EDG夺冠!用Python分析22.3万条数据:粉丝都疯了!
一、EDG夺冠信息
11月6日,在英雄联盟总决赛中,EDG战队以3:2战胜韩国队,获得2021年英雄联盟全球总决赛冠军,这个比赛在全网各大平台也是备受瞩目:
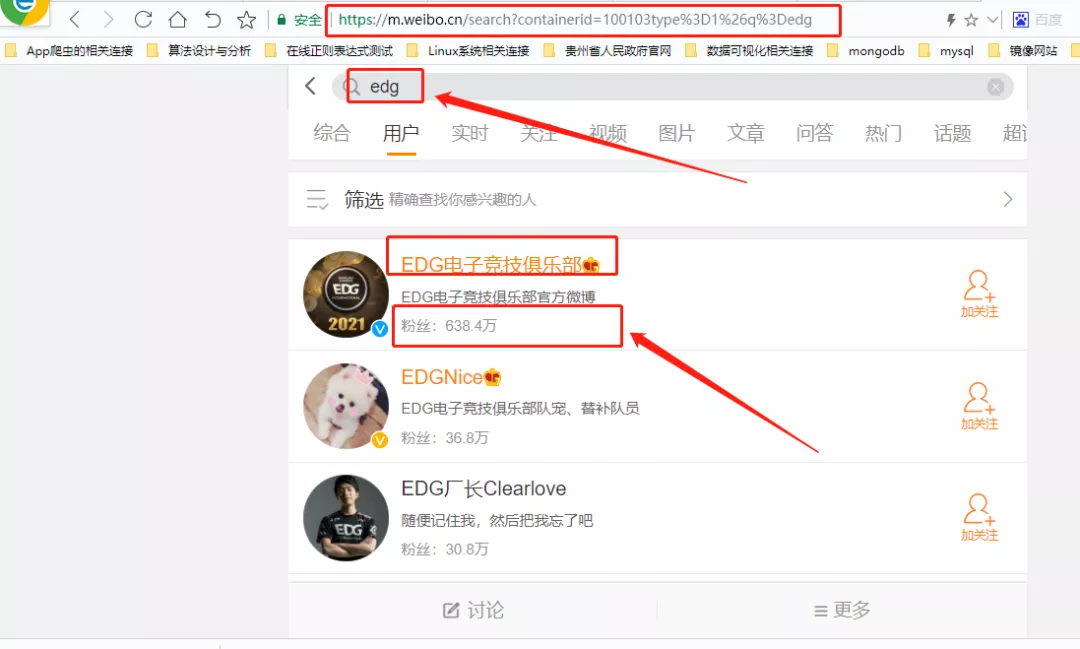
1、微博热搜第一名,截止2021-11-10已有亿级观看量,微博粉丝数到达638.4万
2、哔哩哔哩已有几亿人气,总弹幕有22.3万,全站排行榜最高第2名,B站粉丝已有219.9万
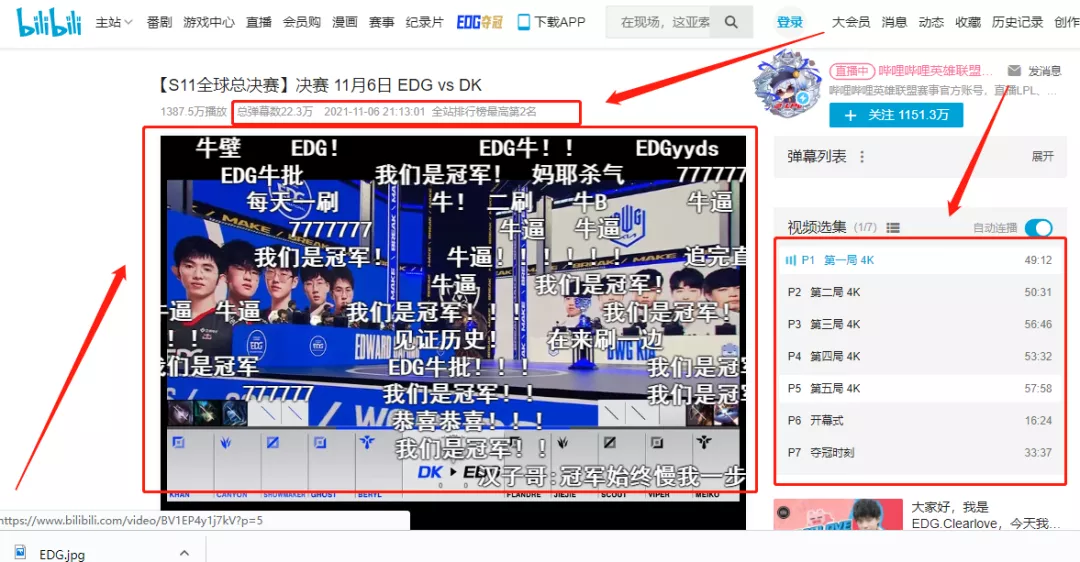

3、腾讯、爱奇艺、优酷等视频平台800万人看过
4、虎牙等直播平台热度也是居高不下
5、央视新闻也发微博庆祝EDG夺冠


既然比赛热度这么高,那么本次我们就以bilibili为基准,通过采集EDG夺冠比赛视频在哔哩哔哩的22.3万条弹幕数据,再通过Python来分析进而感受粉丝的热情
二、实战目标
1、利用爬虫技术抓取EDG战队在B站夺冠比赛视频的22.3万条弹幕数据
2、通过jieba、numpy等Python库对抓取来的弹幕数据进行分析并且可视化


三、bilibili接口分析
首先进入EDG夺冠比赛视频URL:
https://www.bilibili.com/video/BV1EP4y1j7kV?p=1
哔哩哔哩已为大家整理好了EDG比赛视频,从开幕式到夺冠时刻,共有7个视频

哔哩哔哩弹幕数据接口:
http://api.bilibili.com/x/v1/dm/list.so?oid=XXX
这个接口就是B站弹幕数据专用接口,我们可以直接拿来用,这个接口中的oid可以理解为每个视频中的唯一标识符,它由数字组成,每一个视频都有唯一的一个oid,那么我们只要找到oid就可以请求相应比赛视频弹幕的API接口,从而抓取弹幕数据
获取oid
打开开发者工具,切换到Network选项,然后找到以pagelist为开头的请求接口

接着找到Request URL这个请求接口,打开新窗口直接用这个API接口请求,如下图:

当我们直接请求这个API接口时可以看到JSON格式的数据,而在里面的cid就是我们需要的oid,如下所示:
1 {"code":0,"message":"0","ttl":1,"data":[{"cid":437586584,"page":1,"from":"vupload","part":"第一局 4K","duration":2952,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437626309,"page":2,"from":"vupload","part":"第二局 4K","duration":3031,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437659159,"page":3,"from":"vupload","part":"第三局 4K","duration":3406,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437727348,"page":4,"from":"vupload","part":"第四局 4K","duration":3212,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437729555,"page":5,"from":"vupload","part":"第五局 4K","duration":3478,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437550300,"page":6,"from":"vupload","part":"开幕式","duration":984,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437717574,"page":7,"from":"vupload","part":"夺冠时刻","duration":2017,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}}]
当然我们也可以点击Preview选项,点击data,打开数据,而里面的JSON数据是折叠的,包括cid在内,如下图所示:
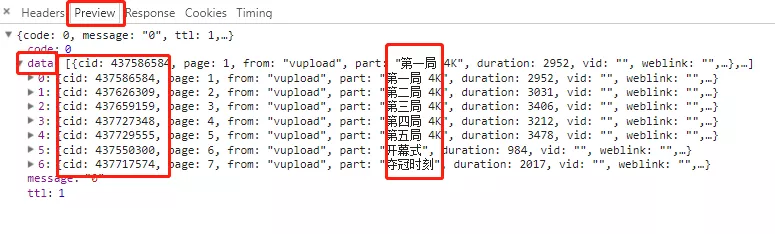
可以看到,每个cid对应每一个比赛视频。我们也可以点击Response选项,里面的数据是真实的数据,意味着数据没有经过折叠,与直接请求Request URL返回的JSON数据是一样的
四、编码
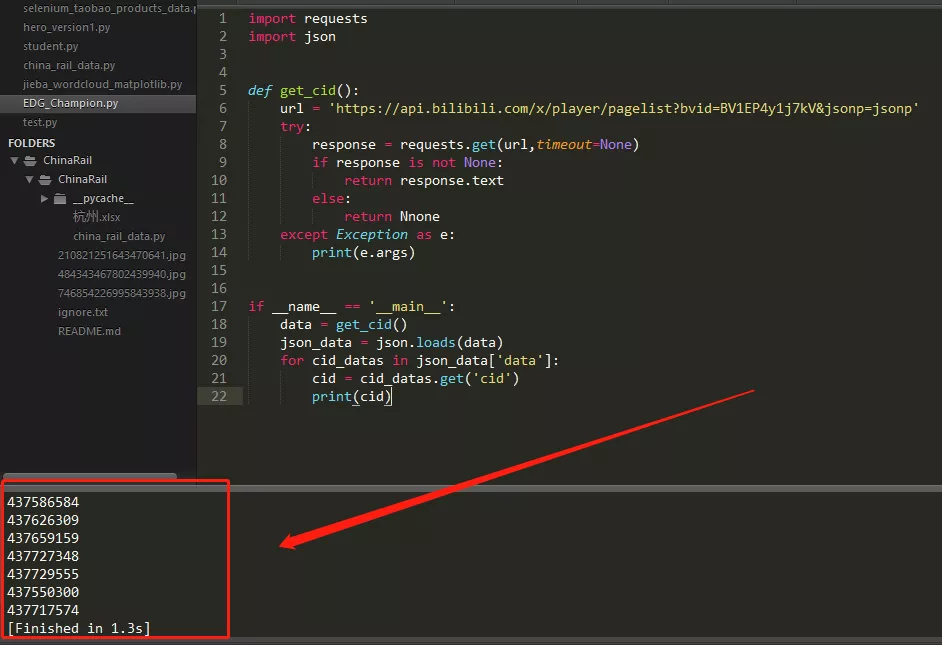
定义一个获取cid的方法
1 import requests
2 import json
3
4
5 def get_cid():
6 url = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp'
7 try:
8 response = requests.get(url,timeout=None)
9 if response is not None:
10 return response.text
11 else:
12 return Nnone
13 except Exception as e:
14 print(e.args)
15
16
17 if __name__ == '__main__':
18 data = get_cid()
19 json_data = json.loads(data)
20 for cid_datas in json_data['data']:
21 cid = cid_datas.get('cid')
22 print(cid)
控制台输出如下:
拼接URL弹幕数据API接口
1 if __name__ == '__main__':
2 data = get_cid()
3 json_data = json.loads(data)
4 base_api = 'http://api.bilibili.com/x/v1/dm/list.so?oid='
5 for cid_datas in json_data['data']:
6 cid = cid_datas.get('cid')
7 detail_api = base_api + str(cid)
8 print(detail_api)
控制台输出如下:
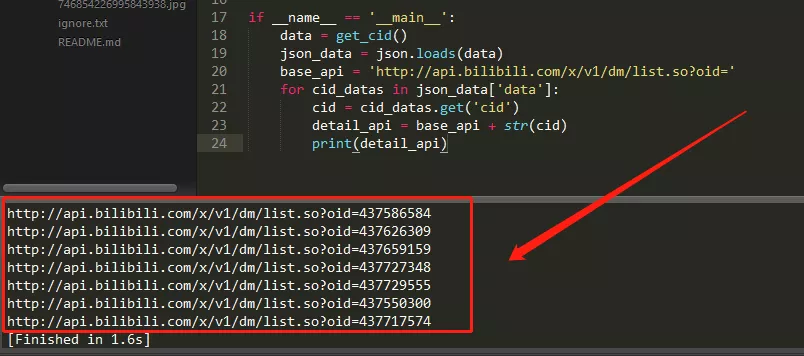
一共有7个网址,对应7个EDG比赛视频的弹幕数据,我们点开第一个网址查看

抓取弹幕数据
从上一张图可以看到,每一条弹幕数据都在每一个<d>标签中,面对这种格式我们思考一下用哪种解析工具比较合适?答案当然是正则表达式,接下来我们要获取7个比赛视频的22.3万条数据,代码如下:
1 base_api = 'http://api.bilibili.com/x/v1/dm/list.so?oid='
2 all_api = []
3 for cid_datas in json_data['data']:
4 cid = cid_datas.get('cid')
5 detail_api = base_api + str(cid)
6 all_api.append(detail_api)
7 for api in all_api:
8 edg_datas = get_api_data(detail_api)
9 edg_datas = re.findall('<d.*?>(.*?)</d>',edg_datas,re.S)
10 with open('EDG.txt','a',encoding='utf-8') as f:
11 for edg_data in edg_datas:
12 print(edg_data)
13 f.write(edg_data + '\n')
避免乱码,加上如下代码:
1 response.encoding = chardet.detect(response.content)['encoding']
控制台输出如下:
由于弹幕数据共有22.3万条,这里仅展示EDG.txt部分弹幕数据,如下图所示:
词云图制作
我们已经抓取到弹幕数据,接下来利用EDG背景图做一个词云图

代码如下:
1 import jieba
2 from wordcloud import WordCloud
3 import matplotlib.pyplot as plt
4 from PIL import Image
5 import numpy as np
6
7 def do_wordcloud():
8 text = open('EDG.txt','r',encoding='utf-8').read()
9 text = text.replace('\n','').replace('\u3000','')
10 text_cut = jieba.lcut(text)
11 text_cut = ' '.join(text_cut)
12
13 #过滤一些没有关系的词
14 stop_words = ['“',',',' ','我','的','是','了',':','?','!','啊','你','吗','。','我们']
15
16 background = Image.open("EDG.jpg")
17 graph = np.array(background)
18
19 word_cloud = WordCloud(font_path='simsun.ttc',
20 background_color='white',
21 mask=graph, # 指定词云的形状
22 stopwords=stop_words)
23
24 word_cloud.generate(text_cut)
25 plt.subplots(figsize=(12,8))
26 plt.imshow(word_cloud)
27 plt.axis('off')
28 plt.show()
29 word_cloud.to_file('edg.png')
控制台输出如下:
把迪迦奥特曼背景图片也制作一波吧,哈哈哈!

制作成迪迦奥特曼词云图形状,如下所示:
当然你也可以使用pyecharts/echarts制作也行,还可以制作成你喜欢的图片形状。如果你接触过情感分析的话,也可以用这些弹幕数据分析一波
五、总结
PIL库
jieba库
numpy库
requests库
wordcloud库
matplotlib库
json,re,chardet库
六、完整项目及源码下载
完整项目(包括源码)获取方式:下载
原创不易,如果觉得有趣好玩,希望可以随手点个赞,拜谢各位老铁!
更多独家精彩内容 请扫码关注个人公众号,我们一起成长,一起Coding,让编程更有趣!
—— —— —— —— — END —— —— —— —— ————
欢迎扫码关注我的公众号
小鸿星空科技

EDG夺冠!用Python分析22.3万条数据:粉丝都疯了!的更多相关文章
- [Python] 通过采集两万条数据,对《无名之辈》影评分析
一.说明 本文主要讲述采集猫眼电影用户评论进行分析,相关爬虫采集程序可以爬取多个电影评论. 运行环境:Win10/Python3.5. 分析工具:jieba.wordcloud.pyecharts.m ...
- [Python] 通过采集23万条数据,对《哪吒》影评分析
一.说明 数据来源:猫眼: 运行环境:Win10/Python3.7 和 Win7/Python3.5: 分析工具:jieba.WorldCloud.pyecharts和matplotlib: 程序基 ...
- (转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日. 翻着安静到死寂的聊天列表,我忽然惊醒,不行 ...
- Mvc+Dapper+存储过程分页10万条数据
10万条数据采用存储过程分页实现(Mvc+Dapper+存储过程) 有时候大数据量进行查询操作的时候,查询速度很大强度上可以影响用户体验,因此自己简单写了一个demo,简单总结记录一下: 技术:Mvc ...
- 复杂业务下向Mysql导入30万条数据代码优化的踩坑记录
从毕业到现在第一次接触到超过30万条数据导入MySQL的场景(有点low),就是在顺丰公司接入我司EMM产品时需要将AD中的员工数据导入MySQL中,因此楼主负责的模块connector就派上了用场. ...
- 插入1000万条数据到mysql数据库表
转自:https://www.cnblogs.com/fanwencong/p/5765136.html 我用到的数据库为,mysql数据库5.7版本的 1.首先自己准备好数据库表 其实我在插入100 ...
- 绝对干货,教你4分钟插入1000万条数据到mysql数据库表,快快进来
我用到的数据库为,mysql数据库5.7版本的 1.首先自己准备好数据库表 其实我在插入1000万条数据的时候遇到了一些问题,现在先来解决他们,一开始我插入100万条数据时候报错,控制台的信息如下: ...
- 1000万条数据导入mysql
今天需要将一个含有1000万条数据的文本内容插入到数据库表中,最初自然想到的是使用Insertinto '表名'values(),(),()...这种插入方式,但是发现这种方式对1000万条数据量的情 ...
- QTreeView处理大量数据(使用1000万条数据,每次都只是部分刷新)
如何使QTreeView快速显示1000万条数据,并且内存占用量少呢?这个问题困扰我很久,在网上找了好多相关资料,都没有找到合理的解决方案,今天在这里把我的解决方案提供给朋友们,供大家相互学习. 我开 ...
随机推荐
- 关于URL encode和parse
from urllib import parses = 'https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&tn=baidu& ...
- PolarDB PostgreSQL logindex 设计
背景介绍 PolarDB采用了共享存储一写多读架构,读写节点RW和多个只读节点RO共享同一份存储,读写节点可以读写共享存储中的数据:只读节点仅能各自通过回放日志,从共享存储中读取数据,而不能写入,只读 ...
- Hive语法及其进阶(一)
1.Hive完整建表 1 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name( 2 [(col_name data_type [COMMENT col ...
- 好久没发文了,一篇Vue3的Composition API使用奉上
Composition API Composition API是Vue3中推荐的组件代码书写方式,相较于传统的Options API来说,它能让业务逻辑处理和后期代码维护变的更加简单. 首先我们来看O ...
- 通俗易懂,Layui前端框架!
前言 layui 是一款采用自身模块规范编写的前端 UI 框架,遵循原生 HTML/CSS/JS 的书写与组织形式,门槛极低,拿来即用.其外在极简,却又不失饱满的内在,体积轻盈,组件丰盈,从核心代 ...
- HBase基础
Hadoop生态系统 HBase简介 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩.实时读写的分布式数据库 利用Hadoop HDFS作为其文件存储系统,利用 ...
- MySQL8.0允许外部访问
MySQL8.0允许外部访问 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/h99 ...
- 如何迁移 Spring Boot 到函数计算
作者 | 田小单 首先介绍下在本文出现的几个比较重要的概念: 函数计算(Function Compute): 函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上 ...
- 【Java虚拟机11】线程上下文类加载器
前言 目前学习到的类加载的知识,都是基于[双亲委托机制]的.那么JDK难道就没有提供一种打破双亲委托机制的类加载机制吗? 答案是否定的. JDK为我们提供了一种打破双亲委托模型的机制:线程上下文类加载 ...
- 【UE4】基础概念——文件结构、类型、反射、编译、接口、垃圾回收、序列化
新标签打开或者下载看大图 思维导图 Engine Structure Pipeline Programming Pipeline Blueprint Pipeline