爬虫Scrapy框架-Crawlspider链接提取器与规则解析器
Crawlspider
一:Crawlspider简介
CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能。其中最显著的功能就是”LinkExtractors链接提取器“。Spider是所有爬虫的基类,其设计原则只是为了爬取start_url列表中网页,而从爬取到的网页中提取出的url进行继续的爬取工作使用CrawlSpider更合适。
二:CrawlSpider整体的爬取流程:
a)爬虫文件首先根据其实url,获取该url的网页内容
b)链接提取器会根据提取规则将步骤a中网页内容中的链接进行提取
c)规则解析器会根据指定解析规则将链接提取器中提取到的链接中的网页内容根据指定的规则进行解析
d)将解析数据封装到item中,然后提交给管道进行持久化存储
三:Crawlspider使用
实例:爬取https://www.qiushibaike.com/主页帖子作者以及内容
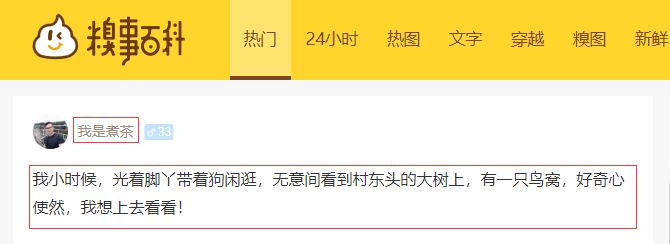
1.创建scrapy工程
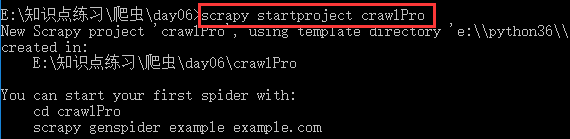
2.创建爬虫文件

注意:对比以前的指令多了 "-t crawl",表示创建的爬虫文件是基于CrawlSpider这个类的,而不再是Spider这个基类。
3.生成的目录结构如下:
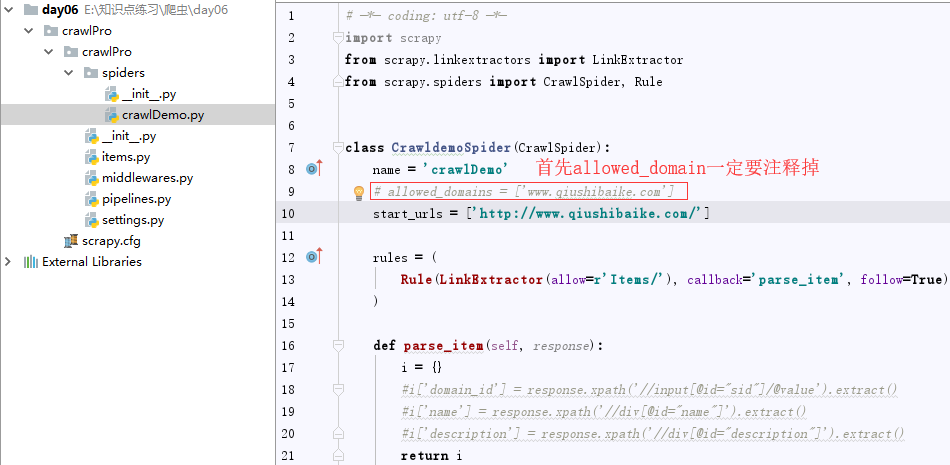
CrawlDemo.py爬虫文件设置:
LinkExtractor:顾名思义,链接提取器。
Rule : 规则解析器。根据链接提取器中提取到的链接,根据指定规则提取解析器链接网页中的内容。
Rule参数介绍:
参数1:指定链接提取器
参数2:指定规则解析器解析数据的规则(回调函数)
参数3:是否将链接提取器继续作用到链接提取器提取出的链接网页中,当callback为None,参数3的默认值为true。
rules=( ):指定不同规则解析器。一个Rule对象表示一种提取规则。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule from crawlPro.items import CrawlproItem
class CrawldemoSpider(CrawlSpider):
name = 'crawlDemo'
# allowed_domains = ['www.qiushibaike.com']
start_urls = ['http://www.qiushibaike.com/']
#rules元祖中存放的是不同规则解析器(封装好了某种解析规则)
rules = (
# Rule: 规则解析器,可以将连接提取器提取到的所有连接表示的页面进行指定规则(有中间的回调函数决定)的解析
#LinkBxtractor:连接提取器,会去上面起始url响应回来的页面中,提取指定的url
Rule(LinkExtractor(allow=r'/8hr/page/\d+'), callback='parse_item', follow=True), #follow=True可以跟进保证将所有页面都提取出来(实际就是去重功能)
) def parse_item(self, response):
# i = {}
# #i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
# #i['name'] = response.xpath('//div[@id="name"]').extract()
# #i['description'] = response.xpath('//div[@id="description"]').extract()
# return i
divs=response.xpath('//div[@id="content-left"]/div')
for div in divs:
item=CrawlproItem()
#提取糗百中段子的作者
item['author'] = div.xpath('./div[@class="author clearfix"]/a[2]/h2/text()').extract_first().strip('\n')
# 提取糗百中段子的内容
item['content'] = div.xpath('.//div[@class="content"]/span/text()').extract_first().strip('\n') yield item #将item提交到管道
item.py文件设置:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class CrawlproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author=scrapy.Field()
content=scrapy.Field()
pipelines.py管道文件设置:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class CrawlproPipeline(object):
def __init__(self):
self.fp = None def open_spider(self,spider):
print('开始爬虫')
self.fp = open('./data.txt','w',encoding='utf-8') def process_item(self, item, spider):
# 将爬虫文件提交的item写入文件进行持久化存储
self.fp.write(item['author']+':'+item['content']+'\n')
return item def close_spider(self,spider):
print('结束爬虫')
self.fp.close()
设置代理:
middlewares.py中间件:
设置代理:ip地址可以通过以下几个链接查找
http://ip.seofangfa.com/
settings.py里面设置:
DOWNLOADER_MIDDLEWARES = {
'crawlPro.middlewares.Mydaili': 543, #Mydaili名字就是中间件里面的类名
}
middlewares.py中间件设置:
class Mydaili(object):
def process_request(self,request,spider):
request.meta['proxy'] = "http://119.28.195.93:8888"
爬虫Scrapy框架-Crawlspider链接提取器与规则解析器的更多相关文章
- 网络爬虫之scrapy框架(CrawlSpider)
一.简介 CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能之外,还派生了其自己独有的更强大的特性和功能.其中最显著的功能就是"LinkExtractor ...
- Scrapy 框架 CrawlSpider 全站数据爬取
CrawlSpider 全站数据爬取 创建 crawlSpider 爬虫文件 scrapy genspider -t crawl chouti www.xxx.com import scrapy fr ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
- 爬虫scrapy框架之CrawlSpider
爬虫scrapy框架之CrawlSpider 引入 提问:如果想要通过爬虫程序去爬取全站数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模 ...
- 全栈爬取-Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- 爬虫Ⅱ:scrapy框架
爬虫Ⅱ:scrapy框架 step5: Scrapy框架初识 Scrapy框架的使用 pySpider 什么是框架: 就是一个具有很强通用性且集成了很多功能的项目模板(可以被应用在各种需求中) scr ...
- Python网络爬虫-Scrapy框架
一.简介 Spider是所有爬虫的基类,其设计原则只是为了爬取start_url列表中网页,而从爬取到的网页中提取出的url进行继续的爬取工作使用CrawlSpider更合适. 二.使用 1.创建sc ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
随机推荐
- linux mount命令详解(iso文件挂载)
挂载命令: mount [-t vfstype] [-o options] device dir mount 是挂载命令 -t + 类型 -o + 属性 device iso的文件 dir 挂 ...
- 【extjs6学习笔记】1.2 初始:MVC MVVM
模型 这表示数据层.该模型可以包含数据验证和逻辑来保持数据.在 ext js 中, 大多数模型都与一个数据存储一起使用. 视图 这表示用户界面. 是用户在屏幕上看到的组件. 在每次互动的用户与应用程序 ...
- 深入理解Java流机制(一)
一.前言 C语言本身没有输入输出语句,而是调用"stdio.h"库中的输入输出函数来实现.同样,C++语言本身也没有输入输出,不过有别于C语言,C++有一个面向对象的I/O流类库& ...
- 加载动画插件spin.js的使用随笔
背景: 在请求后台的“漫长”等待过程中,为了提升用户体验,需要一个类似 的加载动画效果,让用户明确现在处于请求过程中,而不是机子down掉或者网站死了 静态demo(未与后台交互): HTML代码如 ...
- 为了少点击几次,自己写了一个Chrome插件
缘由 chrome应用商店有三款二维码插件,自己一直使用的第一款.这三款插件有且只有一个功能就是生成当前页面的URL的二维码. 其实这个功能基本上满足了需要移动端开发在微信里打开页面进行调试的情况. ...
- Android(java)学习笔记136:利用谷歌API对数据库增删改查(推荐使用)
接下来我们通过项目案例来介绍:这个利用谷歌API对数据库增删改查 1. 首先项目图: 2. 这里的布局文件activity_main.xml: <LinearLayout xmlns:andro ...
- 2018.3.16 Ubuntu 解决中文乱码问题
一.乱码的样子类似: °²Àï¿ü ÒÁ¸ñÀ³Ï£ÑÇ˹,°²Àï¿ü ÒÁ¸ñÀ³Ï£ÑÇ˹ 这种乱码称为Gedit中文乱码 打开部分Windows下的txt文本文件的时候,中文显示为乱码.但 ...
- Java的引用StrongReference、 SoftReference、 WeakReference 、PhantomReference
1. Strong Reference StrongReference 是 Java 的默认引用实现, 它会尽可能长时间的存活于 JVM 内, 当没有任何对象指向它时 GC 执行后将会被回收 @Te ...
- Dede常用标记
http://fontawesome.dashgame.com/ 字体图标使用方法 http://www.iconfont.cn/ 阿里的图标库 https://icomoon.io/ 字体制作 时间 ...
- 01_12_JSP简介
01_12_JSP简介 1. JSP简介 JSP---Java Server Pages 拥有servlet的特性与优点(本身就是一个servlet) 直接在HTML中内嵌JSP代码 JSP程序有JS ...