hadoop2.5.2 安装与部署
主从机构
主:jobtracker
从:tasktracker
四个阶段
1、 split
2、 Mapper: key-value(对象)
3、 shuffle
a) 分区(partition,HashPartition:根据 key 的 hashcode值 和 Reduce 的数量 模运算),可以自定义分区,运算速度要快,一定要解决数据倾斜和reduce
的负载均衡。
b) 排序: 默认按照字典排序。WriterCompartor(比较)
c) 合并:减少当前mapper输出数据,根据key相同(比较),把value进行合并。
d) 分组(key相同(比较),value组成一个集合)(merge)
4、Reduce
a) 输入数据: key +迭代器
Hadoop2.5 HA 搭建
四台机器:hadoop1, hadoop2, hadoop3, hadoop4
|
NN |
DN |
ZK |
ZKFC |
JN |
RM |
NM(任务管理器) |
|
|
hadoop1 |
Y |
Y |
Y |
Y |
|||
|
hadoop2 |
Y |
Y |
Y |
Y |
Y |
Y |
|
|
hadoop3 |
Y |
Y |
Y |
Y |
|||
|
hadoop4 |
Y |
Y |
Y |
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bjsxt</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.200.128:2181,192.168.200.4:2181,192.168.200.5:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.5.2</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>bjsxt</value>
</property>
<property>
<name>dfs.ha.namenodes.bjsxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn1</name>
<value>192.168.200.128:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn2</name>
<value>192.168.200.4:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn1</name>
<value>192.168.200.128:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn2</name>
<value>192.168.200.4:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.200.4:8485;192.168.200.5:8485;192.168.200.6:8485/bjsxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.bjsxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/jn/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
- 准备 zookeeper
a) 三台 zookeeper: hadoop1, hadoop2, hadoop3
b) 编辑 zoo.cfg 配置文件
- 修改 dataDir=/opt/zookeeper
- server.1=192.168.200.128:2888:3888
server.2=192.168.200.4:2888:3888
server.3=192.168.200.5:2888:3888
c) 在dataDir目录中创建一个myid的文件,文件内容1,2,3
- 配置 hadoop中的slaves
- 启动三个zookeeper: ./zkServer.sh start
- 启动三个journalNode: ./Hadoop-daemon.sh start journalnode
- 在其中一个namenode上格式化: hdfs namenode –format
- 把刚刚格式化之后的元数据拷贝到另外 一个namenode上
a) 启动刚刚格式化的namenode
b) 在没有格式化的namenode上执行:hdfs namenode –bootstrapStandby
c) 启动第二个namenode
9. 在其中一个namenode上初始化 zkfc:hdfs zkfc –formatZK
10. 停止上面节点:stop-dfs.sh
11. 全面启动: start-dfs.sh 配置mapreduce
1>修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2> 修改yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3> 启动
./start-yarn.sh
访问路径
hadoop2.2.5mapreduce的web界面 http://192.168.200.128:8088/
hdfs web界面 http://192.168.200.128:50070/
手动切换命令
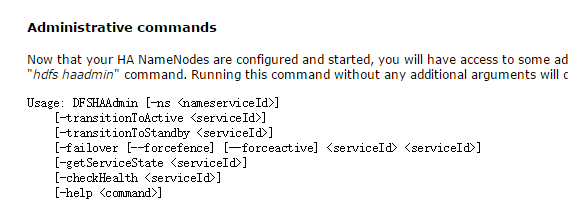
- transitionToActiove <serviceId> // serviceId指 nn1,nn2
建立输入文件目录
./hdfs dfs -mkdir -p /usr/input/hot
删除文件目录
./hdfs dfs -rm /usr/input/hot
上传文件到输入目录
./hdfs dfs -put /usr/data /usr/input/hot
查看目录下文件
./hdfs dfs -ls /usr/input/hot
./hadoop jar /usr/local/hadoop2.jar RunJob
hadoop2.5.2 安装与部署的更多相关文章
- hadoop2.7.1安装和部署
操作系统:Red Hat Enterprise Linux Server release 6.2 (Santiago) hadoop2.7.1 三台redhat linux主机,ip分别为10.204 ...
- hadoop2.5.2安装部署
0x00 说明 此处已经省略基本配置步骤参考Hadoop1.0.3环境搭建流程,省略主要步骤有: 建立一般用户 关闭防火墙和SELinux 网络配置 0x01 配置master免密钥登录slave 生 ...
- Apache Hadoop2.x 边安装边入门
完整PDF版本:<Apache Hadoop2.x边安装边入门> 目录 第一部分:Linux环境安装 第一步.配置Vmware NAT网络 一. Vmware网络模式介绍 二. NAT模式 ...
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- Hadoop第3周练习--Hadoop2.X编译安装和实验
作业题目 位系统下进行本地编译的安装方式 选2 (1) 能否给web监控界面加上安全机制,怎样实现?抓图过程 (2)模拟namenode崩溃,例如将name目录的内容全部删除,然后通过secondar ...
- Hive安装与部署集成mysql
前提条件: 1.一台配置好hadoop环境的虚拟机.hadoop环境搭建教程:稍后补充 2.存在hadoop账户.不存在的可以新建hadoop账户安装配置hadoop. 安装教程: 一.Mysql安装 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hue的安装与部署
Hue的安装与部署 hadoop hue Hue 简介 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是 ...
- hadoop2.4.1伪分布模式部署
hadoop2.4.1伪分布模式部署 (承接上一篇hadoop2.4.1-src的编译安装继续配置:http://www.cnblogs.com/wrencai/p/3897438.html) 感谢: ...
随机推荐
- 016-Hadoop Hive sql语法详解6-job输入输出优化、数据剪裁、减少job数、动态分区
一.job输入输出优化 善用muti-insert.union all,不同表的union all相当于multiple inputs,同一个表的union all,相当map一次输出多条 示例 二. ...
- 如何高效地分析Android_log中的问题?——查看Android源码
在日常解bugs时,需要通过log日志来分析问题,例如查看crash发生时的堆栈信息时,就会有Android的源码的调用,这是就要去查看Android源码. 1.进入Android源码网址查看,例如 ...
- pyhton3 logging模块
1.简单的将日志打印到屏幕 import logging logging.debug('This is debug message')logging.info('This is info mess ...
- ajax数据请求的理解
一,请求 发送请求有两种方式:get 跟 post . 1.get仅请求数据,不需要服务端做处理,最后会返回指定的资源. 2.post可以提交数据,服务端根据提交的数据做处理,再返回数据. 二,创建X ...
- WEB网页专业词汇 汇总
Accessibility 可访问性 accessor properties 存取器属性 addition 加法 aggregate 聚合 alphabetical order 字母表顺序 Anch ...
- css小知识---input输入块
对于如下的界面,介绍一种实现方式. 可以将整个界面分为三块,左中右.通过display: inline-block;和float: right;左右浮动效果实现. 代码如下: <!DOCTYPE ...
- hadoop05---进程线程
J2ee是一种规范,tomcat.jboss.weblogic就是实现.JMS是一种规范,ActiveMQ是实现. .1.1. 进程介绍.线程介绍 进程:它是内存中的一段独立的内存空间. 线程:是在进 ...
- FullPage.js全屏滚动插件
一.介绍 fullPage.js是一个基于jQuery的插件,他能够很方便.很轻松的制作出全屏网站,主要功能有: 1.支持鼠标滚动 2.多个回调函数 3.支持手机.平板触摸事件 4.支持CSS3动画 ...
- Plist文件与数据解析
综述 初步阶段当我们做个需要点数据的练习时(比如购物商品展示),我们可能是将数据直接写在代码中,比如说定义一个字符串数组或存放字典的数组.但这其实并不是一种合理的做法.因为如果当数据修改的时候,就要经 ...
- 【P1886】滑动窗口(单调队列→线段树→LCT)
这个题很友好,我们可以分别进行简单难度,中等难度,恶心难度来做.然而智商没问题的话肯定是用单调队列来做... 板子题,直接裸的单调队列就能过. #include<iostream> #in ...