[Linux] Linux命令行与Shell脚本编程大全 Part.1
终端
- tty(teletypewriters):控制台,早期计算机通过电传打字机作为输入设备
- Console:控制台终端,即显示器
- Ctrl+Alt+T:图形界面终端
- Ctrl+Alt+F2:tty2
- Ctrl+Alt+F1:回到图形界面
- #:root用户(Ctrl+D 或 exit 退出)
- $:普通用户(通过 sudu su 切换到root)
操作
- whoami:用户名
- hostname:电脑名
- date:日期
- ls(list):列出当前目录下的文件和目录
- -a(all):全部文件,包括隐藏文件
- -l:列出详细信息
- -lh(human-readable):适于阅读的
- -t:按文件最近一次修改时间排序
- 不同颜色意义(Ubuntu)
- 蓝色 --> 目录
- 绿色 --> 可执行文件
- 红色 --> 压缩文件
- 浅蓝色 --> 链接文件
- 灰色 --> 其他文件
- Tab:补全命令
- Ctrl + R:查找用过的命令
- history:列出之前用过的命令(!编号:调用命令)
- Ctrl + L:用于清理终端的内容
- Ctrl + D:给终端传递EOF(End Of File 文件结束符)
- Shift + PgUp:向上滚屏
- Shift + PgDn:向下滚屏
- Ctrl + A:光标跳到一行命令开头(Home)
- Ctrl + E:光标跳到一行命令的结尾(End)
- Ctrl + U:删除所有光标左侧的命令字符
- Ctrl + K:删除所有光标右侧的命令字符
- Ctrl + W:删除光标左侧的一个单词
- Ctrl + Y:粘贴删除掉的字符
文件
- 普通文件:文本、声音、程序等
- 特殊文件:设备、目录等
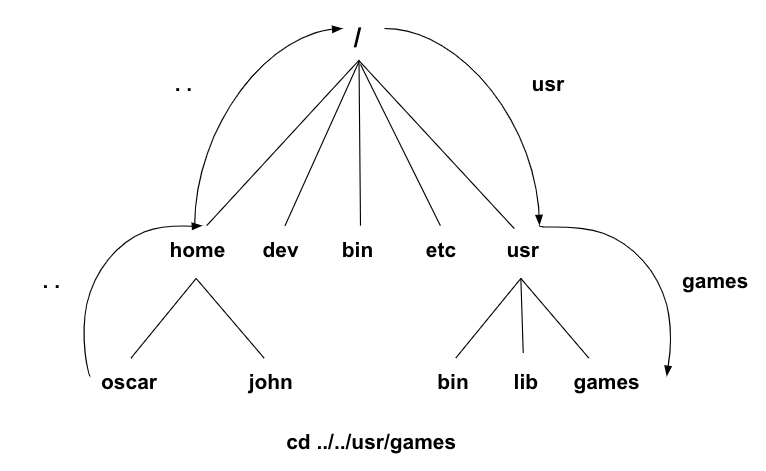
- /:根目录
- ~:家目录(具体位置与用户有关)
- 目录命名时用小写英文字母
- 根目录的直属子目录:
- bin:二进制文件(可执行程序)
- boot:启动相关文件
- dev:设备
- etc:系统配置文件
- home:私人目录,每个用户在home下都有一个私人目录
- lib:库,被程序调用的库文件
- media:媒体
- mnt(mount):挂载点
- opt(optional application software package):可选的应用软件包
- root:超级用户root的家目录(其他用户位于home下)
- sbin(system binary):系统二进制文件,系统级的重要可执行程序
- srv(service):服务
- tmp(tempory):临时的,普通用户存放临时文件的地方
- usr(Unix Software Resource Unix):操作系统软件资源,程序安装处
- var(variable):log文件等
- pwd(Print Working Directory):打印当前工作目录
- which:显示一个命令对应可执行程序的位置
- 命令其实就是一个随时可以被调用的程序
- .(一个点):当前目录
- ..(两个点):上一级目录
- cd(change directory):切换目录(直接cd会返回家目录)
- du(disk usage):磁盘使用
- -h:适合阅读的
- -a:显示文件和目录的大小
- -s(summarize):只显示总大小
- cat(concatenate):把文件连接界起来打印到标准输出
- -n:添加行号
- less:分页显示文件内容
- 空格:前进一页
- 回车:前进一行
- d:前进半页
- b:后退一页
- y:后退一行
- u:后退半页
- q:退出
- head:显示文件头
- tail:显示文件尾
- touch:创建一个空白文件
- mkdir(make directory):创建一个目录
- -p:递归创建目录
- cp(copy):拷贝文件
- -r:递归拷贝目录中所有内容
- mv(move):移动文件或目录,重命名
- rm(remove):删除
- -i:确认是否删除
- -f:强制删除
- -r:递归删除
- ln:创建链接
- ln file1 file2
- 创建 file2 作为 file1的硬连接
- file2指向file1的文件内容(inode)
- 2代表拥有相同inode号的文件数
- 删除一个对另一个没影响
- ln -s file1 file2
- 创建 file2 作为 file1的软连接(快捷方式)
- file2指向file1的文件名
- file1和file2的inode号不一样
- 删除file1后file2就不可用了
- ln file1 file2


- locate:快速查找
- 返回文件路径
- 查找文件数据库,而不是硬盘
- 文件数据库每天更新一次
- sudo update:强制更新
- find:深入查找
- find “何处” “何物” “做什么”
- 何处:指定哪个目录查找
- 何物:找什么(必须)
- 做什么:找到后的后续处理
- 遍历实际硬盘
- -name:指定文件名
- -size:指定大小
- -atime:指定时间
- -type d:只查找目录
- -type f:只查找文件
- -printf:打印
- -delete:删除
- -exec:对找到的文件进行操作
- grep:筛选数据
- Globally search a Regular Expression and Print
- 全局搜索一个正则表达式并打印
- 在文件中查找关键字并显示其所在的行
- -i:忽略大小写
- -n:显示行号
- -v:显示文本不在的行
- -r:在所有子目录和子文件中查找
- -E:使用正则表达式
- sort:文件排序
- -o:将排序后内容写入新文件
- -r:反排序
- -R:随机排序
- -n:对数字排序
- wc:文件统计
- word count
- 行数,单词数,字节数
- -l:统计行数
- -w:统计单词数
- -c:统计字节数
- -m:统计字符数
- uniq:删除文件重复内容
- -c:统计重复行数
- -d:只显示重复行的值
- cut:剪切文件部分内容
- -c:根据字符数剪切
- 重定向
- >:将命令的输出结果重定向到指定文件中(覆写)
- cut -d , -f 1 notes.csv > students.txt
- >>:将命令的输出结果重定向到指定文件的末尾
- 2>:将标准错误输出重定向到指定文件中(覆写)
- cat not_exist_file.csv > results.txt 2> errors.log
- 将标准输出重定向到 results.txt 文件中
- 将标准错误输出重定向到 errors.log 文件中
- 假如 not_exist_file.csv 这个文件确实存在,将其内容写入 results.txt 文件中
- 假如 not_exist_file.csv 这个文件不存在,将错误信息写入 errors.log 文件中
- 2>>:将标准错误输出重定向到指定文件的末尾
- 2>&1:合并输出
- cat not_exist_file.csv > results.txt 2>&1
- 将所有输出(标准输出和标准错误输出)都重定向到 results.txt 文件中
- cat not_exist_file.csv >> results.txt 2>&1
- 追加错误信息到 results.txt 文件中
- <:从文件读取
- cat < notes.csv
- 效果和 cat notes.csv 一样
- <<:将键盘的输入重定向为某个命令的输入
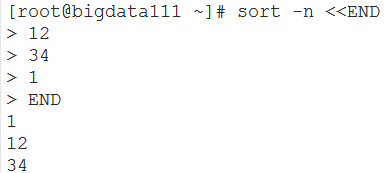
- sort -n << END
- 从键盘输入字符并排序,END结束
- sort -n << END > numbers_sorted.txt 2>&1
- 将排序结果连同错误信息都输出到numbers_sorted.txt
- >:将命令的输出结果重定向到指定文件中(覆写)

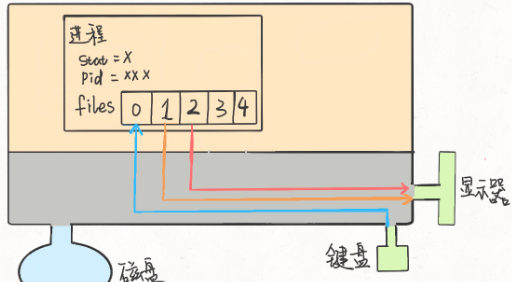
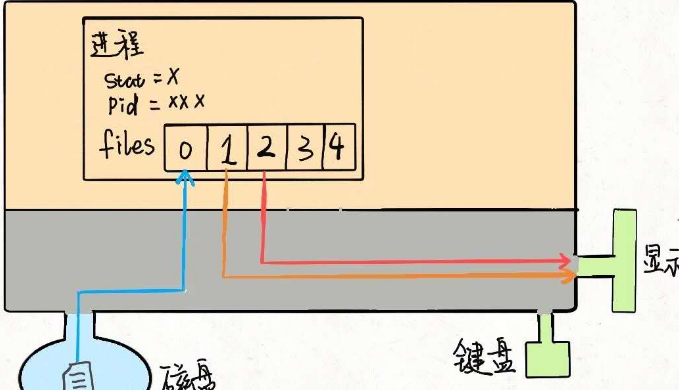

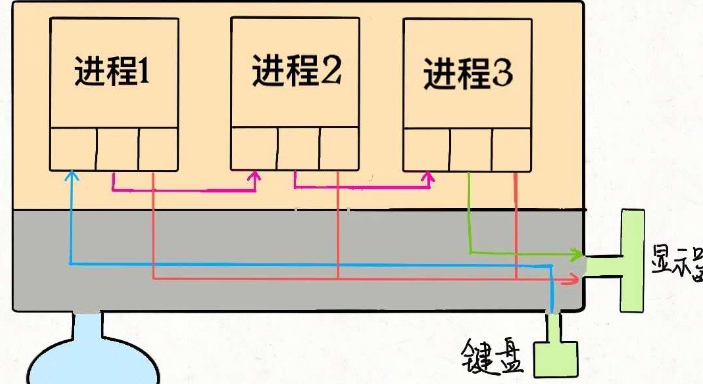
- 管道
- 命令1的输出变成命令2的输入
- cut -d , -f 1 notes.csv | sort > sorted_names.txt
- 剪切文件部分内容并排序输出到另一个文件
- du | sort -nr | head
- 查看当前目录下按参数排序的前十个子目录
- sudo grep log -Ir /var/log | cut -d : -f 1 | sort | uniq
- sudo grep log -Ir /var/log :遍历 /var/log 这个目录及其子目录,列出所有包含 log 关键字的行
- cut -d : -f 1 :从输出结果中只剪切出文件名那一列(由冒号分隔)
- sort :将文件名的列以首字母的字典顺序进行排序
- uniq :去掉重复的文件名
参考
Linux命令大全
[Linux] Linux命令行与Shell脚本编程大全 Part.1的更多相关文章
- Linux命令行与shell脚本编程大全.第3版(文字版) 超清文字-非扫描版 [免积分、免登录]
此处免费下载,无需账号,无需登录,无需积分.收集自互联网,侵权通知删除. 点击下载:Linux命令行与shell脚本编程大全.第3版 (大小:约22M)
- 《Linux命令行与shell脚本编程大全 第3版》创建实用的脚本---11
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》高级Shell脚本编程---47
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Shell脚本编程基础---57
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---57
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---56
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---55
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---54
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---53
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---52
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
随机推荐
- Docker备份Gitlab容器以及还原数据
概述 今天,我们将学习如何快速地对docker容器进行快捷备份.恢复和迁移.Docker是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包.发布和运行这些应用.它使得 ...
- 快速排序(QuickSort)Java版
快速排序 快速排序是对冒泡排序的一种改进. 它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排 ...
- Dynamics CRM实体系列之窗体
本节开始讲Dynamics CRM的窗体排版和设计,窗体也就是我们实际可以看到的表单界面.Dynamics CRM提供了一套独立的表单模板设计引擎,可以很方便的为开发者提供无代码开发,只需要简单的拖动 ...
- AutoAssign源码分析
目录 AutoAssign源码分析 一. 简介 二. 论文理论 2.1 联合表示 2.2 正样本权重 2.3 负样本权重 2.4 总的loss 2.5 补充loss 三. 论文代码 四. 总结 五. ...
- NPM 与 NPX 区别
NPM 和 NPX 区别 NPM Node Package Manager npm 是 Node.js 的软件包管理器,其目标是自动化的依赖性和软件包管理 NPX npx 是执行 Node 软件包的工 ...
- MQ 入门实践
MQ Message Queue,消息队列,FIFO 结构. 例如电商平台,在用户支付订单后执行对应的操作: 优点: 异步 削峰 解耦 缺点 增加系统复杂性 数据一致性 可用性 JMS Java Me ...
- 「HTML+CSS」--自定义加载动画【016】
前言 Hello!小伙伴! 首先非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出- 哈哈 自我介绍一下 昵称:海轰 标签:程序猿一只|C++选手|学生 简介:因C语言结识编程,随后转入计算机 ...
- 解决Linux无法读写U盘中的NTFS问题
1 问题描述 由于笔者因为某些需要把Windows装在了U盘上面(在这里建议一下如果有需要请使用固态U盘),在Linux下挂载时,能读取但并不能写. 2 尝试的解决方案 2.1 remount 一开始 ...
- 13.Quick QML-RowLayout、ColumnLayout、GridLayout布局管理器介绍、并通过GridLayout设计的简易网站导航界面
上章我们学习了:12.Quick QML-QML 布局(Row.Column.Grid.Flow和嵌套布局) .Repeater对象,本章我们继续来学习布局管理器 1.RowLayout.Column ...
- grafana接入zabbix数据源
一.grafana介绍 grafana是开源免费的应用数据可视化仪表盘,由于zabbix本身对监控数据可视化并不侧重,所以大多使用第三方数据可视化工具来做大屏.下面向小伙伴们介绍grafana接入za ...