Spark 集群安装部署
安装准备
Spark 集群和 Hadoop 类似,也是采用主从架构,Spark 中的主服务器进程就叫 Master(standalone 模式),从服务器进程叫 Worker
Spark 集群规划如下:
- node-01:Master
- node-02:Worker
- node-03:Worker
安装步骤
1. 上传并解压 Spark 安装文件
将 spark-2.4.7-bin-hadoop2.7.tgz 安装包上传到 node-01 的 /root 目录下,并将其解压
# 解压到 /apps 目录中
[root@node-01 ~]# tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz -C apps/
# 删除安装压缩包
[root@node-01 ~]# rm -rf spark-2.4.7-bin-hadoop2.7.tgz
[root@node-03 ~]# cd /root/apps/
# 改名
[root@node-01 apps]# mv spark-2.4.7-bin-hadoop2.7/ spark-2.4.7
2. 配置环境变量
[root@node-01 ~]# vim /etc/profile
#行尾添加
export SPARK_HOME=/root/apps/spark-2.4.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@node-01 ~]# source /etc/profile
3. 配置运行环境
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv spark-env.sh.template spark-env.sh
[root@node-01 conf]# vi spark-env.sh
# 行尾添加
export JAVA_HOME=/root/apps/jdk1.8.0_141/
# 设置 Spark Master 所在的主机名(或IP地址)
export SPARK_MASTER_HOST=node-01
export SPARK_MASTER_PORT=7077
4. 修改 slaves 配置
该脚本文件用于设置 Master 下面的 Worker 的主机名(或IP地址)
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv slaves.template slaves
[root@node-01 conf]# vi slaves
node-02
node-03
5. 创建启动和关闭 Spark 集群脚本软连接
创建软连接的原因是 hadoop/sbin 目录和 spark/sbin 目录脚本可能命名相同,导致执行命令冲突
[root@node-01 ~]# cd /root/apps/spark-2.4.7/sbin/
[root@node-01 sbin]# ln -s start-all.sh start-all-spark.sh
[root@node-01 sbin]# ln -s stop-all.sh stop-all-spark.sh
5. 将 Spark 安装包复制到集群其他主机上
[root@node-01 ~]# cd /etc
[root@node-01 etc]# scp profile node-02:$PWD
[root@node-01 etc]# scp profile node-03:$PWD
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# source /etc/profile
[root@node-01 ~]# cd apps/
[root@node-01 apps]# scp -r spark-2.4.7/ node-02:$PWD
[root@node-01 apps]# scp -r spark-2.4.7/ node-03:$PWD
6. 启动 Spark 集群
Spark 的 sbin 目录(里面存放各种 Spark 操作命令)
[root@node-01 ~]# start-all-spark.sh
starting org.apache.spark.deploy.master.Master, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hdp-01.out
hdp-03: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-03.out
hdp-02: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-02.out
[root@hdp-01 sbin]# jps
1690 Master
1742 Jps
再去查看 node-02 和 node-03
[root@node-02 ~]# jps
1557 Jps
1512 Worker
[root@node-03 ~]# jps
1538 Worker
1583 Jps
说明 Spark 集群已经启动成功
- 单独启动 Master:# start-master.sh
- 单独启动 Worker:# start-slave.sh spark://node-01:7077
6. 启动 Spark 的浏览器 Web 页面
这里 Web 的服务器端口号是 8080(端口号 7077 是 RPC 远程调用的通信端口)
打开浏览器输入:http://node-01:8080/ 回车
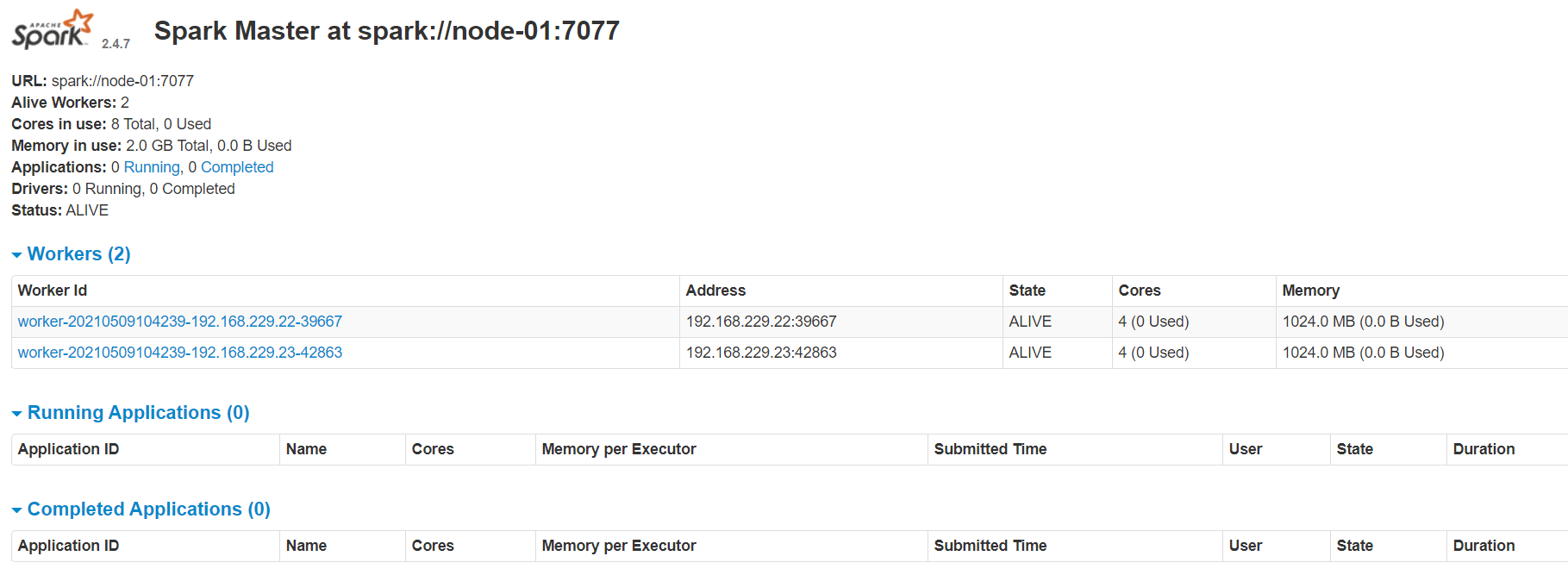
默认情况下 Spark 会占用机器上的所有 cores(CPU)和 memory(内存)
Spark 集群安装部署的更多相关文章
- Hadoop2.2集群安装配置-Spark集群安装部署
配置安装Hadoop2.2.0 部署spark 1.0的流程 一.环境描写叙述 本实验在一台Windows7-64下安装Vmware.在Vmware里安装两虚拟机分别例如以下 主机名spark1(19 ...
- spark集群安装部署
通过Ambari(HDP)或者Cloudera Management (CDH)等集群管理服务安装和部署在此不多介绍,只需要在界面直接操作和配置即可,本文主要通过原生安装,熟悉安装配置流程. 1.选取 ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
随机推荐
- 201871030127-王明强 实验二 个人项目—《D{0-1}背包问题 》项目报告
项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 我的课程学习目标 (1)详细阅读<构建之法>学习并掌握PSP的具体流程(2)掌握背包问题,通过查阅相关资料,设计一个采用 ...
- Ray Tracing in one Weekend 阅读笔记
目录 一.创建Ray类,实现背景 二.加入一个球 三.让球的颜色和其法线信息相关 四.多种形状,多个碰撞体 五.封装相机类 六.抗锯齿 七.漫发射 八.抽象出材料类(编写metal类) 九.介质材料( ...
- buuctf --pwn part2
pwn难啊! 1.[OGeek2019]babyrop 先check一下文件,开启了NX 在ida中没有找到system.'/bin/sh'等相关的字符,或许需要ROP绕过(废话,题目提示了) 查看到 ...
- 痞子衡嵌入式:在i.MXRT启动头FDCB里使能串行NOR Flash的DTR模式
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是在FDCB里使能串行NOR Flash的DTR模式. 前两篇文章 <IS25WP系列Dummy Cycle设置> 与 < ...
- 进击中的Vue 3——“电动车电池范围计算器”开源项目
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文参考:https://dzone.com/articles/build-a-tesla-battery- ...
- 【cypress】5. 测试本地web应用
在之前的cypress介绍里曾提到过,cypress虽然也可以测试部署好的应用,但是它最大的能力还是发挥在测试本地应用上. 本章主要内容就是关于如何测试本地web应用的概述: cypress与后台应用 ...
- adbi学习:so hook实现机制
本篇我们来看看adbi的实现原理,其实里面的知识点前面差不多都有涉及了,没多少新知识.adbi利用hijack程序将libexample.so注入到指定的进程中,并且在进程中加载libexample. ...
- layui在toolbar使用上传控件在reload后失效的问题解决
问题描述 使用layui中的upload组件来上传文件,将按钮放了表格中的toolbar(头部工具栏中),碰到的问题是:第一次可以实现上传文件,但是第二次再上传文件的时候,点击按钮无效. 解决办法 ...
- maven打war包
测试/本地 mvn clean package -Dmaven.test.skip=true 生产服务器打包命令 mvn clean package -P prod -Dmaven.test.skip ...
- layui图片上传
<!DOCTYPE html><html><head> <meta charset="utf-8"> <title>up ...