Spark 集群安装部署
安装准备
Spark 集群和 Hadoop 类似,也是采用主从架构,Spark 中的主服务器进程就叫 Master(standalone 模式),从服务器进程叫 Worker
Spark 集群规划如下:
- node-01:Master
- node-02:Worker
- node-03:Worker
安装步骤
1. 上传并解压 Spark 安装文件
将 spark-2.4.7-bin-hadoop2.7.tgz 安装包上传到 node-01 的 /root 目录下,并将其解压
# 解压到 /apps 目录中
[root@node-01 ~]# tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz -C apps/
# 删除安装压缩包
[root@node-01 ~]# rm -rf spark-2.4.7-bin-hadoop2.7.tgz
[root@node-03 ~]# cd /root/apps/
# 改名
[root@node-01 apps]# mv spark-2.4.7-bin-hadoop2.7/ spark-2.4.7
2. 配置环境变量
[root@node-01 ~]# vim /etc/profile
#行尾添加
export SPARK_HOME=/root/apps/spark-2.4.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@node-01 ~]# source /etc/profile
3. 配置运行环境
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv spark-env.sh.template spark-env.sh
[root@node-01 conf]# vi spark-env.sh
# 行尾添加
export JAVA_HOME=/root/apps/jdk1.8.0_141/
# 设置 Spark Master 所在的主机名(或IP地址)
export SPARK_MASTER_HOST=node-01
export SPARK_MASTER_PORT=7077
4. 修改 slaves 配置
该脚本文件用于设置 Master 下面的 Worker 的主机名(或IP地址)
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv slaves.template slaves
[root@node-01 conf]# vi slaves
node-02
node-03
5. 创建启动和关闭 Spark 集群脚本软连接
创建软连接的原因是 hadoop/sbin 目录和 spark/sbin 目录脚本可能命名相同,导致执行命令冲突
[root@node-01 ~]# cd /root/apps/spark-2.4.7/sbin/
[root@node-01 sbin]# ln -s start-all.sh start-all-spark.sh
[root@node-01 sbin]# ln -s stop-all.sh stop-all-spark.sh
5. 将 Spark 安装包复制到集群其他主机上
[root@node-01 ~]# cd /etc
[root@node-01 etc]# scp profile node-02:$PWD
[root@node-01 etc]# scp profile node-03:$PWD
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# source /etc/profile
[root@node-01 ~]# cd apps/
[root@node-01 apps]# scp -r spark-2.4.7/ node-02:$PWD
[root@node-01 apps]# scp -r spark-2.4.7/ node-03:$PWD
6. 启动 Spark 集群
Spark 的 sbin 目录(里面存放各种 Spark 操作命令)
[root@node-01 ~]# start-all-spark.sh
starting org.apache.spark.deploy.master.Master, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hdp-01.out
hdp-03: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-03.out
hdp-02: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-02.out
[root@hdp-01 sbin]# jps
1690 Master
1742 Jps
再去查看 node-02 和 node-03
[root@node-02 ~]# jps
1557 Jps
1512 Worker
[root@node-03 ~]# jps
1538 Worker
1583 Jps
说明 Spark 集群已经启动成功
- 单独启动 Master:# start-master.sh
- 单独启动 Worker:# start-slave.sh spark://node-01:7077
6. 启动 Spark 的浏览器 Web 页面
这里 Web 的服务器端口号是 8080(端口号 7077 是 RPC 远程调用的通信端口)
打开浏览器输入:http://node-01:8080/ 回车
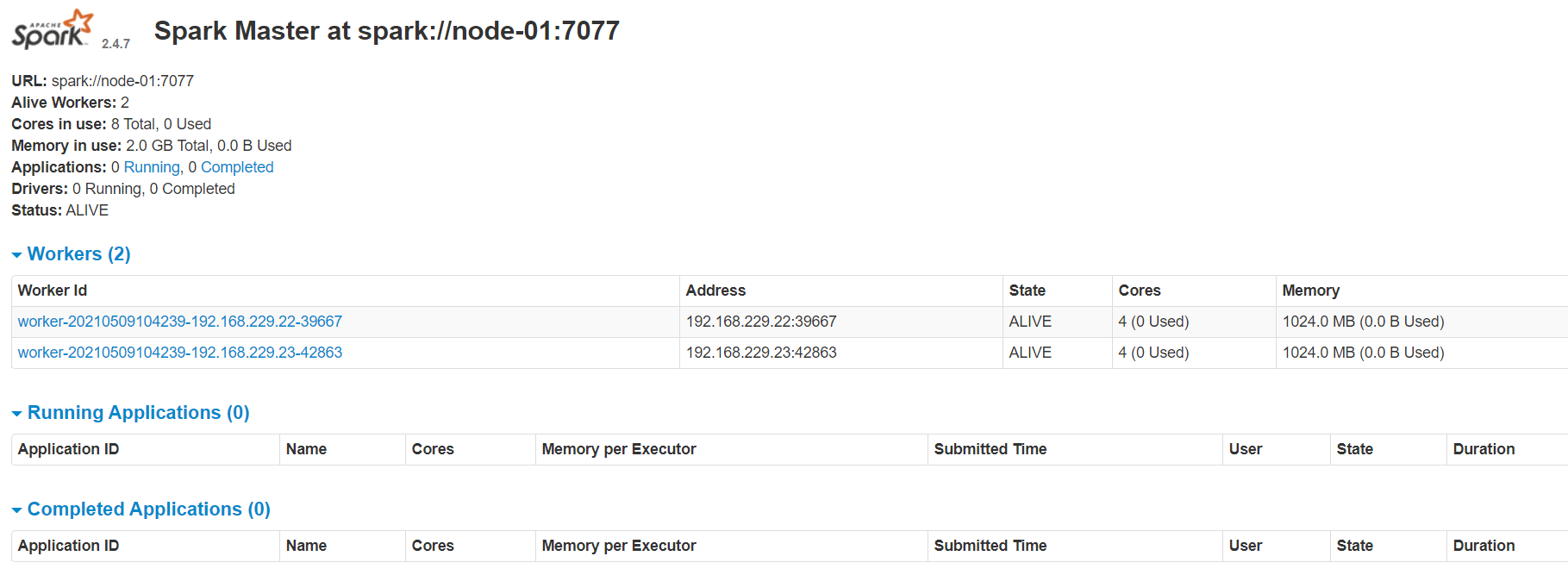
默认情况下 Spark 会占用机器上的所有 cores(CPU)和 memory(内存)
Spark 集群安装部署的更多相关文章
- Hadoop2.2集群安装配置-Spark集群安装部署
配置安装Hadoop2.2.0 部署spark 1.0的流程 一.环境描写叙述 本实验在一台Windows7-64下安装Vmware.在Vmware里安装两虚拟机分别例如以下 主机名spark1(19 ...
- spark集群安装部署
通过Ambari(HDP)或者Cloudera Management (CDH)等集群管理服务安装和部署在此不多介绍,只需要在界面直接操作和配置即可,本文主要通过原生安装,熟悉安装配置流程. 1.选取 ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
随机推荐
- 自学PHP笔记(三) 类型转换
本文转发来自:https://blog.csdn.net/KH_FC/article/details/115558701 在真正使用PHP写项目时会经常用到不同数据类型之间进行转换,PHP中类型转换是 ...
- 【Java】流、IO(初步)
(这部分比较抽象且写的不是很好,可能还要再编辑) [概述] 流:流是一系列数据,包括输入流和输出流.你可以想象成黑客帝国的"代码雨",只要我们输入指令,这些数据就像水一样流进流出了 ...
- hbuilderX打包苹果证书的申请方法
现在uniapp越来越火,hbuilderX和apicloud这些工具使用html+js语言就可以开发强大的app,大大降低了app开发的技术门槛. hbuilderX或apicloud在打包ios应 ...
- NTP时间同步服务
NTP时间服务器 作用:ntp主要是用于对计算机的时间同步管理操作. 时间是对服务器来说是很重要的,一般很多网站都需要读取服务器时间来记录相关信息,如果时间不准,则可能造成很大的影响. 部署安装NTP ...
- SQL Server 审计(Audit)
审计(Audit)用于追踪和记录SQL Server实例,或者单个数据库中发生的事件(Event),审计运作的机制是通过捕获事件(Event),把事件包含的信息写入到事件日志(Event Log)或审 ...
- 粗浅聊聊Python装饰器
浅析装饰器 通常情况下,给一个对象添加新功能有三种方式: 直接给对象所属的类添加方法: 使用组合:(在新类中创建原有类的对象,重复利用已有类的功能) 使用继承:(可以使用现有类的,无需重复编写原有类进 ...
- 腾讯云TCA开发工程师认证考试
1.关于云硬盘CBS的描述,错误的是哪一项?(B) A.云硬盘提供数据块级别的数据存储,采用三副本的分布式机制,为 CVM 提供数据可靠性保证 B.云硬盘可在同一可用区中自由挂载.卸载;挂载和卸载过程 ...
- 通过钉钉网页上的js学习xss打cookie
做完了一个项目,然后没啥事做,无意看到了一个钉钉的外部链接: 题外话1: 查看源码,复制其中的代码: try { var search = location.search; if (search &a ...
- 一文抽丝剥茧带你掌握复杂Gremlin查询的调试方法
摘要:Gremlin是图数据库查询使用最普遍的基础查询语言.Gremlin的图灵完备性,使其能够编写非常复杂的查询语句.对于复杂的问题,我们该如何编写一个复杂的查询?以及我们该如何理解已有的复杂查询? ...
- hdu4994 博弈,按顺序拿球
题意: 给你n堆东西,两个人博弈的去拿,每次最少一个,最多是一堆,必须按顺序那,也就是只有把第一堆的东西拿完了才能去拿第二堆东西,谁先拿完谁胜,问新手是否能胜利. 思路: 显然 ...