CUDA计算矩阵相乘
1.最简单的 kernel 函数
__global__ void MatrixMulKernel( float* Md, float* Nd, float* Pd, int Width)
{
int tx = threadIdx.x; // cloumn
int ty = threadIdx.y; // row
float Pvalue = 0;
for (int k = 0; k<Width; k++)
{
float Mdele = Md[ty*Width + k];
float Ndele = Nd[k*Width + tx];
Pvalue += Mdele * Ndele;
}
Pd[ty*Width + tx] = Pvalue;
}
2.适用更大矩阵
第一节中例子缺点是,假如使用更多的块时,每个块中会计算相同的矩阵。而且矩阵元素不能超过512个线程(块最大线程限制)。
改进方法是,假设每个块维度都是方阵形式,且其维度由变量 TILE_WIDTH 指定。矩阵 Pd 的每一维都划分为部分,每个部分包含 TILE_WIDTH 个元素。
#define TILE_WIDTH 4
#define Width 8
__global__ void MatrixMulKernel( float* Md, float* Nd, float* Pd, int Width)
{
int Col = blockId.x*TILE_WIDTH + threadIdx.x; // cloumn
int Row = blockId.y*TILE_WIDTH + threadIdx.y; // row
float Pvalue = 0;
for (int k = 0; k<Width; k++)
{
Pvalue += Md[Row*Width + k] * Nd[k*Width + Col];
}
Pd[ty*Width + tx] = Pvalue;
}
dim3 dimGrid(Width/TILE_WIDTH, Width/TILE_WIDTH);
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH);
CUDA 硬件相关概念
针对 GT200而言
- 每个
SM有最多8个块 - 每个
SM有最多1024个线程
应当注意每个块中分配的线程数,以便能够充分利用SM
- 以32个线程为一个
warp,warp为线程调度单位
3.通过改变储存器提到访问效率
CGMA(Compute to Global Memory Access),尽量提高CGMA比值。
对前面来说,每个for循环内需要两次访问全局内存(Md[Row*Width + k], Nd[k*Width + Col]),两次浮点计算(加法与乘法)。因此 CGMA 为2:2 = 1。
G80 全局存储器带宽为 86.4 GB/s,计算峰值性能 367 Gflops。(每秒取 21.6G 个变量,由于CGMA=1,会进行 21.6G 次浮点计算)
若每个单精度浮点数为 4 字节,那么由于存储器限制,最大浮点操作不会超过 21.6 Gflops。
| 存储器类型 | 变量 | 周期 | 特点 | 访问速度 |
| --- | --- | --- | --- |
| 共享存储器 | 共享变量 | kernel函数 | 每个块中所有线程都可以访问,用于线程间协作高效方式 | 相当快,高度并行访问 |
| 常数存储器 | 常数变量 | 所有网格 | 相当快,并行访问 |
| 寄存器 | 自动变量 | 线程 | 寄存器具有储存容量限制 | 非常块
| 全局存储器 | 全局变量 | | 用于调用不同kernel函数时传递信息 | 慢 |
减少全局存储器流量策略
各个存储器特点:
- 全局存储器,容量大,访问慢
- 共享存储器,容量小,访问块
新算法要点:
- 将共享存储器上数据划分子集,每个子集满足共享存储器容量限制
- 通过线程协作将
M和N中的元素加载到共享存储器中,每个线程负责块中一个元素赋值(Mds[threadIdx.y][threadIdx.x],Nds[threadIdx.y][threadIdx.x]) - 通过加载到共享存储器,使得每个块访问全局内存的次数减小为原来的
TILE_WIDTH分之一(加载到共享内存时读取一次,每个块中使用TILE_WIDTH次)
__global__ void kernel_tile(float* M, float* N, float* P){
int i, k;
float Pvalue = 0;
__shared__ float Mds[tile_width][tile_width];
__shared__ float Nds[tile_width][tile_width];
int Row = threadIdx.y + blockIdx.y*tile_width;
int Col = threadIdx.x + blockIdx.x*tile_width;
for( i = 0; i< width/tile_width; i++ ){
Mds[threadIdx.y][threadIdx.x] = M[Row*width + i*tile_width + threadIdx.x];
Nds[threadIdx.y][threadIdx.x] = N[(threadIdx.y + i*tile_width)*width + Col];
__syncthreads();
for (k = 0; k<tile_width; k++){
Pvalue += Mds[threadIdx.y][k]*Nds[k][threadIdx.x];
}
__syncthreads();
}
P[Row*width + Col] = Pvalue;
}
存储器容量限制
G80 硬件中
- 每个
SM寄存器大小为 8 KB(8192 B) - 每个
SM共享内存大小为 16 KB - 若每个
SM中容纳线程数为 768,那么每个线程可用寄存器不超过 8 KB/768=10 Bytes(两个单精度变量占用 8 Bytes) - 若每个线程占用了多余 10 Bytes,那么就会减少
SM上线程数,且以块为单位减少 - 若每个
SM中容纳 8 个块,那么每个块不能使用超过 2 KB 的存储器
4.数据预取
在 CUDA 中,当某些线程在等待其存储器访问结果时,CUDA 线程模型可以通过允许其他 warp 继续运行,这样就能容许长时间的访问延时。
为了充分利用此特性,需要当使用当前数据元素时预取下一个数据元素,这样就可以正价在储存器访问和已访问的数据使用指令之间的独立指令的数目。
预取技术经常和分块技术结合,解决带宽限制和长时间延迟问题。
例如在第三节中矩阵乘法问题中,使用预取技术后函数流程变为
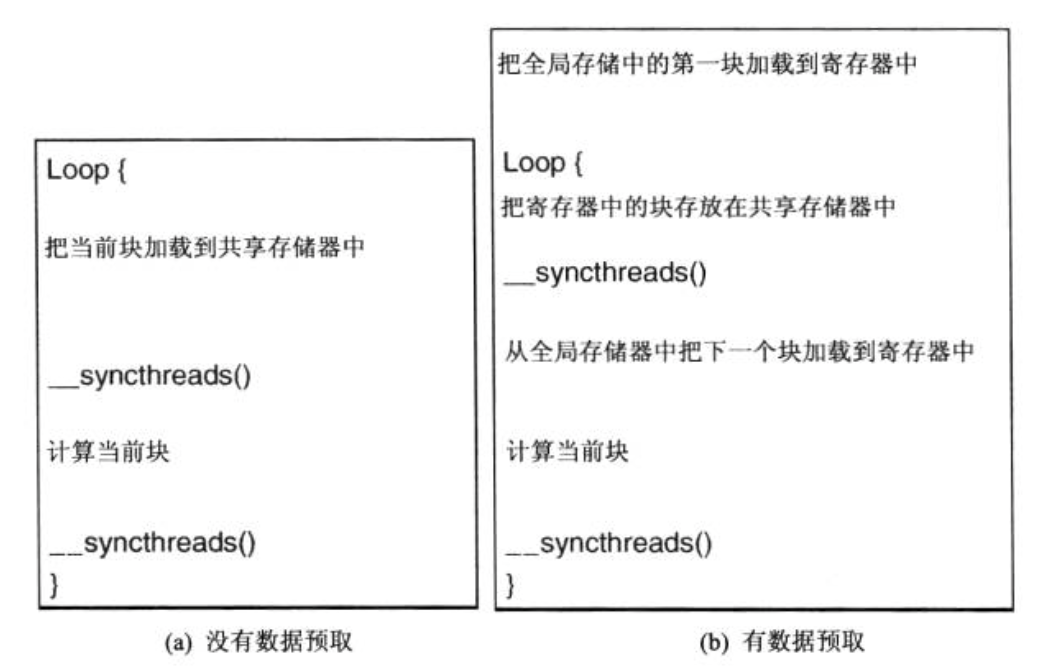
对应程序为
__global__ void kernel_prefetch(float* M, float* N, float* P){
int i;
float Pvalue = 0;
float Mc, Nc;
int Row = threadIdx.y + tile_width*blockIdx.y;
int Col = threadIdx.x + tile_width*blockIdx.x;
__shared__ float Mds[tile_width][tile_width];
__shared__ float Nds[tile_width][tile_width];
Mc = M[Row*width + threadIdx.x];
Nc = N[Col + threadIdx.y*width];
for (i = 1; i<width/tile_width+1; i++){
Mds[threadIdx.y][threadIdx.x] = Mc;
Nds[threadIdx.y][threadIdx.x] = Nc;
__syncthreads();
Mc = M[Row*width + threadIdx.x + i*tile_width];
Nc = N[Col + (threadIdx.y + i*tile_width)*width];
for (int k = 0; k<tile_width; k++){
Pvalue += Mds[threadIdx.y][k]*Nds[k][threadIdx.x];
}
__syncthreads();
}
P[Col + Row*width] = Pvalue;
}
Mc,Nc 为增加的两个储存在寄存器内的变量。
CUDA计算矩阵相乘的更多相关文章
- STL模板之_map,stack(计算矩阵相乘的次数)
#include <map>#include <stack>#include <iostream>using namespace std; struct Node ...
- Java实现矩阵相乘问题
1 问题描述 1.1实验题目 设M1和M2是两个n×n的矩阵,设计算法计算M1×M2 的乘积. 1.2实验目的 (1)提高应用蛮力法设计算法的技能: (2)深刻理解并掌握分治法的设计思想: (3)理解 ...
- CUDA编程-(2)其实写个矩阵相乘并不是那么难
程序代码及图解析: #include <iostream> #include "book.h" __global__ void add( int a, int b, i ...
- 编程计算2×3阶矩阵A和3×2阶矩阵B之积C。 矩阵相乘的基本方法是: 矩阵A的第i行的所有元素同矩阵B第j列的元素对应相乘, 并把相乘的结果相加,最终得到的值就是矩阵C的第i行第j列的值。 要求: (1)从键盘分别输入矩阵A和B, 输出乘积矩阵C (2) **输入提示信息为: 输入矩阵A之前提示:"Input 2*3 matrix a:\n" 输入矩阵B之前提示
编程计算2×3阶矩阵A和3×2阶矩阵B之积C. 矩阵相乘的基本方法是: 矩阵A的第i行的所有元素同矩阵B第j列的元素对应相乘, 并把相乘的结果相加,最终得到的值就是矩阵C的第i行第j列的值. 要求: ...
- cuda计算的分块
gpu的架构分为streaming multiprocessors 每个streaming multiprocessors(SM)又能分步骤执行很多threads,单个SM内部能同时执行的thread ...
- 利用Hadoop实现超大矩阵相乘之我见(二)
前文 在<利用Hadoop实现超大矩阵相乘之我见(一)>中我们所介绍的方法有着“计算过程中文件占用存储空间大”这个缺陷,本文中我们着重解决这个问题. 矩阵相乘计算思想 传统的矩阵相乘方法为 ...
- 利用Hadoop实现超大矩阵相乘之我见(一)
前记 最近,公司一位挺优秀的总务离职,欢送宴上,她对我说“你是一位挺优秀的程序员”,刚说完,立马道歉说“对不起,我说你是程序员是不是侮辱你了?”我挺诧异,程序员现在是很低端,很被人瞧不起的工作吗?或许 ...
- POJ 2246 Matrix Chain Multiplication(结构体+栈+模拟+矩阵相乘)
题意:给出矩阵相乘的表达式,让你计算需要的相乘次数,如果不能相乘,则输出error. 思路: 参考的网站连接:http://blog.csdn.net/wangjian8006/article/det ...
- MapReduce实现矩阵相乘
矩阵相乘能够查看百度百科的解释http://baike.baidu.com/view/2455255.htm?fr=aladdin 有a和b两个矩阵 a: 1 2 ...
随机推荐
- 【UE4 C++ 基础知识】<13> 多线程——TaskGraph
概述 TaskGraph 系统是UE4一套抽象的异步任务处理系统 TaskGraph 可以看作一种"基于任务的并行编程"设计思想下的实现 通过TaskGraph ,可以创建任意多线 ...
- 使用Servlet前Tomcat介绍
虚拟目录的映射方式:让tomcat服务器自动映射tomcat服务器会自动管理webapps目录下的所有web应用,并把它映射成虚似目录.换句话说,tomcat服务器webapps目录中的web应用,外 ...
- Java集合 - 集合知识点总结概述
集合概述 概念:对象的容器,定义了对多个对象进项操作的的常用方法.可实现数组的功能. 和数组的区别: 数组长度固定,集合长度不固定. 数组可以存储基本类型和引用类型,集合只能存储引用类型. 位置: j ...
- the Agiles Scrum Meeting 8
会议时间:2020.4.16 20:00 1.每个人的工作 今天已完成的工作 个人结对项目增量开发组:完成个人项目创建的部分功能 issues:增量组:准备评测机制,增加仓库自动创建和管理 团队项目增 ...
- 【二食堂】Beta - Scrum Meeting 3
Scrum Meeting 3 例会时间:5.15 18:30~18:50 进度情况 组员 当前进度 今日任务 李健 1. 继续完成文本区域划词添加的功能 issue 1. 划词功能已经实现,继续开发 ...
- 一文读懂Android进程及TCP动态心跳保活
一直以来,APP进程保活都是 各软件提供商 和 个人开发者 头疼的问题.毕竟一切的商业模式都建立在用户对APP的使用上,因此保证APP进程的唤醒,提升用户的使用时间,便是软件提供商和个人开发者的永恒追 ...
- Linux C 数据结构 ->单向链表
之前看到一篇单向链表的博文,代码也看着很舒服,于是乎记录下来,留给自己~,循序渐进,慢慢 延伸到真正的内核链表~(敢问路在何方?路在脚下~) 1. 简介 链表是Linux 内核中最简单,最普通的数据结 ...
- Shadertoy 教程 Part 2 - 圆和动画
Note: This series blog was translated from Nathan Vaughn's Shaders Language Tutorial and has been au ...
- Linux调整时区和同步时间
1.调整时区 tzselect 选择Asia -> China -> Beijing Time 2.设置为默认时区 cp -f /usr/share/zoneinfo/Asia/Shang ...
- DeWeb和WebXone的区别
DeWeb和WebXone的区别 相同点: 1 两者为同一开发者研发.QQ:45300355,碧树西风 2 都是为了解决Delphi开发Web的问题 区别: 1 WebXone采用的ActiveX/N ...