hadoop2.5.2 安装与部署
主从机构
主:jobtracker
从:tasktracker
四个阶段
1、 split
2、 Mapper: key-value(对象)
3、 shuffle
a) 分区(partition,HashPartition:根据 key 的 hashcode值 和 Reduce 的数量 模运算),可以自定义分区,运算速度要快,一定要解决数据倾斜和reduce
的负载均衡。
b) 排序: 默认按照字典排序。WriterCompartor(比较)
c) 合并:减少当前mapper输出数据,根据key相同(比较),把value进行合并。
d) 分组(key相同(比较),value组成一个集合)(merge)
4、Reduce
a) 输入数据: key +迭代器
Hadoop2.5 HA 搭建
四台机器:hadoop1, hadoop2, hadoop3, hadoop4
|
NN |
DN |
ZK |
ZKFC |
JN |
RM |
NM(任务管理器) |
|
|
hadoop1 |
Y |
Y |
Y |
Y |
|||
|
hadoop2 |
Y |
Y |
Y |
Y |
Y |
Y |
|
|
hadoop3 |
Y |
Y |
Y |
Y |
|||
|
hadoop4 |
Y |
Y |
Y |
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bjsxt</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.200.128:2181,192.168.200.4:2181,192.168.200.5:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.5.2</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>bjsxt</value>
</property>
<property>
<name>dfs.ha.namenodes.bjsxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn1</name>
<value>192.168.200.128:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn2</name>
<value>192.168.200.4:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn1</name>
<value>192.168.200.128:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn2</name>
<value>192.168.200.4:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.200.4:8485;192.168.200.5:8485;192.168.200.6:8485/bjsxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.bjsxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/jn/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
- 准备 zookeeper
a) 三台 zookeeper: hadoop1, hadoop2, hadoop3
b) 编辑 zoo.cfg 配置文件
- 修改 dataDir=/opt/zookeeper
- server.1=192.168.200.128:2888:3888
server.2=192.168.200.4:2888:3888
server.3=192.168.200.5:2888:3888
c) 在dataDir目录中创建一个myid的文件,文件内容1,2,3
- 配置 hadoop中的slaves
- 启动三个zookeeper: ./zkServer.sh start
- 启动三个journalNode: ./Hadoop-daemon.sh start journalnode
- 在其中一个namenode上格式化: hdfs namenode –format
- 把刚刚格式化之后的元数据拷贝到另外 一个namenode上
a) 启动刚刚格式化的namenode
b) 在没有格式化的namenode上执行:hdfs namenode –bootstrapStandby
c) 启动第二个namenode
9. 在其中一个namenode上初始化 zkfc:hdfs zkfc –formatZK
10. 停止上面节点:stop-dfs.sh
11. 全面启动: start-dfs.sh 配置mapreduce
1>修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2> 修改yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3> 启动
./start-yarn.sh
访问路径
hadoop2.2.5mapreduce的web界面 http://192.168.200.128:8088/
hdfs web界面 http://192.168.200.128:50070/
手动切换命令
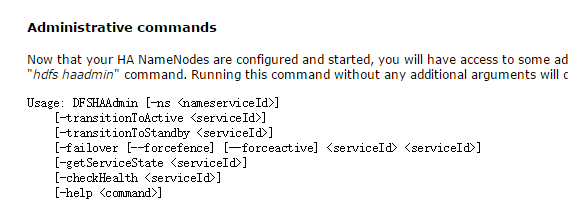
- transitionToActiove <serviceId> // serviceId指 nn1,nn2
建立输入文件目录
./hdfs dfs -mkdir -p /usr/input/hot
删除文件目录
./hdfs dfs -rm /usr/input/hot
上传文件到输入目录
./hdfs dfs -put /usr/data /usr/input/hot
查看目录下文件
./hdfs dfs -ls /usr/input/hot
./hadoop jar /usr/local/hadoop2.jar RunJob
hadoop2.5.2 安装与部署的更多相关文章
- hadoop2.7.1安装和部署
操作系统:Red Hat Enterprise Linux Server release 6.2 (Santiago) hadoop2.7.1 三台redhat linux主机,ip分别为10.204 ...
- hadoop2.5.2安装部署
0x00 说明 此处已经省略基本配置步骤参考Hadoop1.0.3环境搭建流程,省略主要步骤有: 建立一般用户 关闭防火墙和SELinux 网络配置 0x01 配置master免密钥登录slave 生 ...
- Apache Hadoop2.x 边安装边入门
完整PDF版本:<Apache Hadoop2.x边安装边入门> 目录 第一部分:Linux环境安装 第一步.配置Vmware NAT网络 一. Vmware网络模式介绍 二. NAT模式 ...
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- Hadoop第3周练习--Hadoop2.X编译安装和实验
作业题目 位系统下进行本地编译的安装方式 选2 (1) 能否给web监控界面加上安全机制,怎样实现?抓图过程 (2)模拟namenode崩溃,例如将name目录的内容全部删除,然后通过secondar ...
- Hive安装与部署集成mysql
前提条件: 1.一台配置好hadoop环境的虚拟机.hadoop环境搭建教程:稍后补充 2.存在hadoop账户.不存在的可以新建hadoop账户安装配置hadoop. 安装教程: 一.Mysql安装 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hue的安装与部署
Hue的安装与部署 hadoop hue Hue 简介 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是 ...
- hadoop2.4.1伪分布模式部署
hadoop2.4.1伪分布模式部署 (承接上一篇hadoop2.4.1-src的编译安装继续配置:http://www.cnblogs.com/wrencai/p/3897438.html) 感谢: ...
随机推荐
- Retrofit2.2说明-简单使用
很久前就想学习下Retrofit了,不过总是没有时间,正好最近新项目要用到网络请求,正好研究了下Retrofit2.2的简单使用方法,大致记录如下: Retrofit与okhttp共同出自于Squar ...
- Python基础(10)_内置函数、匿名函数、递归
一.内置函数 1.数学运算类 abs:求数值的绝对值 divmod:返回两个数值的商和余数,可用于计算页面数 >>> divmod(5,2) (2, 1) max:返回可迭代对象中的 ...
- Linux基础系列:常用命令(3)
作业一: ) 将用户信息数据库文件和组信息数据库文件纵向合并为一个文件/.txt(覆盖) cat /etc/passwd /etc/group > /test/.txt ) 将用户信息数据库文件 ...
- Video标签的使用
现在如果要在页面中使用video标签,需要考虑三种情况,支持Ogg Theora或者VP8(如果这玩意儿没出事的话)的(Opera.Mozilla.Chrome),支持H.264的(Safari.IE ...
- HackerRank - maximum-perimeter-triangle 【水】
题意 给出一系列数字,判断其中哪三个数字可以构成一个三角形,如果有多个,输出周长最大的那个,如果没有输出 - 1 思路 数据较小,所有情况FOR一遍 判断一下 AC代码 #include <cs ...
- 计算机网络概述 传输层 TCP流量控制
TCP流量控制 所谓流量控制就是让发送发送速率不要过快,让接收方来得及接收.利用滑动窗口机制就可以实施流量控制.通过运用TCP报文段中的窗口大小字段来控制,发送方的发送窗口不可以大于接收方发回的窗口大 ...
- mysql sql的执行顺序
转:http://blog.csdn.net/u014044812/article/details/51004754 关于sql和MySQL的语句执行顺序(必看!!!) 原创 2016年03月29日 ...
- Shell编程之Linux信号及信号跟踪
一.Linux信号 1.什么是信号? Linux信号是由一个整数构成的异步消息,它可以由某个进程发给其他进程,也可以在用户按下特定键发生某种异常事件时,由系统发给某个进程. 2.信号列表 [root@ ...
- 对正交频分复用OFDM系统的理解
OFDM系统 正交频分复用OFDM(Orthogonal Frenquency Division Multiplexing)是一种多载波调制技术. 基本思想:在发送端,它将高速串行数据经过串并变换形成 ...
- Myeclipse 快捷键使用
MyEclipse快捷键大全-------------------------------------MyEclipse 快捷键1(CTRL)----------------------------- ...