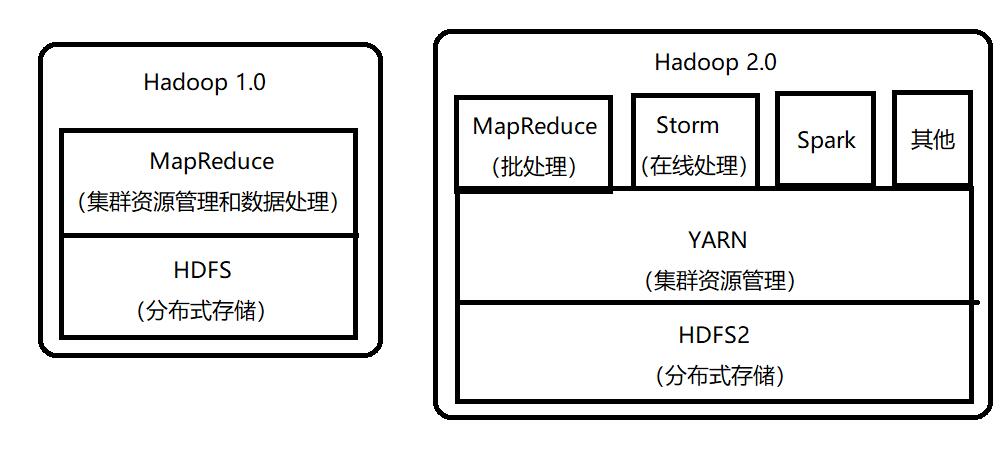
图3 Hadoop1.0 与 Hadoop2.0
1. Hadoop 1.0
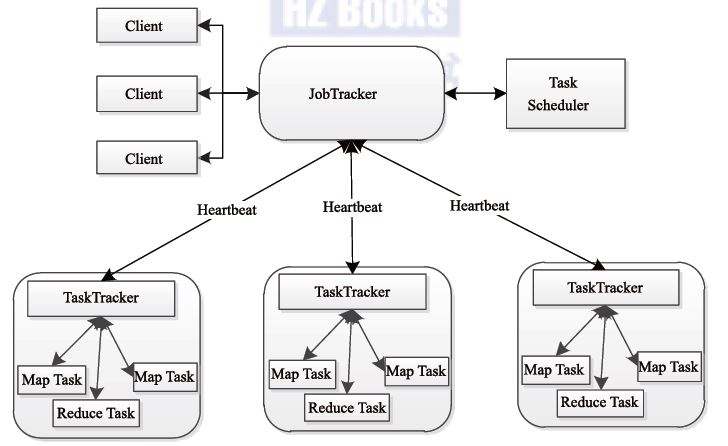
JobTraker : 负责资源管理和所有作业的控制
TaskTracker : 负责接收来自 JobTracker 的命令并执行它
Hadoop1.0 的组件构成如下图4所示:

图4 Hadoop1.0 的组件构成
Hadoop 1.0指的是版本为Apache Hadoop 0.20.x、1.x、0.21.x、0.22.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统组成,其中,MapReduce是一个离线处理框架,由编程模型(新旧API)、运行时环境(JobTracker和TaskTracker)和数据处理引擎(MapTask和ReduceTask)三部分组成。
Hadoop 1.0资源管理由两部分组成:资源表示模型和资源分配模型,其中,资源表示模型用于描述资源的组织方式,Hadoop 1.0采用“槽位”(slot)组织各节点上的资源,而资源分配模型则决定如何将资源分配给各个作业/任务,在Hadoop中,这一部分由一个插拔式的调度器完成。
Hadoop引入了“slot”概念表示各个节点上的计算资源。为了简化资源管理,Hadoop将各个节点上的资源(CPU、内存和磁盘等)等量切分成若干份,每一份用一个slot表示,同时规定一个task可根据实际需要占用多个slot 。通过引入“slot“这一概念,Hadoop将多维度资源抽象简化成一种资源(即slot),从而大大简化了资源管理问题。
更进一步说,slot相当于任务运行“许可证”,一个任务只有得到该“许可证”后,才能够获得运行的机会,这也意味着,每个节点上的slot数目决定了该节点上的最大允许的任务并发度。为了区分Map Task和Reduce Task所用资源量的差异,slot又被分为Map slot和Reduce slot两种,它们分别只能被Map Task和Reduce Task使用。Hadoop集群管理员可根据各个节点硬件配置和应用特点为它们分配不同的map slot数(由参数mapred.tasktracker.map.tasks.maximum指定)和reduce slot数(由参数mapred.tasktrackerreduce.tasks.maximum指定)。
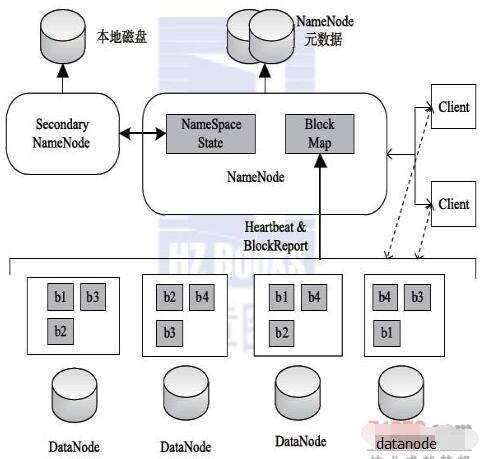
HDFS 的架构如图5, 6所示,总体上采用了 master/slave 架构,主要由以下几个组件组成: Client , NameNode , SecondaryNameNode 和 DataNode.
而官网的 HDFS 架构图如下图6所示:

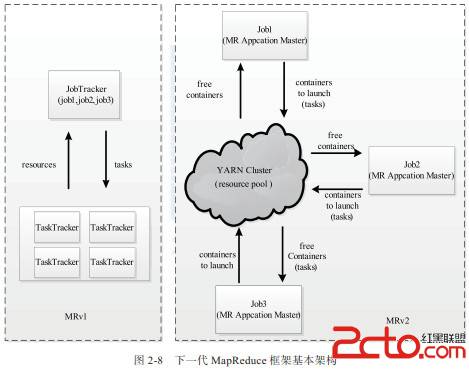
MRv1 架构如下图7所示:同 HDFS 一样, Hadoop MapReduce 也采用了 master/slave 架构, 它主要由以下几个组件组成: Client , JobTracker , TaskTracker 和 Task.
Split 与 block 的对应关系如下图8所示:
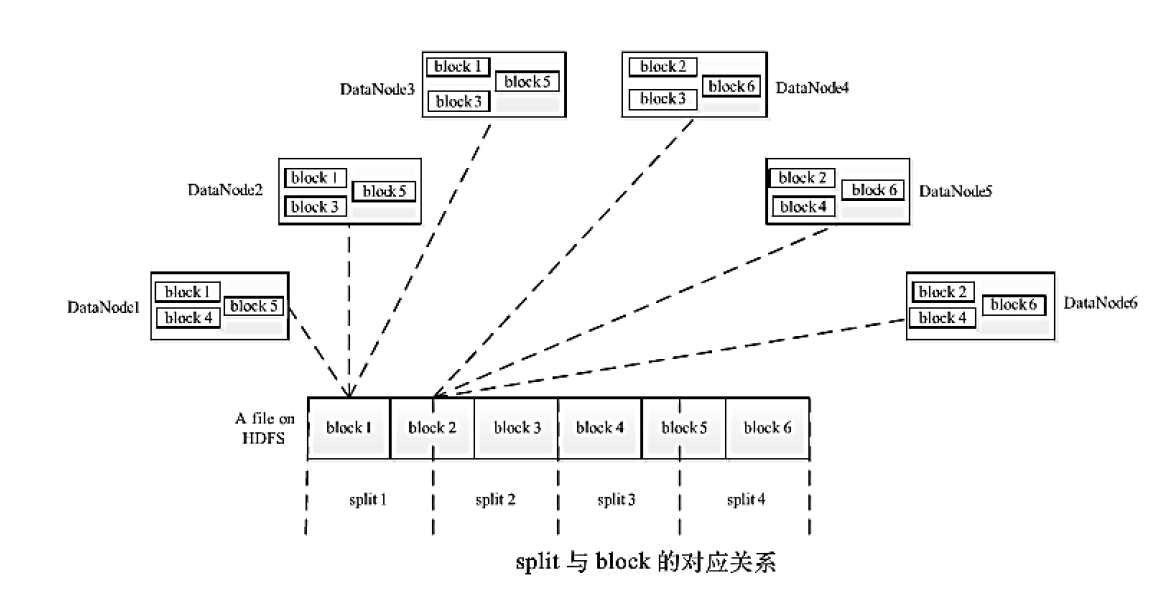
其中 block 是物理划分的, Hadoop1.0 默认块大小是64MB, 而 Hadoop2.0 默认块大小是128MB. 而split是逻辑划分的, 每个 split 对应一个 MapTask . 最好是一个 block 对应一个 split (默认),这样更好满足的本地性. 具体参考 FileInputFormat.getSplits().
Hadoop 运行 MapReduce 作业的工作原理如下图9所示:

图9 Hadoop 运行 MapReduce 作业的工作原理
2. Hadoop 2.0
Hadoop2.0 的组件构成如下图10所示:
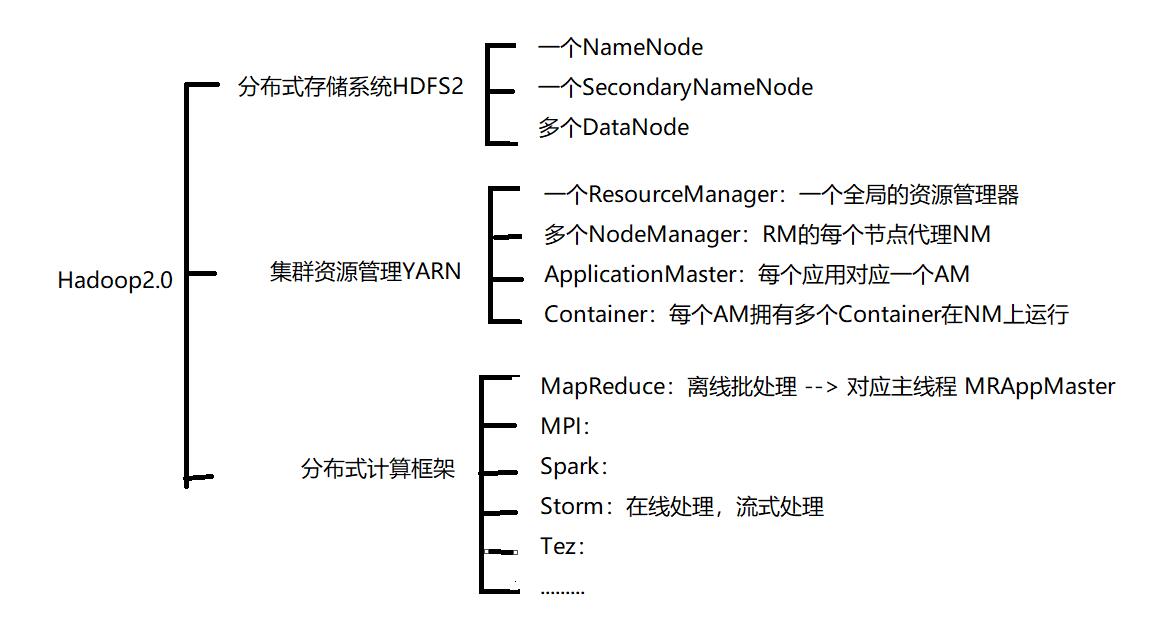
图10 Hadoop2.0 的组件构成
Hadoop 2.0指的是版本为Apache Hadoop 0.23.x、2.x或者CDH4系列的Hadoop,内核主要由HDFS、MapReduce和YARN三个系统组成,其中,YARN 是一个资源管理系统,负责集群资源管理和调度,MapReduce则是运行在YARN上离线处理框架,它与Hadoop 1.0中的MapReduce在编程模型(新旧API)和数据处理引擎(MapTask和ReduceTask)两个方面是相同的。唯一不同的是运行时环境. MRv2的运行时环境不再是由 JobTracker 和 TaskTracker 等服务组成,而是变为通用资源管理系统 YARN 和作业控制进程 ApplicationMaster.
让我们回归到资源分配的本质,即根据任务资源需求为其分配系统中的各类资源。在实际系统中,资源本身是多维度的,包括CPU、内存、网络I/O和磁盘I/O等,因此,如果想精确控制资源分配,不能再有slot的概念,最直接的方法是让任务直接向调度器申请自己需要的资源(比如某个任务可申请1.5GB 内存和1个CPU),而调度器则按照任务实际需求为其精细地分配对应的资源量,不再简单的将一个Slot分配给它,Hadoop 2.0正式采用了这种基于真实资源量的资源分配方案。
官网的 HDFS 架构图如下图11所示(和 Hadoop1.0 的 HDSF 一样,但是也有很多改进):

下一代 MapReduce(MRv2) 框架的基本架构如下图12所示:
Apache Hadoop YARN 架构图(官网)如下图13所示:

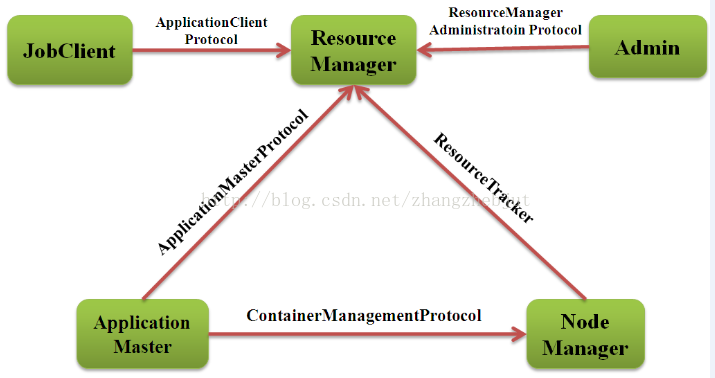
Apache YARN 的 RPC 协议如下图14所示:
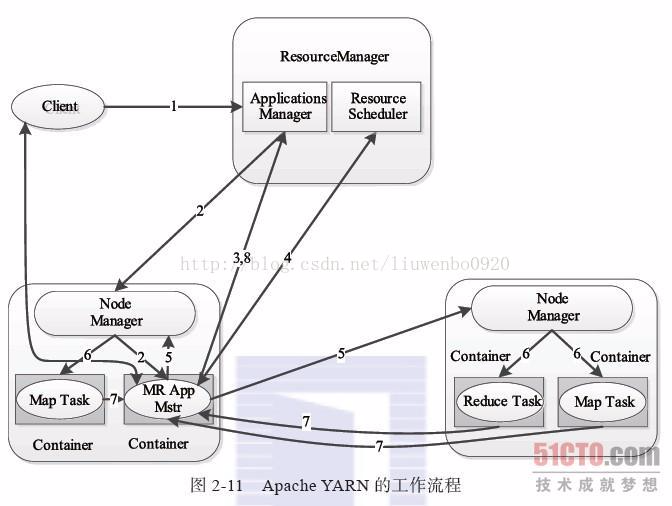
Apache YARN 的工作流程如下图15所示:
Hadoop 使用 YARN 运行 MapReduce 的过程如下图16所示:

图16 Hadoop 使用 YARN 运行 MapReduce 的过程
了解Hadoop的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- 在Linux的Eclipse下搭建Android环境
http://blog.csdn.net/lyonte/article/details/6407242 一.Java环境安装配置详见<在Linux下搭建Java环境>http://blog ...
- Sum It Up POJ 1564 HDU 杭电1258【DFS】
Problem Description Given a specified total t and a list of n integers, find all distinct sums using ...
- [ExtJS5学习笔记]第五节 使用fontawesome给你的extjs5应用添加字体图标
本文地址:http://blog.csdn.net/sushengmiyan/article/details/38458411本文作者:sushengmiyan-------------------- ...
- 【BZOJ3162】独钓寒江雪 树同构+DP
[BZOJ3162]独钓寒江雪 题解:先进行树hash,方法是找重心,如果重心有两个,则新建一个虚点将两个重心连起来,新点即为新树的重心.将重心当做根进行hash,hash函数不能太简单,我的方法是: ...
- EasyDarwin开源流媒体服务器性能瓶颈分析及优化方案设计
EasyDarwin现有架构介绍 EasyDarwin的现有架构对网络事件的处理是这样的,每一个Socket连接在EasyDarwin内部的对应存在形式就是一个Session,不论是RTSP服务对应的 ...
- poj 2154 Color < 组合数学+数论>
链接:http://poj.org/problem?id=2154 题意:给出两个整数 N 和 P,表示 N 个珠子,N种颜色,要求不同的项链数, 结果 %p ~ 思路: 利用polya定理解~定理内 ...
- mongodb学习之:GridFS
GridFS是一种在Mongodb中存储大二进制文件的机制.GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片.音频.视频等). 使用GridFS有如下几个原因: 1 利用 ...
- 时间操作(Java版)—获取给定日期N天后的日期
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/wangshuxuncom/article/details/34896777 获取给定 ...
- virtualbox Units specified don't exist. SHSUCDX can't install.
version infomatin: virtual box: 5.1.12 platform: win10 x64 target OS: win7 x64 问题 在win10系统上,使用virtua ...
- jquery DataTables表格插件的使用(网页数据表格化及分页显示)
DataTables - 非常强大的 jQuery 表格插件,可变宽页码浏览,现场过滤. 多列排序,自动探测数据类型,智能列宽,可从几乎任何数据源获取数据. 那么在Bootstrap下如何使用Data ...