Python9-模块2-序列化-day20
序列化
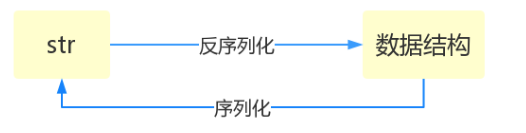
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
序列就是字符串
序列化的目的
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方。
3、使程序更具维护性。
#json模块(*****)
# 通用的序列化格式
# 只有很少的一部分数据类型能够通过json转化成字符串 #pickle模块
#所有的python中的数据类型都可以转化成字符串形式
#pickle序列化的内容只有python能理解
#且部分反序列化依赖代码 #shelve模块
#有了序列化句柄
#使用句柄直接操作
#json dumps(序列化方法) loads (反序列方法)
#可序列化:数字 字符串 列表 字典 元祖(元祖转化列表序列化)
# dic = {'k1':'v1'}
import json
print(type(dic),dic)
str_d = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_d),str_d)
#注意,json转换完的字符串类型的字典中的字符串是由""表示的 dic_d = json.loads(str_d) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(str_d),str_d) # 元祖序列化
dic = (1,2,3,4)
print(type(dic),dic)
str_d = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_d),str_d)
<class 'dict'> {'k1': 'v1'}
<class 'str'> {"k1": "v1"}
<class 'str'> {"k1": "v1"}
#json dump load方法--文件相关的操作
import json
dic = {'k1':'v1'}
f = open('fff','w',encoding='utf-8')
json.dump(dic,f) #将字典序列化然后传到文件中
f.close() import json
f =open('fff')
res = json.load(f)
f.close()
print(type(res),res)
#ensure_ascii=False 参数解决中文问题
import json
dic = {'k1':'中国人','k2':'b'}
f = open('fff','w',encoding='utf-8')
json.dump(dic,f,ensure_ascii=False) #将字典序列化然后传到文件中
f.close()
f =open('fff',encoding='utf-8')
res = json.load(f)
f.close()
print(type(res),res) <class 'dict'> {'k2': 'b', 'k1': '中国人'}
# 一行一行写
l = [{'k':''},{'k':''},{'k':''}]
f = open('file','w')
import json
for dic in l:
str_dic = json.dumps(dic)
f.write(str_dic+'\n')
f.close()
import json
l = []
f = open('file')
for line in f:
dic = json.loads(line.strip())
l.append(dic)
f.close()
print(l)
pickle模块
#pickle
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic)
print(dic2) #字典 import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open('pickle_file','wb')
pickle.dump(struct_time,f)
f.close() f = open('pickle_file','rb')
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01X\x02\x00\x00\x00v1q\x02X\x02\x00\x00\x00k2q\x03X\x02\x00\x00\x00v2q\x04X\x02\x00\x00\x00k3q\x05X\x02\x00\x00\x00v3q\x06u.'
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
#分布dump和load 但是json不行
import time
struct_time1 = time.localtime(1000000000)
struct_time2 = time.localtime(2000000000)
f = open('pickle_file','wb')
pickle.dump(struct_time1,f)
pickle.dump(struct_time2,f)
f.close() f = open('pickle_file','rb')
struct_time1 = pickle.load(f)
struct_time2 = pickle.load(f)
print(struct_time1.tm_year)
print(struct_time2.tm_year)
f.close() 2001
2033
模块导入
demo
print('in demo.py')
money = 100
def read():
print('in read1',money) import demo
money = 200
demo.read()
print(demo.money)
# 先从sys.modules里查看是否已经被导入
# 如果没有被导入,就依据sys.path路径去寻找模块
# 找到了就导入
# 创建这个模块的命名空间
# 执行文件,把文件中的名字放到命名空间里
in demo.py in read1 10
#给模块起别名
import time as t
print(t.time()) # oracle
# mysql
if db == 'oracle':
import oracle as db
elif db == 'mysql':
import mysql as db
# 连接数据库 db.connect
# db.connect
# 登录认证
# 模块导入顺序:先导入内置的,再导入扩展的(别人写好的:django),自定义的模块
#from ....import...
from math import pi
print(pi)
pi =3
print(pi) 3.141592653589793
3
from ....import * 与__all__配合
demo
__all__ = ['money','read']
print('in demo.py')
money = 100
def read():
print('in read1',money)
def read2():
print('in read2') from demo import *
print(money)
read()
总结:
所有的模块导入都应该尽量往上写
遵循内置模块、扩展模块、自定义模块
模块不会重复被导入:sys.moudles
#从哪里导入模块:sys.path
#import
import 模块名
模块名.变量名 和本文件中的变量名完全不冲突
import 模块名 as 重命名的模块名:提高代码的兼容性
import 模块1,模块2(不推荐) #from import
from 模块名 import 变量名
直接使用变量名,就可以完成操作
如果本文件中有相同的变量名会发生冲突
from 模块名 import 变量名 as 重命名的变量名
from 模块名 import 变量名1,变量名2
from 模块名 import *
将模块中的所有变量名都放到内存中
from 模块名 import * 和__all__是一对
没有这个变量就会导入所有的名字
如果有all只导入al列表中的名字 包 一大堆模块的集合
__name__
在模块中有一个变量__name__
当我们直接执行这个模块的时候,__name__的值就等于__main__
当我们执行其他模块。在其他模块中引用这个模块的时候,这个模块中的__name__ == ‘模块的名字’
Python9-模块2-序列化-day20的更多相关文章
- [python](windows)分布式进程问题:pickle模块不能序列化lambda函数
运行错误:_pickle.PicklingError: Can't pickle <function <lambda> at 0x000002BAAEF12F28>: attr ...
- python之路----模块与序列化模块
认识模块 什么是模块 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用pyt ...
- day13 函数模块之序列化 random 模块 os模块 sys模块 hashlib模块 collections模块
json import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串 ...
- python--(常用模块-2序列化)
python--(常用模块-2序列化) 一.序列化: 把对象打散成bytes或者字符串. 方便存储和传输 序列化 把bytes或者字符串转换回对象. 反序列化 # dumps 序列化. 把对象转化成b ...
- Python 常用模块(2) 序列化(pickle,shelve,json,configpaser)
主要内容: 一. 序列化概述 二. pickle模块 三. shelve模块 四. json模块(重点!) 五. configpaser模块 一. 序列化概述1. 序列化: 将字典,列表等内容转换成一 ...
- python基础编程:生成器、迭代器、time模块、序列化模块、反序列化模块、日志模块
目录: 生成器 迭代器 模块 time 序列化 反序列化 日志 一.生成器 列表生成式: a = [1,2,3,3,4,5,6,7,8,9,10] a = [i+1 for i in a ] prin ...
- Python分布式进程报错:pickle模块不能序列化lambda函数
今天在学习到廖老师Python教程的分布式进程时,遇到了一个错误:_pickle.PicklingError: Can't pickle <function <lambda> at ...
- Python模块02/序列化/os模块/sys模块/haslib加密/collections
Python模块02/序列化/os模块/sys模块/haslib加密/collections 内容大纲 1.序列化 2.os模块 3.sys模块 4.haslib加密 5.collections 1. ...
- 模块(序列化(json&pickle)+XML+requests)
一.序列化模块 Python中用于序列化的两个模块: json 跨平台跨语言的数据传输格式,用于[字符串]和 [python基本数据类型] 间进行转换 pickle python内置的数据 ...
- sys模块和序列化模块
import sysprint(sys.version) #查看当前pycharm版本print(sys.path )#返回模块的搜索路径print(sys.platform )#返回操作系统的版本p ...
随机推荐
- django_view操作数据库
1 create def add_area(request): area = Area.objects.create(name='commom',description='a commom area' ...
- C8051F_CAN
CAN总线特点:基于报文编码而非对节点编码,增删节点对系统没有影响,靠干扰稳定性好,速率高. 小工具:CANtool 收发器:CAN总线收发器CTM1050,通信速率1Mbps,至少可连接110个节点 ...
- 打包google浏览器插件到本地
依次打开‘更多工具’--->'扩展程序',或者在google浏览器输入chrome://extensions/网址就可以打开已安装插件页面,在顶部选中‘开发者模式’后就会出现每个插件的ID,这个 ...
- java.lang.IllegalArgumentException: Illegal character in query at index ...解决办法
今天在写智能机器人问答实现的时候遇到了一个问题,就是我发送消息不能输入空格 给我报了一个错误java.lang.IllegalArgumentException: Illegal character ...
- 我喜欢的两个js类实现方式 现在再加上一个 极简主义法
闭包实现 变量是不会变的:) var myApplication = function(){ var name = 'Yuri'; var age = '34'; var status = 'sing ...
- Jenkins环境搭建(6)-修改自动化测试报告的样式
写在最前: 我遇到一个问题,就是导出数据时,接口返回的数据是乱码,乱码如下图所示.问了开发,说是byte数据.这种情况,将response Data数据写入到报告中的话,在jenkins上运行时,提示 ...
- https握手失败案例(一)
OkHttpClient okHttpClient = new OkHttpClient.Builder() .connectTimeout(15, TimeUnit.SECONDS) .read ...
- DataGridView使用技巧(七、设定列宽和行高自动调整)----.NET
DataGridView使用技巧(七.设定列宽和行高自动调整)----.NET 1) 设定行高和列宽自动调整 [VB.NET]' 设定包括Header和所有单元格的列宽自动调整DataGridView ...
- 浅析linux下软件的安装
Linux环境: CentOs 6.0 知识点介绍: 一.tarball安装 安装步骤: 将tarball文件在/usr/local/src目录解压缩 ./configure:这个步骤是建立makef ...
- 企业CIO、CTO必读的34个经典故事
一. 用人之道 去过庙的人都知道,一进庙门,首先是弥陀佛,笑脸迎客,而在他的北面,则是黑口黑脸的韦陀.但相传在很久以前,他们并不在同一个庙里,而是分别掌管不同的庙.弥乐佛热情快乐,所以来的人非常多,但 ...