Mysql索引数据结构为什么是B+树?
Mysql索引数据结构
下面列举了常见的数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree(B树)
Select * from t where t.col=5
我们在执行一条查询的Sql语句时候,在数据量比较大又不加索引的情况下,逐行查询并进行比对,每次需要从磁盘上查找,每行数据可能在磁盘不同的位置,数据比较靠后的话,一千万数据可能要比对几百万,很耗费资源。
Mysql衡量查询效率的就是磁盘IO次数,那么Mysql中应该采用什么样的数据结构存储数据呢,以及为什么要使用那个数据结构呢。
二叉树
大多数人都知道,如果加上索引之后。把数据放在二叉树里面,查询会快很多,但是还有一种特殊的情况:
把一个递增列的索引放入二叉树中,列id作为等于5查询目标,就会从col为1开始搜索,这样要搜索几次?二叉树插入的数据如果大于本身,会放在父节点的右下角,小的会放在父节点的左下角,因此形成了这样像链表一样的结构,其实本质还是二叉树。
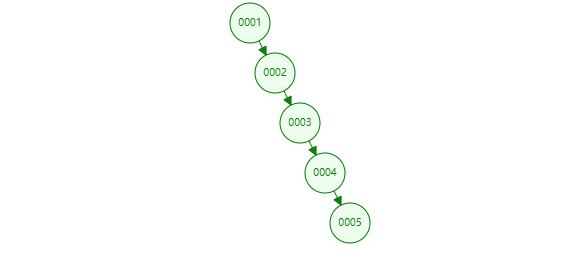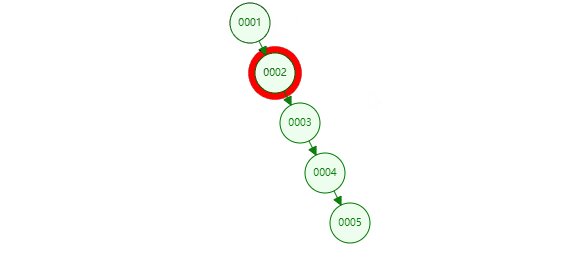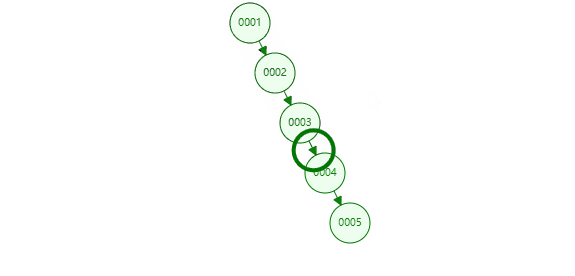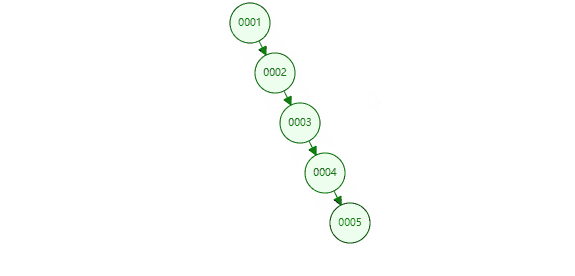
需要从根节点遍历,经过5次的查找,每个节点都存储在磁盘上,每查一个节点需要跟磁盘做一次IO交互,效率相比之前没加索引也没有太大提升,这显然不是Mysql的索引结构。
红黑树
HasMap的数据结构就是红黑树,原来是数组加链表,现在优化到了数组加红黑树。

红黑树本质还是二叉树,还有一个名字又叫平衡二叉树。当一边子节点比另一边高太多的时候,会自动旋转平衡。当数据量比较大的时候比如1000万,红黑树存储的高度就可能达到几十。如果数据量越大树的高度就会越高。每查一个节点要进行一次磁盘IO交互。树的高的越高查找效率越低,很显然红黑树也不是Mysql的数据结构,早期版本Mysql有用到红黑树,现在版本没有用到红黑树。那么能不能对红黑树做点改造。
B-Tree
树的高的越高查找效率越低,那么将树高缩小,比如限制在5层,把一层存放更多元素。把一个节点的数据在磁盘同一个区域全部查出来放到内存,只做一次IO查找,就可以查到很多索引信息。B树又叫平衡多叉树。
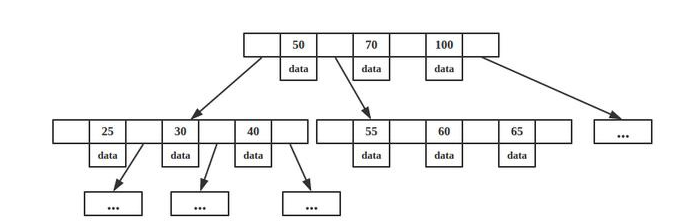
索引值和具体data都在每个节点里,而节点的位置不固定,最好的情况查找值就在第一层。
B树的特点就是每层节点数目非常多,层数很少,目的就是为了就少磁盘IO次数,B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题,由于节点内部每个 key 都带着 data 域,每次查找到具体节点还要和data进行顺序比对,如果查找某个范围内数据,又需要重新遍历。正是为了解决这个问题,B+树应运而生
B树遍历全部数据:
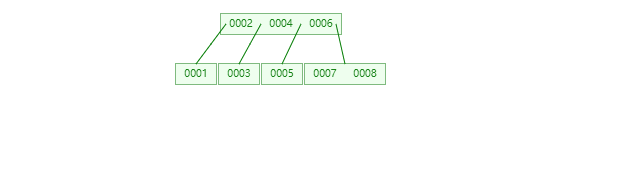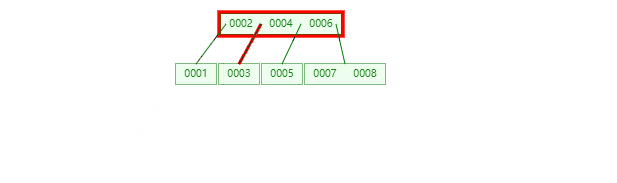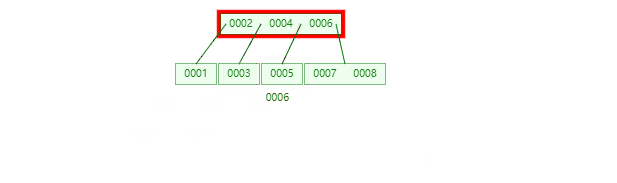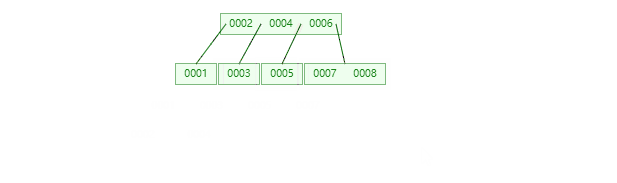
B+Tree
B+树节点只存储 key 的副本,真实的 key 和 data 域都在叶子节点存储,数据全部存储在叶子节,并且每一个节点之间用指针串联起来,形成链表,方便遍历,可以跨区间访问,这优点尤其突出在范围查询,不需要在一次从根节点到子节点遍历。

B+树遍历全部数据:
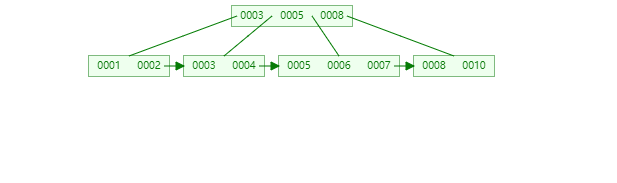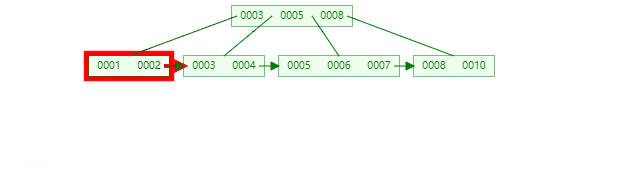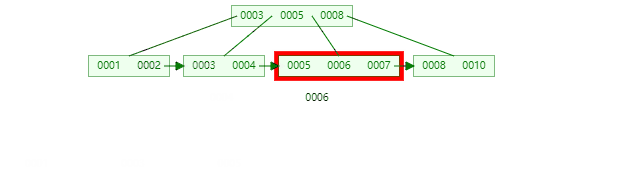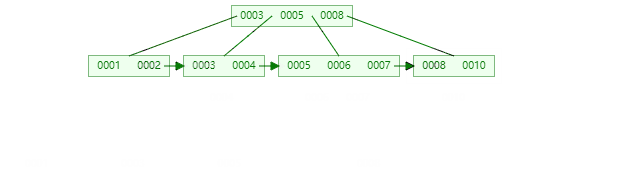
数据量大的情况下哪个更快,我想你应该知道了吧!
Mysql索引数据结构为什么是B+树?的更多相关文章
- MySQL索引(二)B+树在磁盘中的存储
MySQL索引(二)B+树在磁盘中的存储 回顾  上一篇文章<MySQL索引为什么要用B+树>讲了MySQL为什么选择用B+树来作为底层存储结构,提了两个知识点: B+树索引并不能直接找 ...
- MySQL索引的原理,B+树、聚集索引和二级索引
MySQL索引的原理,B+树.聚集索引和二级索引的结构分析 一.索引类型 1.1 B树 1.2 B+树 1.3 哈希索引 1.4 聚集索引(clusterd index) 1.5 二级索引(secon ...
- mysql系列十、mysql索引结构的实现B+树/B-树原理
一.MySQL索引原理 1.索引背景 生活中随处可见索引的例子,如火车站的车次表.图书的目录等.它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的 ...
- mysql 索引数据结构及原理
原文:http://www.uml.org.cn/sjjm/201107145.asp 1 索引的本质 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构.提取句子 ...
- MySQL索引----数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- mysql索引数据结构
什么是索引?索引就是排好序的数据结构,可以帮助我们快速的查找到数据 推荐一个网站,可以演示各种数据结构:https://www.cs.usfca.edu/~galles/visualization/A ...
- Mysql索引数据结构详解(1)
慢查询解决:使用索引 索引是帮助Mysql高效获取数据的排好序的数据结构 常见的存储数据结构: 二叉树 二叉树不适合单边增长的数据 红黑树(又称二叉平衡树) 红黑树会自动平衡父节点两边的 ...
- MySQL索引的原理,B+树、聚集索引和二级索引的结构分析
索引是一种用于快速查询行的数据结构,就像一本书的目录就是一个索引,如果想在一本书中找到某个主题,一般会先找到对应页码.在mysql中,存储引擎用类似的方法使用索引,先在索引中找到对应值,然后根据匹配的 ...
- B+/-Tree原理(mysql索引数据结构)
B+/-Tree原理 B-Tree介绍 B-Tree是一种多路搜索树(并不是二叉的): 1.定义任意非叶子结点最多只有M个儿子:且M>2: 2.根结点的儿子数为[2, M ...
随机推荐
- Day09_41_集合_Set
Set集合 Set集合 - Set集合的特点是无序不可重复.Set集合类似于一个罐子,程序可以依次把多个对象"丢进"Set集合,而Set集合通常不能记住元素的添加顺序. - Set ...
- JavaScript设计模式(一):单例模式
单例模式的定义与特点 单例(Singleton)模式的定义:指一个类只有一个实例,且该类能自行创建这个实例的一种模式.例如,Windows 中只能打开一个任务管理器,这样可以避免因打开多个任务管理器窗 ...
- 这种ERP系统核查工作实际是在做无用功
前段时间跟朋友聊起他们公司持续了好几年的ERP核查工作,此时他正在一家分公司做核查.ERP核查工作我是知道的,一个季度一次,每个模块出一个人去子公司巡回巡查,主要核查ERP系统的使用情况. 核查工作主 ...
- C#如何优雅的多表读取
关键词:C#.SqlDataReader.IDataReader.NextResult().Read(). Load().Dapper.多表,方便索引和搜索 最近有个需求,需要读一下模具系统的模具信息 ...
- 模拟退火算法Python编程(2)约束条件的处理
1.最优化与线性规划 最优化问题的三要素是决策变量.目标函数和约束条件. 线性规划(Linear programming),是研究线性约束条件下线性目标函数的极值问题的优化方法,常用于解决利用现有的资 ...
- PHP laravel系列之Blade模版
一.什么是Blade模版? Blade 是 Laravel 提供的一个既简单又强大的模板引擎. 和其他流行的 PHP 模板引擎不一样,Blade 并不限制你在视图中使用原生 PHP 代码.所有 Bla ...
- ThinkPHP5 利用.htaccess文件的 Rewrite 规则隐藏URL中的 index.php
1.首先修改Apache的httpd.conf文件. 确认httpd.conf配置文件中加载了mod_rewrite.so 模块,加载的方法是去掉mod_rewrite.so前面的注释#号 讲http ...
- hdu4020简单想法题
题意: 给你一些人,这些人有很多广告,每个广告有自己的点击率和长度,每次有m组询问,问每个人点击率前K名的广告的总长度是多少. 思路: 数据很大,很容易超时,总的想法还是先so ...
- hdu2489-DFS+最小生成树
题意: 给你n个点,和任意两点的距离,让你在这N个点中找到一个有m个点并且ratio最小的树. ratio = sum(edge) / su ...
- 2sat建边总结
2sat的基础建边 AND = 1 : ~x -> x ,~y -> y (两个数必须全为1) AND = 0 : y -> ~x ,x -> ~y (两个数至少有一个为 ...