redis实例cpu占用率过高问题优化
一.简介
前情提要:
最近接了大数据项目的postgresql运维,刚接过来他们的报表系统就出现高峰期访问不了的问题,报表涉及实时数据和离线数据,离线读pg,实时读redis。然后自然而然就把redis也挪到我们这边优化了 -_-! 。在这次优化过程中也是再次深刻感受到redis的各种坑
现象:
大数据报表周末晚上高峰期实时报表打不开,基本上处于不能使用状态,实时报表主要访问redis数据,监控发现Redis CPU占用过高,高峰期2个从库实例的CPU达到100%,由于redis是单进程单线程结构,所以单核CPU达到100%导致查询阻塞
当前架构:
1主1从 ,应用手动读写分离,持久化主从默认都开启开启rdb持久化,没有做aof,参数基本走默认(灰常牛批 -_-!)
问题导致原因排查:
- redis持久化导致阻塞
- 是否存在慢查询
- 主从存在频繁全量同步)
- value值是否过大
- 架构问题,当前所有业务读取仅在一个从库读取
- 网络问题
- 连接数问题
好了,整理出一大堆问题之后,开始各种分析:
首先看的网络问题,跟运维小伙伴沟通过,结合监控结果发现,网络基本上没有问题,网卡流量也远远没有到瓶颈,首先排除网络问题。但是,在redis从库的日志中,发现有个报错很频繁:
47960:S 16 Apr 12:05:36.951 #Connection with master lost.
47960:S 16 Apr 12:05:36.951 * Caching the disconnected master state.
47960:S 16 Apr 12:05:37.799 * Connecting to MASTER 192.168.63.2:6379
47960:S 16 Apr 12:05:37.799 * MASTER <-> SLAVE sync started
47960:S 16 Apr 12:05:37.799 * Non blocking connect for SYNC fired the event.
47960:S 16 Apr 12:05:42.871 * Master replied to PING, replication can continue...
47960:S 16 Apr 12:05:42.873 *Trying a partial resynchronization(request 2cf6338d2d3a72131d5f2f18a0bd8c271302e058:228189063173).
47960:S 16 Apr 12:05:43.085 *Full resync from master:2cf6338d2d3a72131d5f2f18a0bd8c271302e058:228814173990
47960:S 16 Apr 12:05:43.085 * Discarding previously cached master state.
看字面意思就是主从连接断开了,从库尝试做增量同步还不成功,最后做了全量同步。
WTF???既然网络没问题,为什么连接断了。OK,引出主从问题
主从出现了频繁全量同步,如上面的日志显示,从库连接断开从连并尝试增量同步失败,结果做了全量同步。这个操作开销很大:主库bgsave->传到从库->从库加载rbd到内存(加载的时候是无法操作redis的)。出现这种情况又有几个原因。。。
replication backlog(master端):用于保存主从同步数据的一块内存缓冲区域(所有客户端共享该内存),达到限制将会重新进行全量同步,这部分内存会包含在used_memory_human中,设置值参考bgrewrite所需的内存RDB: 500 MB of memory used by copy-on-write
通过增大repl-backlog-size解决
replication buffer(master端):redis每个连接都分配了自己的缓冲区空间(从库也相当于是一个客户端连接)。处理完请求后,redis把响应数据放到缓冲区中,然后继续下一个请求。repl-buffer存放的数据是下面3个时间内所有master数据更新操作,设置值参考:每秒的命令产生大小*(以下3个时间之和)
master执行rdb bgsave产生snapshot的时间
master发送rdb到slave网络传输时间
slave load rdb to memory 的时间
主要参数:
client-output-buffer-limit normal
client-output-buffer-limit slave
client-output-buffer-limit pubsub
复制超时:
repl-timeout
最终参数优化调整如下(主库):
repl-backlog-size 512mb
repl-timeout 120
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 0 0 0
client-output-buffer-limit pubsub 32mb 8mb 60
架构问题,其实早在报表高峰期读取问题出现的初期,大数据的同事就提出增加redis从库实例,做负载均衡的想法了。鉴于redis是单线程模型,只能用到一个cpu核心,多增加几个实例可以多利用到几个cpu核心这个想法确实也没错。当时由于从库物理机有富余的内存资源,所以临时新增了三个从库实例,并添加haproxy轮询访问后端4个redis实例。整体架构变为1主4从+haproxy做从库负载均衡。但是我始终认为,cpu高主要还是跟具体的业务查询有关,架构扩展应该是在单实例优化到最佳之后才考虑的。这就好比在mysql当中,有大量慢查询导致cpu过高,你光靠扩展从库而不去先优化SQL,扩展到什么时候是个头呢?
慢查询问题:某个促销活动的晚上,大数据报表果然又准时出现打开慢的现象。redis依然是cpu占用率爆满。话不多说进入redis ,slowlog get 50 , 发现慢查询中基本都是keys xxx* 这样的查询,这。。。我几乎肯定cpu占用率跟这种慢查询有很大关系了。执行时间在0.5秒左右,0.5秒对于redis来说应该是非常慢了。如果这样的查询比较多的话,那么redis确实很可能出现阻塞,在看了下value值的大小,应该还好不算大。redis slowlog默认只保存在内存,只保留当前的128条,所以这也算是个小小的麻烦,不太好统计慢查询发生的频率
持久化策略:
rdb持久化:每次都是全量的bgsave,具体策略下面说。
缺点:
1、非实时
2、全量持久化
3、每次保存RDB的时候,Redis都要fork()出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时,fork()可能会非常耗时,造成服务器在某某毫秒内停止处理客户端
aof持久化:每秒写aof文件,实时性较高,增量写,顺序记录语句,便于误操作恢复
缺点:
1、bgrewrite重写,fork进程,短暂阻塞
2、重写时fork进程可能导致swap和OOM(预留1半内存)
简单介绍完两种持久化策略之后,最后给出我实际优化后的策略:
主/从业务库关闭rdb和aof持久化,新增一台从库(不参与业务)单独做rdb持久化,该从库持久化配置:save 900 1 也就是900秒做一次bgrewrite,最多丢失15分钟数据
连接数问题,这块目前来说由于做了负载均衡,高峰期看haproxy入口的连接最大也就去到500-600,还是有阻塞的情况下,每个redis实例connected_clients最多也就到100左右,排除连接数的问题
结论:优化主要避免了持久化,以及频繁主从全量同步带来的性能影响。但是实际主要瓶颈还是在慢查询,如果keys xxx*这种查询不能避免,那么一定会造成阻塞
下面这张图应该更加生动:

最后,还有几个待解决的问题记录下:
1、主库的used_memory_peak_human达到60.97G,实际上主库的maxmemory只配置了32G
127.0.0.1:6379> info memory
# Memory
used_memory:3531621728
used_memory_human:3.29G
used_memory_rss:70885924864
used_memory_peak:65461144384
used_memory_peak_human:60.97G
used_memory_lua:36864
mem_fragmentation_ratio:20.07
mem_allocator:libc
解决方式:内存碎片造成,查看资料说是大量写入造成,目前没有太好的解决方法,只能通过重启进程释放
2、redis过期的key会不会自动删除?策略如何配置
redis过期的key当内存使用maxmemory才会进行删除
maxmemory-policy 六种方式:
volatile-lru:(默认值)从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
volatile-ttl : 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
allkeys-lru : 从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
noeviction : 禁止驱逐数据,永不过期,返回错误
3、redis主从同步原理(全量/增量)
一张图一目了然:
复制积压缓冲区=repl-backlog
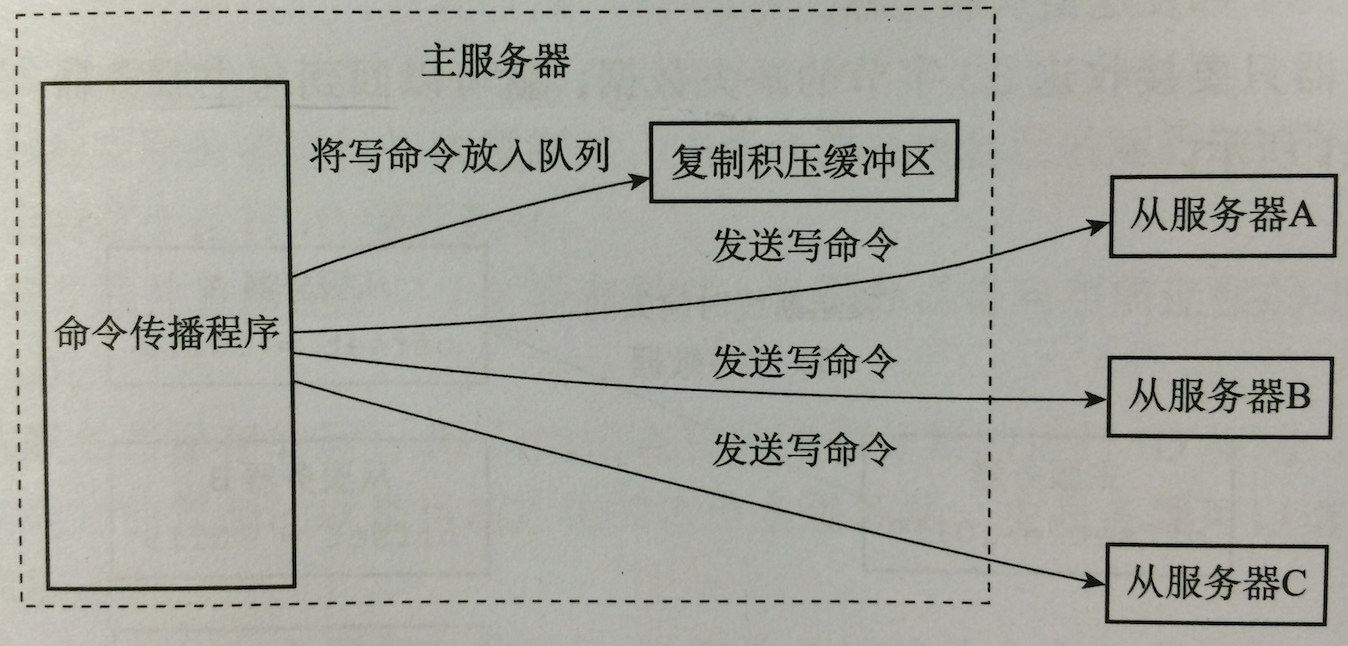
redis2.8之前不支持增量备份
增量备份的两个条件
slave带来的runid是否当前master的runid
slave带来的复制offset在master的backlog(复制积压缓冲区)中还能否找到
redis实例cpu占用率过高问题优化的更多相关文章
- 一次线上redis实例cpu占用率过高问题优化(转)
前情提要: 最近接了大数据项目的postgresql运维,刚接过来他们的报表系统就出现高峰期访问不了的问题,报表涉及实时数据和离线数据,离线读pg,实时读redis.然后自然而然就把redis也挪到我 ...
- Windows CPU占用率过高
今天调试程序,发现Windows7的CPU占用率一直为25%左右,如下图所示.四核25%,换成单核那就是100%的占用率了! 上图进入"进程"页面,单击"CPU" ...
- 云服务器 ECS Linux 系统 CPU 占用率较高问题排查思路
https://help.aliyun.com/knowledge_detail/41225.html?spm=5176.7841174.2.2.ifP9Sc 注意:本文相关配置及说明已在 CentO ...
- 使用jstack分析java程序cpu占用率过高
在项目中经常会碰到CPU占用率过高的问题,那么碰到这类问题应当如何处理呢?下面提供一种处理思路: 首先top -H -p <pid>以线程的模式查看java应用的运行情况,找到占用cpu或 ...
- 线上Java程序导致服务器CPU占用率过高的问题排除过程
博文转至:http://www.jianshu.com/p/3667157d63bb,博文更好效果看原版,转本博文的目的就算是个书签吧,需要时候可以定位原文学习 1.故障现象 客服同事反馈平台系统运行 ...
- 记一次线上Java程序导致服务器CPU占用率过高的问题排除过程
博文转至:http://www.jianshu.com/p/3667157d63bb,转本博文的目的就是需要的时候以防忘记 1.故障现象 客服同事反馈平台系统运行缓慢,网页卡顿严重,多次重启系统后问题 ...
- zprofiler三板斧解决cpu占用率过高问题(转载)
zprofiler三板斧解决cpu占用率过高问题 九居 JVM性能与调试平台 zprofiler 上周五碰到了一个线上机器cpu占用率过高的问题.问题本身比较简单,但是定位过程中动用了多个zp ...
- zprofiler三板斧解决cpu占用率过高问题
zprofiler三板斧解决cpu占用率过高问题 九居 浏览 171 2015-04-08 14:11:58 发表于:JVM性能与调试平台 zprofiler 上周五碰到了一个线上机器cpu ...
- Java内存、CPU占用率过高
windows下揪出java程序占用cpu很高的线程 并找到问题代码 死循环线程代码 linux下查找java进程占用CPU过高原因 Java 占用CPU使用率很高的分析 记一次线上Java程序导致服 ...
随机推荐
- webpack--初试webpack( 核心、体验、资源打包)
前言 webpack是当前前端项目中最常用的资源构建工具,从本文开始,来总结记录一下关于webpack的学习. 正文 1.webpack简介 webpack官网(https://webpack.doc ...
- [hdu7044]Fall with Fake Problem
二分$T$和$S$第一个不同的位置,即需要对于$s$,判定是否存在$T[1,s]=S[1,s]$且满足条件的$T$ (注:这里的 ...
- [bzoj1483]梦幻布丁
对于每一个颜色用一个链表存储,并记录下:1.当前某种颜色的真实颜色:2.这种颜色的数量(用于启发式合并的判断):3.当前答案(即有几段),然后对于每一个操作简单处理一下就行了. 1 #include& ...
- 【Vue.js】SPA
SPA 2019-11-13 23:20:48 by冲冲 1.概念 (1)MPA(multi-page application) 特点:每一次页面跳转的时候,后台服务器都会返回一个新的html文档 ...
- git分支切换的一些问题
关于git切换分支后该分支的修改会在另一个分支里面一起修改的问题 修改分支后导致稳定版的主分支里面的文件连带修改. 原因:切换分支前原分支没有提交,导致新建的文件或者文件夹,没有纳入版本管理,所以会被 ...
- linux命令-压缩数据
linux文件压缩工具:bzip2 文件扩展名 .bz2 compress 文件扩展名 .Z linux上很少看到了 uncompress解压 gzip 文件扩展名,.gz,gzip压缩文件,gzca ...
- 关于 KB/KiB、MB/MiB
ermmm--怎么说呢,这个非常容易搞混,那就写篇 blog 澄清一下吧-- 首先贴上百度百科的官方定义 根据国际单位制标准,1KB = 1000B(字节, Byte). 根据按照 IEC 命名标准 ...
- 富集分析DAVID、Metascape、Enrichr、ClueGO
前言 一般我们挑出一堆感兴趣的基因想临时看看它们的功能,需要做个富集分析.虽然公司买了最新版的数据库,如KEGG,但在集群跑下来嫌麻烦.这时网页在线或者本地化工具派上用场了. DAVID DAVID地 ...
- miRNA分析--比对(二)
miRNA分析--数据过滤(一) 在比对之前为了减少比对时间,将每一个样本中的reads进行合并,得到fasta格式,其命名规则如下: 样本_r数子_x数字 r 中的数字表示reads序号: x 中的 ...
- Nginx nginx: [emerg] using regex "\.php$" requires PCRE library 或 编译nginx错误:make[1]: *** [/pcre//Makefile] Error 127
nginx: [emerg] using regex "\.php$" requires PCRE library 或 编译nginx错误:make[1]: *** [/pcre ...